大小端,memcpy和构造函数
问题:memcpy一段内存到std::bitset里,bitset里的内存数据和被拷贝的内存数据对应不上
代码如下:
#include <iostream>
#include <bitset>
using namespace std;
int main()
{
char a[5] = { 0x00,0x03,0x03,0x04,0x05 };
std::bitset<16> tBitset;
memcpy(&tBitset, a, 2); std::bitset<16> t2Bitset(3);
int n = sizeof(unsigned long);
system("pause");
return 0;
}
此时我的预期是:tBitset={0x0003}
而实际调试结果如下:

tBitset={0x00C0}
最终不断调试得到原因:
memcpy拷贝传入的参数是char*,一个一个字节拷贝,当我们把tBitset的地址传进去拷贝的时候,做了这么几件事情:
1、将a数组的第一第二2个字节的数据拷贝到tBitset里面
2、char数据隐式转换为unsigned long
3、使用构造函数bitset (unsigned long val);对tBitset构造
具体调试截图如下:


可以看到我们只copy了2个字节可是有4个字节的数据,因为char*转为unsinged long(32位机4字节)
- 大端模式:数字逻辑高位存储在内存的物理低位
- 小端模式:数字逻辑低位存储在内存的物理低位
我是小端模式,所以这个 unsigned long 的数据为 00 00 03 00,2^8+2^9=768;转化为16进制是0x300;tBitset是0000 0011 0000 0000;和调试结果截图对应
然而为了测试unsigned long 构造出来的bitset是怎么样的,我用std::bitset<16> t2Bitset(3);16进制是0x3;二进制11 看到内存结果截图为
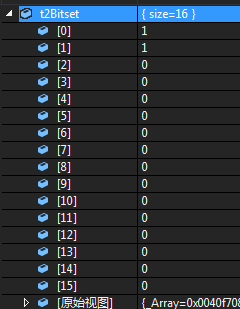
因此右边第一位是数组第0位
之所以刚开始的预期错误,是因为误以为,传入A地址memcpy,就以为A的内存和被拷贝的内存完全一致,A的数组某一位和内存某一位对应,这种想法是错误的,其实A的数组某一位是由A的构造函数决定的,当我把同一块内存的数据分别以unsigned long 和 string类型作参数传进构造函数去,A数组的同一位值可能就不一样,切记
大小端,memcpy和构造函数的更多相关文章
- 大小端 Big-Endian 与 Little-Endian
应该说没做底层开发(硬件或驱动)的人很可能不会彻底理解大小端的概念,大小端不是简单的一句“大端在前”还是“小端在前”能够概括的问题.在cpu, 内存, 操作系统, 编译选项, 文件,网络传输中均有大小 ...
- ARM CPU大小端
ARM CPU大小端: 大端模式:低位字节存在高地址上,高位字节存在低地址上 小端模式:高位字节存在高地址上,低位字节存在低地址上 STM32属于小端模式,简单的说,比如u32 temp=0X1234 ...
- C语言共用体、大小端、枚举
1.共用体和结构体的相同和不同 (1)相同点就是操作语法几乎相同.(2)不同点是本质上的不同.struct是多个独立元素(内存空间)打包在一起:union是一个元素(内存空间)的多种不同解析方式. # ...
- 联合体union和大小端(big-endian、little-endian)
1.联合体union的基本特性——和struct的同与不同 union,中文名“联合体.共用体”,在某种程度上类似结构体struct的一种数据结构,共用体(union)和结构体(struct)同样可以 ...
- CPU的大小端模式
不同体系结构的CPU,数据在内存中存放的排列顺序是不一样的. 存储器中对数据的存储是以字节(Byte)为基本单位的,因此,字(Word)和半字(Half-Word)在存储器中就有两种次序,分别称为:大 ...
- C++/java之间的Socket通信大小端注意事项
在一个物联往项目中,需要java云平台与一个客户端做socket定制协议的通信:然而在第一次测试时,并没有按照预想的那样完成解析.查找资料以后是因为客户端的数据读取方式为小端模式,而java默认采用大 ...
- 从inet_pton()看大小端字节序
#include<stdio.h> #include<netinet/in.h> #include<stdlib.h> #include<string.h&g ...
- 【转】 CPU大小端
大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中:小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中. 为什么会有大小端模式之分呢?这是因为 ...
- linux kernel 如何处理大小端
暂时在用MPC8309,不太清楚大小端内核是什么时候给转的. 今天看了关于readl和writel具体实现的文章 今天就主要来分析下readl/writel如何实现高效的数据swap和寄存器读写.我们 ...
随机推荐
- 大数据框架hadoop服务角色介绍
翻了一下最近一段时间写的分享,DKHadoop发行版本下载.安装.运行环境部署等相关内容几乎都已经写了一遍了.虽然有的地方可能写的不是很详细,个人理解水平有限还请见谅吧!我记得在写DKHadoop运行 ...
- scala IDE for Eclipse开发Spark程序
1.开发环境准备 scala IDE for Eclipse:版本(4.6.1) 官网下载:http://scala-ide.org/download/sdk.html 百度云盘下载:链接:http: ...
- Java生成PDF文档(表格、列表、添加图片等)
需要的两个包及下载地址: (1)iText.jar:http://download.csdn.net/source/296416 (2)iTextAsian.jar(用来进行中文的转换):http:/ ...
- 源码查看工具ctags+vim
一.ctags源码工具的安装 1.sudo apt-get install ctags 2.源码目录如下: 3.对配置文件进行配置 4.在末尾添加如下: 二.使用 1. 进入源码目录,输入ctags ...
- EXPLAIN执行计划中要重点关注哪些要素
MySQL的EXPLAIN当然和ORACLE的没法比,不过我们从它输出的结果中,也可以得到很多有用的信息. 总的来说,我们只需要关注结果中的几列: 列名 备注 type 本次查询表联接类型,从这里可以 ...
- sublime text2建成C语言(C++)编译环境
四个步骤: 下载安装Sublime text2 for windows 下载安装 MinGW 与 系统变量设置 Sublime Building System 设置 编译测试 一.下载安装Sublim ...
- 窗体Form的FormStyle属性设置为fsStayOnTop时属性设置不起作用问题探讨。
procedure CreateParams(var Params: TCreateParams); override; procedure MainForm.Createparams(var Par ...
- Hiero的spreadsheet中添加tag属性列
Hiero在对剪辑线上的item进行管理的时候,往往会添加能多tag,而在管 理面板spreadsheet中却无法对tag进行查询,这是一件很麻烦的事,Hiero Development Guide中 ...
- 修改docker容器的端口映射
大家都知道docker run可以指定端口映射,但是容器一旦生成,就没有一个命令可以直接修改.通常间接的办法是,保存镜像,再创建一个新的容器,在创建时指定新的端口映射. 有没有办法不保存镜像而直接修改 ...
- Hadoop 管理工具HUE配置
机器环境 Ubuntu 14.10 64位 || OpenJDK-7 || Scala-2.10.4 机群概况 Hadoop-2.6.0 || HBase-1.0.0 || Spark-1.2.0 | ...