IMPORT FROM 表数据导入
The type of the file to be imported. You can specify either comma-separated values or control file formats. For more information on CSV and control file formats, see Examples.
- CSV FILE :该文件存储的为表数据
- CONTROL FILE:该文件是控制文件,即将导入的脚本写在这个文件里,然后还是通过这个 IMPORT 语句执行这个脚本控制文件即可,这样就不需要将导数的语句直接贴在SQL编辑器里运行了
The complete path and file name of the file to import.
The target table name, with optional schema name, where the imported data will be stored.
<import_from_option> ::= THREADS <number_of_threads>
| BATCH <number_of_records_of_each_commit>
| TABLE LOCK
| NO TYPE CHECK
| SKIP FIRST <number_of_rows_to_skip> ROW
| COLUMN LIST IN FIRST ROW [<with_schema_flexibility>]
| COLUMN LIST ( <column_name_list> ) [<with_schema_flexibility>]
| RECORD DELIMITED BY <string_for_record_delimiter>
| FIELD DELIMITED BY <string_for_field_delimiter>
| OPTIONALLY ENCLOSED BY <character_for_optional_enclosure>
| DATE FORMAT <string_for_date_format>
| TIME FORMAT <string_for_time_format>
| TIMESTAMP FORMAT <string_for_timestamp_format>
| ERROR LOG <file_path_of_error_log>
| FAIL ON INVALID DATA
The number of threads that can be used for concurrent import. The default value is 1 and maximum allowed is 256.
The number of records to be inserted in each commit.
Can be used for faster data loading for column store tables. 可以加快列存储表数据的导入
It is recommended to specify this option carefully as it incurs table locks in exclusive mode as well as explicit hard merges and savepoints after data loading is finished. The performance gain from this option can vary according to the table constraints (like primary key) and optimization of other layers (like persistency or DML command).
Specifies that the record will be inserted without checking the type of each field.
<number_of_rows_to_skip> ::= <unsigned_integer>
Skips the specified number of rows in the import file.
Indicates that the column list is stored in the first row of the CSV import file.
<column_name_list> ::= <column_name> [{, <column_name>}...]
The column list for the data being imported. The name list has one or more column names. The ordering of the column names has to match the order of the column data in the CSV file and the columns in the target table.
The record delimiter used in the CSV file being imported.
The field delimiter of the CSV file.
The optional enclosure character used to delimit field data.
The format that date strings are encoded with in the import data:
- Y : year
- MM : month
- MON : name of month
- DD : day
- 'YYYYMMDD' = 20120520
- 'YYYY-MM-DD' = 2012-05-20
- 'YYYY-MON-DD' : 2012-MAY-20
The format that time strings are encoded with in the import data:
- HH24 : hour
- MI : minute
- SS : second
For example:
- 'HH24MISS' : 143025
- 'HH24:MI:SS' : 14:30:25
TIMESTAMP FORMAT <string_for_timestamp_format> ::= <string_literal>
The format that timestamp strings are encoded with in the import data.
- 'YYYY-MM-DD HH24:MI:SS' : 2012-05-20 14:30:25
When specified, a log file of errors generated is stored in this file. Please ensure the file path you use is writeable by the database.
指定错误日志文件(含路径)
When specified, the IMPORT FROM command fails unless all the entries import successfully.
The option WITH SCHEMA FLEXIBILITY will create missing columns in flexible tables during CSV imports, as specified in the header (first row) of the CSV file or column list. By default, missing columns in flexible tables are not created automatically during data imports.
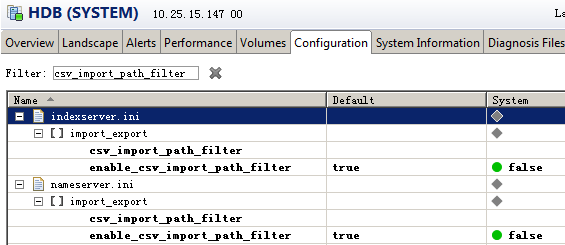
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'system') set ('import_export', 'enable_csv_import_path_filter') = 'false' with reconfigure
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'system') set ('import_export', 'csv_import_path_filter') = '/A;/B' with reconfigure
Note that once you add a path '/A' to path filter every sub-path of '/A' will be automatically added as well.
