SQL入门经典(二) 之数据库基本查询、添加、更新和删除
使用SQL查询:
SQL查询基本语法:
SELECT [ALL|DISTINCT] [TOP (<expression>) [PERCENT] [WITH TIES] ] <column list> [FROM <source table(s)/view>] [WHERE <restrictive condition>]
[GROUD BY<column name or expression using a column in the SELECT list>]
[HAVING <restrictive condition based on the GROUP BY results>]
[ORDER BY <column list>]
[[FOR XML {ROW|AUTO|EXPLICIT|PATH[(<element>)]},XMLDATA][,ELEMENTS][,BINARY base 64]]
[OPTION (<query hint>,[,.....n])]
上面sql语句看起来很复杂。现在大家一一讲解。
SELECT 告诉sql执行什么操作。FROM 要操作的是那个表(注意事项:查询中不能使用*作为字段。查询多少字段,就写多少字段名称)
SELECT * FROM Person.Contact --我要在Person.Contact这个表查询
WHERE 查询条件过滤
SELECT * FROM Person.Contact WHERE FirstName like 'M%'--我要在Person.Contact这个表下查找是FirstName 开头为M的联系人
WHERE字句中可用的运算符如下:
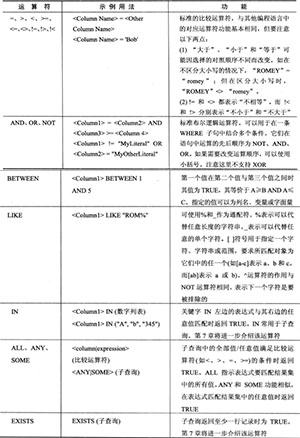
GROUP BY 子句聚合数据函数:
做为BOSS要想知道每件商品的销售量和总价格。就要使用聚合函数
SELECT SalesOrderID,sum(UnitPrice) as TotalPrice FROM Sales.SalesOrderDetail Group BY SalesOrderID--聚合函数
SELECT SalesOrderID,sum(UnitPrice) as TotalPrice FROM Sales.SalesOrderDetail Group BY SalesOrderID having sum(UnitPrice) >10000
注意事项:过滤掉销售额小于10000的商品。不知道为什么TotalPrice 不能作为聚合函数的过滤。只能用 sum(UnitPrice) 过滤.可以在聚合函数前使用where过滤。where过滤不能使用聚合函数。容易错误点:group by 后面使用where过滤。GROUP by 只能用having过滤。having 过滤等聚合函数填充完毕后才能过滤。
聚合函数有:COUNT()求个数 SUM()求和 AVG()求平均数 MIN()最小值 MAX()最大值这些是比较常用的聚合函数,可以单独使用,也可以和group by使用。
现在介绍COUNT()聚合函数 :先看2条代码和结果
select count(1) from Person.Contact --结果19972条数据
select count(MiddleName) from Person.Contact --11473条数据
上面2条数据结果不一样,这个不用当心。后面博客会说这个问题(建议不要带列名作为count聚合函数)
ORDER BY 排序查询:
BOSS要求看那个商品销售前10名:这里也把TOP这个关键词介绍了。order by 那个字段DESC 按照那个字段降序排,asc升序排。top取前面多少条数据
SELECT TOP 10 SalesOrderID,sum(UnitPrice) as TotalPrice FROM Sales.SalesOrderDetail Group BY SalesOrderID having sum(UnitPrice) >10000 ORDER BY TotalPrice DESC --按照销售额从高到底排序前10名数据
DISTINCT 和ALL的谓词:如果数据库有100条一样数据。 ALL是全部加载一样数据100次。DISTINCT只加载一条数据。其余99条舍弃掉。
FOR XML这里不做介绍了。后面有专门博客介绍这个查询。
INSERT 添加数据
基本语法:INSERT [TOP (<expression> )[PERCENT] [INTO] <table object>[(<column listt>)][OUTPUT <output clause>] {VALUES(<data value>)[,(datavalues)][,....n]|<table source>|EXEC <procedure>|DEFAULT VALUES}
上面语法是不是看起来很复杂,简化语法:INSERT INTO<tables object>[(<column list>)] VALUES(<data value>)[,(datavalues)][,....n]
为了下面的学习我们建立数据表:

