MySQL分组、链接的使用
一、深入学习 group by
group by ,分组,顾名思义,把数据按什么来分组,每一组都有什么特点。
1、我们先从最简单的开始:
select count(*) from tb1 group by tb1.sex;
查询所有数据的条数,按性别来分组。这样查询到的结果集只有一列count(*)。
2、然后我们来分析一下,这个分组,我们能在select 和 from 之间放一些什么呢?
当数据分组之后,数据的大部分字段都将失去它存在的意义,大家想想,多条数据的同一列,只显示一个值,那到底显示谁的,这个值有用吗?
通过思考,不难发现,只有by的那些列可以放进去,然后就是sql的函数操作了,比如count(),sum()……(包含在by后面作为分组的依据,包含在聚合函数中作为结果)
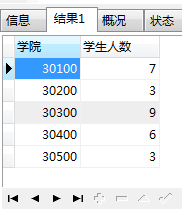
例:查询每个学院的学生有多少人:(学院的值是学院的id)
SELECT a.COLLEGE AS 学院,COUNT(*) AS 学生人数 FROM base_alumni a GROUP BY a.COLLEGE;
3、where,having,和group by联合使用
在最初学习group by的时候,我就陷入了一个误区,那就是group by不能和where一起使用,只能用having……
看书不认真啊,其实它们都是可以一起使用的,只不过是where只能在group by 的前面,having只能在group by 的后面。
where,过滤条件的关键字,但是它只能对group by之前的数据进行过滤筛选;
having,也是过滤条件的关键字作用和where是一样的,但是它过滤的是分组后的数据,就是对分组后得到的结果集进行过滤筛选。
出现having其实我觉得就是为了解决一条语句出现两个where的问题,把它们区分开来
例:
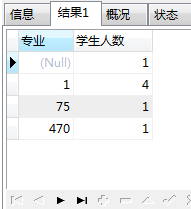
查询 30100学院的每个专业的学生有多少人。
SELECT a.MAJOR AS 专业, COUNT(*) AS 学生人数 FROM base_alumni a WHERE a.COLLEGE = 30100 GROUP BY a.MAJOR;
查询每个学院的学生有多少人,并且只要学生人数大于3的。
SELECT a.COLLEGE AS 学院,COUNT(*) AS 学生人数 FROM base_alumni a GROUP BY a.COLLEGE HAVING COUNT(*)>3;
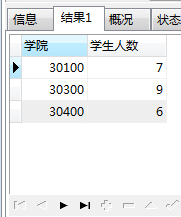
滤清执行顺序:①先对*进行筛选,②对筛选的结果进行分组,③对分组的结果进行筛选
4、Group By All 的使用,哈哈哈哈,经常网上的查阅,我决定淘汰这个语法~
其实就是前面where之后,想要分组的结果显示不符合where的数据,当然,不做运算,运算结果用0或null表示,感觉这语法没啥用,想不出应用场景~
二、深入学习 连接
连接分4种,内连接,全连接,左外连接,右外连接
https://www.cnblogs.com/afirefly/archive/2010/10/08/1845906.html
1、连接出现的地方
①from和where之间,做表和表的连接
②where和having之间,having是对group by的结果集进行筛选,就是把group by的结果集作为一张表,然后可以再和别的表做连接,再进一步筛选
2、连接类型解读
把表看成是一个集合,连接看成是映射,那么它们的结果
内连接:一一映射;全连接:笛卡尔乘积;左外连接:一一映射+左表对应右表的null;右外连接:一一映射+右表对应左表的null。
关键字:
内连接:inner join;全连接:cross join;左外连接:left join;右外连接:right join 。
语法:
表a left join 表b on a.列1 = b.列2
3、连接的使用
之前学习group by的例子中,结果集是存在bug的。
例:查询每个学院的学生有多少人:(学院的值是学院的id),在没有连接的时候,学院人数为0的是显示不出来的,因为当前表中就没有这个学院的信息
那么我们在这里做一下左连接(左外连接):
SELECT c.ID, a.COLLEGE, COUNT(a.COLLEGE) FROM (SELECT ID FROM dic_college) c LEFT JOIN ( SELECT COLLEGE FROM base_alumni ) a ON c.ID = a.COLLEGE GROUP BY c.ID
我这里是一个完整的语句了。我在写出这条语句之前遇到了许多的磕磕碰碰。
解读它:
我们先把学院表和校友信息表(学生表)做左连接
因为我们要的是学院,所以学院作为主表,放left join的前面 c LEFT JOIN a ON ...
然后我们发现有很多字段,于是我们去掉多余的字段,这样既方便我们观察,也提高了sql的执行效率
①把学院表变成只有一个字段(SELECT ID FROM dic_college) c
②把学生表变成只有一个字段( SELECT COLLEGE FROM base_alumni ) a
这时,查询结果是这样的
SELECT * FROM (SELECT ID FROM dic_college) c LEFT JOIN ( SELECT COLLEGE FROM base_alumni ) a ON c.ID = a.COLLEGE
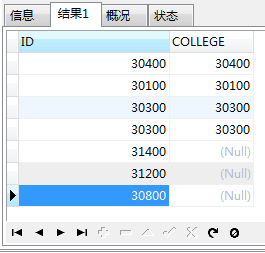
这时候,对这个结果集进行分组:GROUP BY c.ID,并且查询字段要做更改
在上边那个结果集中,c.ID和a.COLLEGE是一一对应的,此时,count(*)的数据是总行数,因为我们的主表是学院表,所以这个数据和count(c.ID)的数据是一样的。
但是a.COLLEGE为空的行的数据中值都是1,这不是我们想要的,所以我们把count(*)改成count(a.COLLEGE),这样数据就出来了。
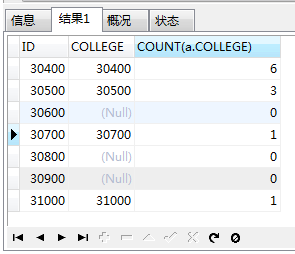
这才是查询所有学院中每个学院的学生人数的正确答案!当然,上边的截图只是数据的前几行,后面还有数据的
4、经过我测试了一下……
左连接和右连接……
SELECT * FROM a LEFT JOIN b ON b.ID = a.FK_ID;
SELECT * FROM b RIGHT JOIN a ON b.ID = a.FK_ID;
这两个语句的结果相同,它两并没有发现别的区别。
全连接就是交叉连接,和不使用连接……
SELECT * FROM c,a WHERE c.ID = a.FK_ID;
SELECT * FROM c CROSS JOIN a ON c.ID = a.FK_ID;
这两个语句也没有区别。
MySQL分组、链接的使用的更多相关文章
- MySQL的链接,查看数据库,使用数据库,查看表
MySQL的链接,查看数据库,使用数据库,查看表 mysql> show databases; +--------------------+ | Database | +------------ ...