- Dynamic Tiering
Example 1 - Importing CSV Data
1,"DATA1","2012-05-20","14:30:25",123456
2,"DATA2","2012-05-21","15:30:25",234567
3,"DATA3","2012-05-22","16:30:25",345678
4,"DATA4","2012-05-23","17:30:25",456789

Example 2 - Importing using a control file
You can create a control file /usr/sap/HDB/home/Desktop/data/data.ctl and add the contents shown below to the file.
ERROR LOG '/usr/sap/HDB/home/Desktop/data/data.err'
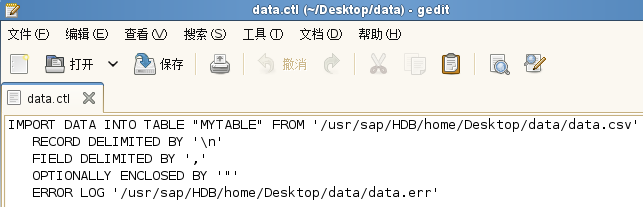 You execute the following command to import the data using the control file.
You execute the following command to import the data using the control file.
Example 3 - Import using date formats
1,"DATA1","05-20-2012","14:30:25",123456
2,"DATA2","05-21-2012","15:30:25",234567
3,"DATA3","05-22-2012","16:30:25",345678
4,"DATA4","05-23-2012","17:30:25",456789
DATE FORMAT 'MM-DD-YYYY';
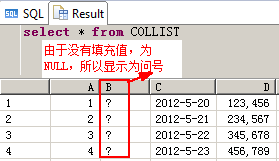
Example 4 - Import using COLUMN LIST
CREATE TABLE COLLIST ( A INT, B VARCHAR(10), C DATE, D DECIMAL );
You create a CSV text file '/usr/sap/HDB/home/Desktop/data/data_col_list.csv' and add the following contents.
现在
data_col_list.csv文件里的内容如下,B列值没有提供,并且CSV里的第一列要存到D列里,第二列要存到C里,第三列要存储到A列里
You execute the following commands to import the data using a column list.
COLUMN LIST ("D", "C", "A");
CREATE COLUMN TABLE FLEX ( X INT ) WITH SCHEMA FLEXIBILITY;--WITH SCHEMA FLEXIBILITY选项只能用于列式存储的表
创建一个可伸缩的表,只有X一列,使用上面的data_col_list.csv文件,文件里有3列,且都没存储到X列里
You execute the following commands to import previously created data_col_list.csv without explicitly adding columns.
WITH SCHEMA FLEXIBILITY;
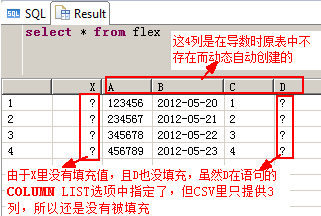

在自动创建缺失的列时,好像无法指定类型,默认类型全为 nvarchar(5000)?这不太好吧!是否有办法指定呢?
IMPORT FROM 表数据导入的更多相关文章
- Excel表数据导入Sql Server数据库中
Excel表数据导入Sql Server数据库的方法很多,这里只是介绍了其中一种: 1.首先,我们要先在test数据库中新建一个my_test表,该表具有三个字段tid int类型, tname nv ...
- 把execel表数据导入mysql数据库
今天,是我来公司第二周的第一天. 作为新入职的实习生,目前还没适合我的实质项目工作,今天的学习任务是: 把execel表数据导入到mysql数据库,再练习下java操作JDBC. 先了解下execel ...
- SqlServer一张表数据导入另一张表,收藏使用,工作中更新数据错误很有用
sql一张表数据导入另一张表 1.如果2张表的字段一致,并且希望插入全部数据,可以用这种方法: INSERT INTO 目标表 SELECT * FROM 来源表; 2.比如要将 arti ...