USE AdventureWorks GO CREATE TABLE Stores
(
StoresCode char(4) NOT NULL Primary KEY,
Name nvarchar(40) NOT NULL,
Address nvarchar(20) NULL,
City nvarchar(20) null,
State char(2) DEFAULT('0') NOT NULL,
Zip Char(5) NOT NULL
)
CREATE TABLE Sales
(
OrderNumber Varchar(20) not null primary key,
StoresCode char(4) FOREIGN KEY REFERENCES Stores(StoresCode) not null ,
OrderDate datetime default(getdate()) not null,
Quantity int not null,
Terms Varchar(12) not null,
TitleID int not null
)
试一试:插入一条数据(可以直接后面写要添加数据要与数据表的列名相对应)
INSERT INTO Stores Values('Test','Test Stores','China','ShenZhen','0','100000')
第一次插入值正确第二次错误:违反了 PRIMARY KEY 约束 'PK__Stores__6F4A8121'。不能在对象 'dbo.Stores' 中插入重复键。后面博客会专门讲键和约束。
我在对插入一条数据做下修改:
INSERT INTO Stores(StoresCode,Name,City,Zip)Values('tes2','Test Store', 'Here','10000')
可以注意到插入SQL语句:少了address,state 插入,列设置为NULL值可以忽略提供该列的值。如果列不能设置null。则必须为下面3个条件之一,否则系统会提示错误。INSERT 终止命令被拒绝执行。
1.列定义默认值,默认值是未提供插入值会自动插入一个常量值。(后面键与默认值会说这个问题)2.列定义为接受某种形式系统生成值,最常用的生成值是为IDENTITY值。3插入数据已经提供该列的值。
批量插入数据:
INSERT INTO Stores(StoresCode,Name,City,Zip)
VALUES('tes5','Test Stores','bj','10000'),
('tes4','Test Stores','bj','10000');
--(2 行受影响)这是sql server 2008数据库添加新功能
INSERT INTO .....SELECT 语句:
语法:INSERT INTO <table_name>[column list] <select statement>
CREATE TABLE #temp
(
ID char(4) not null,
name nvarchar(20) not null
)
INSERT INTO #temp SELETE StoresCode,Name FROM Stores SELECT * FROM #temp
--结果
--tesT Test Store
--tes3 Test Stores
--tes5 Test Stores
--Test Test Stores
UPDATE 语句更改获取得到的数据
语法:UPDATE <table name> SET <column>=<value>[,column=value] [FROM <source tables>] [WHERE <restrictive condition> ]
UPDATE Stores SET State='1' --4条受影响(成功更新了4条数据)
UPDATE Stores SET State='0' WHERE StoresCOde='tes2' --1条受影响
DELETE 语句
删除语句非常简单,语法:DELETE <table name> [WHERE < condition> ]
DELETE Stores --删除所有数据
DELETE Stores WHERE StoresCode='test'--删除StoresCode='test'数据
SQL入门经典(二) 之数据库基本查询、添加、更新和删除的更多相关文章
- SQL入门经典(十) 之事务
事务是什么?事务关键在与其原子性.原子性概念是指可以把一些事情当作一个执行单元来看待.从数据库角度看待.他是指应该全部执行或者全部不执行一条或多条语句的最小组合.当处理数据时候经常确保一件事发生另一件 ...
- 《SQL入门经典》总结
<SQL入门经典>这本书从考试前就开了个头,一直到前两天才看完,拉的战线也够长的.放假来了,基本上什么内容都不记得了.好不容易看完了,就赶紧总结一下吧! 该书分为两大部分,第一部分是第1~ ...
- SQL总结(二)连表查询
---恢复内容开始--- SQL总结(二)连表查询 连接查询包括合并.内连接.外连接和交叉连接,如果涉及多表查询,了解这些连接的特点很重要. 只有真正了解它们之间的区别,才能正确使用. 1.Union ...