- Oracle和MySQL分组查询GROUP BY
Oracle和MySQL分组查询GROUP BY 真题1.Oracle和MySQL中的分组(GROUP BY)有什么区别? 答案:Oracle对于GROUP BY是严格的,所有要SELECT出来的字段 ...
- android+eclipse+mysql+servlet(Android与mysql建立链接)
原创作品,允许转载,转载时请务必以超链接形式标明文章 原创地址 .作者信息和本声明.http://www.cnblogs.com/zhu520/p/7724524.html 经过两天的时间我终于把A ...
- mysql 分组和聚合函数
mysql 分组和聚合函数 Mysql 聚集函数有5个: 1.COUNT() 记录个数(count(1),count(*)统计表中行数,count(列名)统计列中非null数) 2.MAX() 最大值 ...
- mysql 分组内 排序
mysql 分组内 排序 类似于 sqlserver over partition by 因为mysql中木有sqlserver over partition by这个函数,要从sqlserver ...
- mysql 的链接字符
mysql的链接字符: driver =com.mysql.cj.jdbc.Driverurl =jdbc:mysql://localhost:3306/oa?serverTimezone=Asia/ ...
- Mysql 分组选择
Mysql 分组选择 在其他的数据库中我们遇到分组选择的问题时,比如在分组中计算前10名的平均分 我们可以使用row_number()over() 比较方便的得到. 但是在mysql中,问题就被抛了出 ...
- Navicat for MySQL打开链接时出错错误为:2005 - Unknown MySQL server host 'localhost'(0)?
问题:Navicat for MySQL打开链接时出错错误为:2005 - Unknown MySQL server host 'localhost'(0)? 在使用navicat 连接mysql数据 ...
- mysql分组取最大(最小、最新、前N条)条记录
在数据库开发过程中,我们要为每种类型的数据取出前几条记录,或者是取最新.最小.最大等等,这个该如何实现呢,本文章向大家介绍如何实现mysql分组取最大(最小.最新.前N条)条记录.需要的可以参考一下. ...
- linux下mysql远程链接
前言:我的系统是ubuntu,默认不支持mysql远程链接.接下来的步骤改变这点. 1,首先取消mysql本机绑定 编辑/etc/mysql/my.cnf 将”bind-address = 127.0 ...
随机推荐
- 【一天一道LeetCode】#79. Word Search
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given a ...
- 016-类与对象-OC笔记
学习目标 1.[理解]对象在内存中的存储 2.[理解]nil和NULL 3.[了解]#pragma mark分组导航标记 4.[理解]方法与函数 5.[掌握]多文件开发 6.[掌握]对象和方法 7.[ ...
- 【Linux 操作系统】阿里云服务器 操作实战 部署C语言开发环境(vim配置,gcc) 部署J2EE网站(jdk,tomcat)
. 作者 :万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/18964835 . 博客总结 : 设置SecureCRT ...
- RTMPdump(libRTMP) 源代码分析 6: 建立一个流媒体连接 (NetStream部分 1)
===================================================== RTMPdump(libRTMP) 源代码分析系列文章: RTMPdump 源代码分析 1: ...
- IP网际协议 - IP首部,IP路由选择,子网掩码
IP首部 4个字节的32 bit值以下面的次序传输:首先是0-7 bit,其次8-15 bit,然后1 6-23 bit,最后是24~31 bit.这种传输次序称作big endian字节序.由于T ...
- 苹果新的编程语言 Swift 语言进阶(七)--枚举、结构、类
Swift语言中,具有类特征的类型包括三种,即枚举类型.结构类型(包括基本类型,基本类型实际都是结构类型的特例).类.其中枚举类型.结构类型是属于值类型,类属于引用类型.三种类型都可以添加属性.方法. ...
- UNIX/Linux C 程序员需要掌握的七种武器
我是一名普通的软件工程师,不是什么技术大牛.这篇文章所提到的"七种武器"只是我这些年工作经验的一点体会和感悟,如果有错误的地方,还请大家指正. (一)C语言 作为一名C程序员,熟练 ...
- 存储引擎-Bitcast
Bitcast是一种日志型的基于hash表结构的健值对的存储系统,最早追溯于Riak分布式数据库. 目前,Berkeley DB,Tokyo Cabinet,Innostore都使用了这种存储引擎.使 ...
- J2SE-程序执行与内存图
全局程序运行内存图 基础数据类型:byte,short,int,long(整数) float,double(浮点) -- 数值 char ...
- mysql cluster部署
一.mysql cluster的基本概念 1.mysql cluster的组成 管理(MGM)节点:这类节点的作用是管理MySQL Cluster内的其他节点,如提供配置数据.启 ...