Online Judge(OJ)搭建——2、数据库,SQL语句
数据库EER图
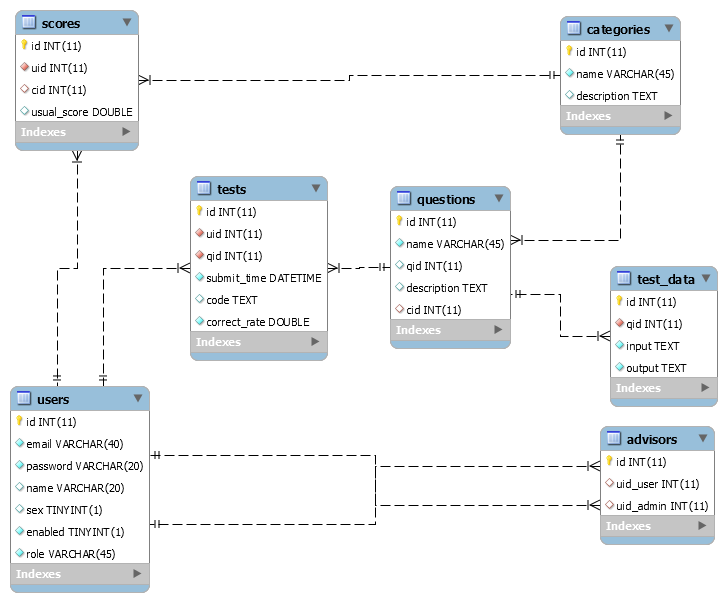
数据库表、字段、约束解释
users 用户:
id 标识符,email 邮箱,password 密码,name 姓名,sex 性别,enabled 启用 ,role 角色
id primary key
advisors 指导:
id 标识符,uid_user 被指导者,uid_admin 指导者
id primary key
uid_user -> user(id),uid_admin(id)
categories 类别:
id 标识符,name 名称,description 描述
id primary key
questions 问题:
id 标识符,qid 题号,description 描述,cid 类别标识符,name 名称
id primary key
cid -> categories(id)
test_data 测试数据:
id 标识符,qid 题号,input 一组输入,output 一组输出
id primary key
qid -> questions(id)
tests 测试信息:
id 标识符,uid 用户标识符,qid 题号,submit_time 提交时间,code 代码,correct_rate 正确率
id primary key
uid -> users(id),qid -> questions(id)
scores 成绩:
id 标识符,uid 用户标识符,cid 类别标识符,usual_score 平时成绩
复杂SQL语句
selectSumScoreAndRank:
功能:根据用户 ID,查询用户 ID、用户所有题目总成绩、总成绩的排名。
实现:主要是利用了聚集函数,MySQL 自带 @rowNum 属性。
代码:
SELECT *
FROM
(SELECT
uid,
sum_correct_rate,
(@rowNum := @rowNum + 1) AS rank
FROM (SELECT
uid,
sum(max_corrcet_rate) AS sum_correct_rate
FROM
(SELECT
uid,
qid,
max(correct_rate) AS max_corrcet_rate
FROM tests
GROUP BY uid, qid) AS max_tests
GROUP BY uid
ORDER BY sum_correct_rate DESC) AS rank_tests, (SELECT (@rowNum := 0)) AS rank) AS all_tests
WHERE uid = #{uid}
selectPracticeAndUsualScoreFromAdmin:
功能:根据管理员 ID 和类别 ID,查询特定管理员的指导关系下用户的实践成绩和平时成绩。
实现:首先根据指导关系下的用户 ID 和特定题库 ID 选出特定题目,再根据特定题目选出特定测试,最后利用聚集函数进行成绩整合(例如,聚集函数 sum 计算特定用户特定题库下的总分)。
代码:
SELECT
scores.id,
scores.uid,
users.email,
users.name AS userName,
sum_tests.avg_correct_rate * 100 AS practice_score,
scores.usual_score
FROM
(SELECT
uid,
avg(max_corrcet_rate) AS avg_correct_rate
FROM
(SELECT
uid,
qid,
max(correct_rate) AS max_corrcet_rate
FROM (SELECT
uid,
qid,
correct_rate
FROM tests
WHERE
uid IN (SELECT uid_user
FROM advisors
WHERE uid_admin = #{uidAdmin}) AND qid IN (SELECT questions.id
FROM categories
LEFT JOIN questions
ON categories.id = questions.cid
WHERE cid = #{cid})
) AS filter_tests
GROUP BY uid, qid) AS max_tests
GROUP BY uid) AS sum_tests LEFT JOIN scores ON sum_tests.uid = scores.uid AND scores.cid = #{cid} LEFT JOIN users ON sum_tests.uid = users.id
设计思想
1、为什么要每张表都有 ID,并且把 ID 作为主键?