- MongoDB 的创建、查询、更新、删除
MongoDB数据库中,创建.查询.更新.删除操作的对象是集合. 1.查看某个数据库中有哪些集合,在此之前需要使用数据库 C:\Windows\system32>mongo MongoDB sh ...
- 返璞归真 asp.net mvc (1) - 添加、查询、更新和删除的 Demo
原文:返璞归真 asp.net mvc (1) - 添加.查询.更新和删除的 Demo [索引页] [源码下载] 返璞归真 asp.net mvc (1) - 添加.查询.更新和删除的 Demo 作者 ...
- SQL入门经典(一)之简介
今天是我第一天开通博客,也是我的第一篇博客.以后为大家带来第一篇关于学习技术性文章,这段时间会为大家带来是SQL入门学习.希望大家坚持读下去,因为学历有限.我也是初学者.语言表达能力不好和知识点不足, ...
- sql 入门经典(第五版) Ryan Stephens 学习笔记 后续——存储引擎
一.引擎基础 1 查看系统支持的存储引擎 show engines; 2 查看表使用的存储引擎两种方法: a.show table status from database_name where na ...
- SQL入门经典(五) 之键和约束
这一篇博客主要讲键的创建,约束的创建.修改对象和删除对象. 主键:主键是每行的唯一标识符,必须包含唯一值(因此不能为NULL).由于主键在关系中数据库的重要性,因此它是所有键和约束中最重要的.一个表最 ...
- MongoDB快速入门(二)- 数据库
创建数据库 MongoDB use DATABASE_NAME 用于创建数据库.该命令如果数据库不存在,将创建一个新的数据库, 否则将返回现有的数据库. 语法 use DATABASE语句的基本语法如 ...
随机推荐
- lvs+keepalived+nginx实现高性能负载均衡集群
一.为什么要使用负载均衡技术? 1.系统高可用性 2. 系统可扩展性 3. 负载均衡能力 LVS+keepalived能很好的实现以上的要求,LVS提供负载均衡,keepalived提供健康检查, ...
- pycharm5新版注册
##注册方法1### 0x1 ,安装 0x2 , 调整时间到2038年. 0x3 ,申请30天试用 0x4, 退出pycharm 0x5, 时间调整回来. ##注册方法2### 注册方法: 在 注册时 ...
- SQL图形化操作设置级联更新和删除
SQL级联操作设置 对SQL数据库的表,进行级联操作(如级联更新及删除),首先需要设置表的主外键关系,有两种方法: 第一种: 1. 选择你要进行操作的数据库 2. 为你要创建关系的两个 ...
- homestead注意事项
1.如何修改php.ini Here is how you grant read/write access to php.ini, modify it, save changes & relo ...
- 怎么将oracle数据库的数据迁移
打开要导出数据的PC,进入cmd界面 先进入数据库输入sqlplus,账号system密码508956.有权限的账户密码 2. create directory dir_555 as 'd:/asd1 ...
- 移动APP开发使用什么样的原型设计工具比较合适?
原型设计工具有Axure,Balsamiq Mockups,JustinMind,iClap原型工具,等其他原型工具.其中JustinMind比较适合APP开发使用. JustinMind可以输出Ht ...
- 【安卓安全】ARM平台代码保护之虚拟化
简介:代码的虚拟化即不直接通过CPU而是通过虚拟机来执行虚拟指令.代码虚拟化能有效防止逆向分析,可大大地增加了代码分析的难度和所需要的时间,若配合混淆等手段,对于动静态分析有着较强的防御能力. 背景: ...
- Eclipse导入Maven项目,使用server 启动报错,class 找不到,
问题发现: 1.导入maven 项目后,用server 启动,选择项中没有这个项目 解决: 说明server 没有把该项目当成web项目,需要设置 项目右键 properties ---- proj ...
- [10]APUE:信号
[a] 常用信号 SIGABRT 调用 abort 函数时产生此信号,进程异常终止 SIGALRM 调用 alarm 或 setitimer 函数超时之后产生 SIGCHLD 子进程终止或 stop ...
- Jquery实现文字向上逐条滚动
直接上代码: <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" ...