python+爬虫+签名
在公众号,看到一个比较好玩的程序。它使用post的来传送请求,以前没有遇到过。可能是自己,写的程序太少了。查了一下post的用法:
通常,你想要发送一些编码为表单形式的数据——非常像一个 HTML 表单。要实现这个,只需简单地传递一个字典给 data 参数。你的数据字典在发出请求时会自动编码为表单形式:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("http://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
用data参数,发送一个类似表单的数据。虽然是照着别人的程序敲得,但是还是遇到了,很多了错误。总结起来,是字典里的键写错了。导致爬取的图片,不是自己想要的图片。自己眼高手低啊。
虽然我们的键和值写错了,可以爬取图片,但是爬取的图片并不是我们想要的。自己思考是,传递的参数,不能加载到爬取的网页。爬取的只是网页的初始图片,而不是我们传递参数后运行得到的图片。
以下是代码:
from tkinter import *
from tkinter import messagebox
import requests
import re
from PIL import Image,ImageTk #模拟浏览器发送请求
def download(): startUrl = "http://www.uustv.com/"
#获取用户输入的姓名
name = entry.get()
#去空格
name = name.strip()
if name == '':
messagebox.showinfo("提示:","请输入用户名")
else:
date = {
'word': name,
'sizes': '',
'fonts': 'jfcs.ttf',
'fontcolor' : '#000000'
}
result = requests.post(startUrl,data = date)
result.encoding = "utf-8"
#获取网站的源代码
html = result.text
reg = '<div class="tu">.<img src="(.*?)"/></div>'
#正则表达式 (.*?)全部都需要匹配
imagePath = re.findall(reg,html)
#获取图片的完整路径
imgUrl = startUrl + imagePath[0]
print(imgUrl)
#获取图片的内容
response = requests.get(imgUrl).content
f = open('{}.gif'.format(name),'wb')
f.write(response) #图片显示到窗口上
bm = ImageTk.PhotoImage(file = '{}.gif'.format(name)) label2 = Label(root,image = bm)
label2.bm = bm
label2.grid(row = 2,columnspan = 2) # GUI用户使用界面
#创建窗口
root = Tk()
#标题
root.title("我要学python")
#窗口的大小 宽,高
root.geometry("600x300")
#窗口的位置
root.geometry("-500+200")
#标签控件
label = Label(root,text = "签名",font = ("华文行楷",20),fg = "blue")
label.grid(row = 0,column = 0) #设计输入框
entry = Entry(root,font = ("微雅素黑",20))
entry.grid(row = 0,column = 1)
#点击按钮
button = Button(root,text = "设计签名",font = ("微雅素黑",22),command = download)
button.grid(row = 1,column = 0)
#循环消息,显示窗口
root.mainloop()
个人总结是通过post来获取图片的地址,然后通过get来获取图片,然后加载图片。图片有点难看。
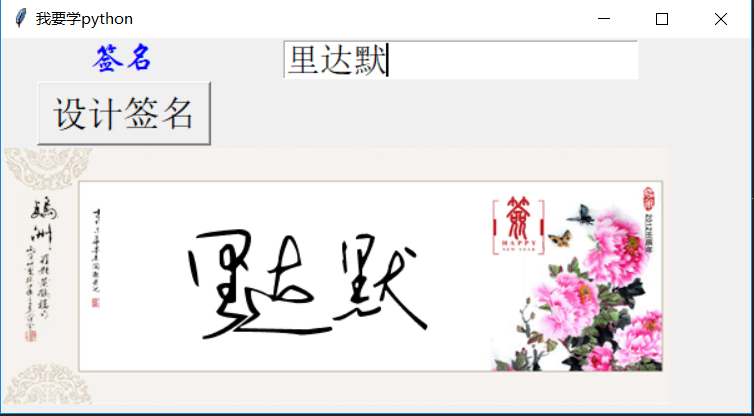
python+爬虫+签名的更多相关文章
- Python爬虫初学(二)—— 爬百度贴吧
Python爬虫初学(二)-- 爬百度贴吧 昨天初步接触了爬虫,实现了爬取网络段子并逐条阅读等功能,详见Python爬虫初学(一). 今天准备对百度贴吧下手了,嘿嘿.依然是跟着这个博客学习的,这次仿照 ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- 23个Python爬虫开源项目代码,让你一次学个够
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [1]– 微信公众号 ...
- Python爬虫开源项目代码,爬取微信、淘宝、豆瓣、知乎、新浪微博、QQ、去哪网等 代码整理
作者:SFLYQ 今天为大家整理了32个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [ ...
- 23个Python爬虫开源项目代码
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [1]– 微信公众号 ...
- 23个Python爬虫开源项目代码,包含微信、淘宝、豆瓣、知乎、微博等
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心,所有链接指向GitHub,微信不能直接打开,老规矩,可以用电脑打开. 关注公众号「Pyth ...
- Python 爬虫的工具列表 附Github代码下载链接
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Python 爬虫的工具列表大全
Python 爬虫的工具列表大全 这个列表包含与网页抓取和数据处理的Python库.网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pyc ...
- 32个Python爬虫实战项目,满足你的项目慌
爬虫项目名称及简介 一些项目名称涉及企业名词,小编用拼写代替 1.[WechatSogou]- weixin公众号爬虫.基于weixin公众号爬虫接口,可以扩展成其他搜索引擎的爬虫,返回结果是列表,每 ...
随机推荐
- 关于百度world 编辑器改变上传图片的保存路径图片不显示的问题
在ueditor.mini for asp.net 中,将上传的图片保存的路径更改了,可图片在 world 编辑器中不显示,但却可以上传到指定的保存目录下,解决这个问题的方法 是: 在udditor_ ...
- Nginx的安装(CentOS 7环境)
安装所需环境 Nginx 是 C语言 开发,建议在 Linux 上运行,当然,也可以安装 Windows 版本,本篇则使用 CentOS 7 作为安装环境. 一. gcc 安装安装 nginx 需要先 ...
- nodejs学习笔记<七> 路由
// 引用模块(与C#中命名空间,Java中引用包同理) var http = require("http"); var path = require("path&quo ...
- django---单表操作之增删改
首先找到操作的首页面‘ 代码如下 <!DOCTYPE html> <html lang="en"> <head> <meta charse ...
- tornado-5.1版本
server.py python server.py执行 import tornado.ioloop import tornado.options import tornado.web from to ...
- hive数据倾斜原因以及解决办法
何谓数据倾斜?数据倾斜指的是,并行处理的数据集 中,某一部分(如Spark的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈. 表现为整体任务基本完成, ...
- jqGrid 获取多级标题表头
1.jgGrid没有提供此方法获取如下标题 2.实现代码 getHeaders:function(){ var headers=[],temptrs=[]; //select the group he ...
- python之 pendulum讲解
一,下载地址:https://pypi.python.org/pypi/pendulum 二,pendulum的一大优势是内嵌式取代Python的datetime类,可以轻易地将它整合进已有代码,并且 ...
- (原)Echarts 报Uncaught Error: Initialize failed: invalid dom 根本解决
1.循环出的Echarts出现 Uncaught Error: Initialize failed: invalid dom ,附上完美解决方案 setTimeout(function () { co ...
- 应用SharedPreference保存程序的配置信息
SharedPreference: 1.用来保存应用程序的配置信息的XML文件,内部的数据形式为键值对 2.一般存在于/data/data/<包名>shared_prefs目录下 3.该对 ...