表的主键不应该可以变动的,而现实中的需求会变动。起初,表 questions 是没有列 cid 的,后来为了模拟现实中题目(questions)的类别(categories), 增加了 cid 列。
假设有一种情况:
类别名(categories name)为 Java,题号(qid)为 1,2,3;类别为 C#,题号为1,2,3。
如果表 questions 以 qid 作为主键,上述的情况是无法实现的,因为primary key 违反了唯一性约束,需要重新设计架构;如果表 questions 以无意义的 id 作为主键,上述情况实现很简单,不需要变动架构。
所以,表的主键最好是无意义的id。
2、表 questions 和表 test_data 的设计
表 questions 起初和 test_data 是放在一起的,即 input 和 output 起初是在表 questions 中的,并且每条记录表示的多组输入和多组输出。后来我剥离了,并且将每条记录由多组输入和多组输出变为一组输入和一组输出,原因如下:
① 多组的输入或者多组的输出不方便保存。如果合并为一组保存,必须以一个符号作为分隔符,然而在 OJ 系统,任何符号的输入都是有可能的,分隔符无法选择
② 如果采用多组保存,冗余性较高,qid、name等多保存了很多次。
所以,我采取弱关联(将多值属性剥离,新建一个表存入,新表高度依赖于原来的表)来保存。
Online Judge(OJ)搭建——2、数据库,SQL语句的更多相关文章
- 学生选课数据库SQL语句45道练习题整理及mysql常用函数(20161019)
学生选课数据库SQL语句45道练习题: 一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四 ...
- MySQL 数据库SQL语句——高阶版本2
MySQL 数据库SQL语句--高阶版本2 实验准备 数据库表配置: mysql -uroot -p show databases; create database train_ticket; use ...
- MySQL 数据库SQL语句——高阶版本1
MySQL 数据库SQL语句--高阶版本 实验准备,数据表配置 mysql -uroot -p show databases; create database train_ticket; use tr ...
- SQL Server数据库sql语句生成器(SqlDataToScript)的使用(sql server自增列(id)插入固定值)
SqlDataToScript是根据表数据进行生成 Insert Into语句,此工具还有一个好处是可以对自增列插入固定值,例如:自增的列id值为5,但是5这个行值已经删除,如果想存储Id自增列值为5 ...
- ORACLE数据库SQL语句的执行过程
SQL语句在数据库中处理过程是怎样的呢?执行顺序呢?在回答这个问题前,我们先来回顾一下:在ORACLE数据库系统架构下,SQL语句由用户进程产生,然后传到相对应的服务端进程,之后由服务器进程执行该SQ ...
- 数据库SQL语句练习题
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表( ...
- mySQL数据库Sql语句执行效率检查--Explain命令
mysql性能的检查和调优方法 Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的 ...
- 数据库—SQL语句
下列语句部分是Mssql语句,不可以在access中使用. SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DEL ...
- 学生选课系统数据库SQL语句考试题
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表( ...
- 数据库 数据库SQL语句五
集合运算 union 并集(两个集合如果有重复部分,那么只显示一次重复部分) union all 并集(两个集合如果有重复部分,那么重复部分显示两次) intersect 交集 minus 差集 -- ...
随机推荐
- CodeForces - 796A Buying A House
思路:从m直接向两边枚举,如果当前点需要的费用小于等于k,说明一定是最近距离. AC代码 #include <cstdio> #include <cmath> #include ...
- 算法提高 金陵十三钗 状压DP
思路:深度搜索复杂度N!过不了.考虑动态规划:将已经选择的列记为1,未选择表示0,二进制压缩,例如110,就表示选择了第1列和第2列. d(i, t)表示当前已经匹配了i行,选择了t这些列.状态转移: ...
- mysql忘记密码解决的办法
[很管用]忘记mysql root密码解决办法 1.编辑MySQL配置文件: 首先停止mysql服务, 然后开始编辑mysql配置文件:vi /etc/my.cnf在[mysqld]配置段添加如下一行 ...
- Redis持久化存储
Redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化.redis支持四种持久化方式,一是 Snapshotting(快照)也是默认方式:二是Appen ...
- Spark SQL1.2测试
Spark SQL 1.2 运行原理 case class方式 json文件方式 背景:了解到HDP也能够支持Spark SQL,但官方文档是版本1.2,希望支持传统数据库.hadoop平台.文本格式 ...
- iOS.Animations.by.Tutorials.v2.0汉化(二)
翻译自:iOS.Animations.by.Tutorials.v2.0 第一节(第1章) 动画属性 现在你已经看到了动画是多么的简单,你可能很想知道你的视图控件是怎么动起来的.本节将给你一个UIVi ...
- 实战DeviceIoControl 之四:获取硬盘的详细信息
Q 用IOCTL_DISK_GET_DRIVE_GEOMETRY或IOCTL_STORAGE_GET_MEDIA_TYPES_EX只能得到很少的磁盘参数,我想获得包括硬盘序列号在内的更加详细的信息,有 ...
- vxWorks驱动架构
Vxworks内核驱动基本结构: 三张表:1. 系统设备表 2. 系统驱动表 3. 文件描述符表 Vxworks 内部对每个设备使用DEV_HDR 数据结构进行表示: Typedef str ...
- 如何修改64位Eclipse中的代码字体大小
1.双击打开Eclipse,如下图所示: 2.找到菜单栏中的Window,单击它,选择Preferences 3.在左侧的树形菜单中找到General--->Appearance--->C ...
- 解析FAT16文件系统
引导扇区的信息如下: 1. 偏移地址00H,长度3,内容:EB 3C 90 跳转指令. 2. 偏移地址03H,长度8,内容:4D 53 44 4F 53 35 2E 30 为厂商标志和os 版本号 ...