- HBase(三): Azure HDInsigt HBase表数据导入本地HBase
目录: hdfs 命令操作本地 hbase Azure HDInsight HBase表数据导入本地 hbase hdfs命令操作本地hbase: 参见 HDP2.4安装(五):集群及组件安装 , ...
- Excel表数据导入数据库表中
***Excel表数据导入到数据库表中 通过数据库表的模板做成‘Excel’表的数据导入到数据库相应的表中(注意:主表 和 从表的关系,要先导‘主表’在导入从表) 过程:通过数据库的导入工具—先导入为 ...
- C# DateTime的11种构造函数 [Abp 源码分析]十五、自动审计记录 .Net 登陆的时候添加验证码 使用Topshelf开发Windows服务、记录日志 日常杂记——C#验证码 c#_生成图片式验证码 C# 利用SharpZipLib生成压缩包 Sql2012如何将远程服务器数据库及表、表结构、表数据导入本地数据库
C# DateTime的11种构造函数 别的也不多说没直接贴代码 using System; using System.Collections.Generic; using System.Glob ...
- java基于xml配置的通用excel单表数据导入组件(四、DAO主处理类)
package XXXXX.manage.importexcel; import java.beans.IntrospectionException; import java.io.BufferedR ...
- 利用Sql实现将指定表数据导入到另一个数据库示例
因为工作中经常需要将数据从一个数据库导入到另一个数据库中,所以将这个功能写成一个存储过程,以方便调用.现在粘贴出来供大家参考: 注意:1,以下示例中用到了syscolumns,sysobjects等系 ...
- java基于xml配置的通用excel单表数据导入组件(五、Action处理类)
package xxxxxx.manage.importexcel; import java.io.File; import java.util.HashMap; import java.util.M ...
随机推荐
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- 手机APP开发:学JAVA转安卓APP开发是不是很容易?
成都亿合云商小编为您分享:Android开发是以Java语言为基础的,Android 虽然使用Java 语言作为开发工具,但是在实际开发中发现,还是与Java SDK 有一些不同的地方.Android ...
- J2EE与JavaWeb的区别
1.Java分类 Java分为JavaSE(Java标准版).J2EE(Java企业版)和JavaME(Java微型版): JavaSE(Java Standard Edition),一般用来开发桌面 ...
- 移动端 触摸事件 ontouchstart、ontouchmove、ontouchend、ontouchcancel
1.Touch事件简介 pc上的web页面鼠 标会产生onmousedown.onmouseup.onmouseout.onmouseover.onmousemove的事件,但是在移动终端如 ipho ...
- 003-常用的Meta标签写法和作用
页面关键词<meta name="keywords" content="your,tags"/> 页面描述<meta name="d ...
- Ext.data.SimpleStore的使用方法
Ext.data.SimpleStore简单数据存储器 参数:data:Array数组类型.fields:数组对应的字段名称.var data1=[1,"订单1","16 ...
- Mac下好用的编辑器VIM GUI版本 VimR 推荐
vim号称是编辑器之神,轮其功能和扩展性的确少有编辑器能比,但是大多数编辑器都有的文件浏览功能它确没有,虽然有些插件可以实现,但用起来都不是很方便,偶然发现了一个GUI版本的VIM,与普通的GUI版本 ...
- 该字符串未被识别为有效的 DateTime
开发语言C#,System.Data.SQLite.dll驱动. SQLserver数据库转换为SQLite数据库时,日期类型默认转为DATETIME. 执行查询SQL语句,数据为空(查询不到数据时) ...
- 今天开始Swift学习
今天开始Swift学习 在此记录笔记 以备之后查阅! allenhuang
- HTML和CSS的复习总结
HTML(Hypertext Markup Language)超文本标记语言:其核心就是各种标记!<html> HTML页面中的所有内容,都在该标签之内:它主要含<head>和 ...