kappa系数
kappa计算结果为-1~1,通常kappa是落在 0~1 间,可分为五组来表示不同级别的一致性:
| 0.0~0.20 | 极低的一致性(slight) |
| 0.21~0.40 | 一般的一致性(fair) |
| 0.41~0.60 | 中等的一致性(moderate) |
| 0.61~0.80 | 高度的一致性(substantial) |
| 0.81~1 | 几乎完全一致(almost perfect) |
计算公式:

po是每一类正确分类的样本数量之和除以总样本数.
假设每一类的真实样本个数分别为a1,a2,...,aC,预测出来的每一类的样本个数分别为b1,b2,...,bC,总样本个数为n,则有:pe=(a1×b1+a2×b2+...+aC×bC) / (n×n).
举例分析:
学生考试的作文成绩,由两个老师给出 好、中、差三档的打分,现在已知两位老师的打分结果,需要计算两位老师打分之间的相关性kappa系数:
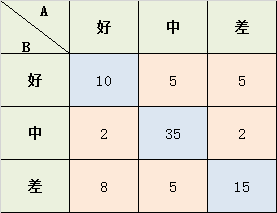
Po = (10+35+15) / 87 = 0.689
a1 = 10+2+8 = 20; a2 = 5+35+5 = 45; a3 = 5+2+15 = 22;
b1 = 10+5+5 = 20; b2 = 2+35+2 = 39; b3 = 8+5+15 = 28;
Pe = (a1*b1 + a2*b2 + a3*b3) / (87*87) = 0.455
K = (Po-Pe) / (1-Pe) = 0.4293578
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix X,y = make_classification()
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) svc = SVC()
svc.fit(X_train,y_train)
y_pred = svc.predict(X_test) result = confusion_matrix(y_test, y_pred) def kappa_coefficient(confusion_matrix):
"""
descibe:compute kappa coefficient
param confusion_matrix:matrix
return kappa coefficient
"""
import numpy as np P_0 = 0
for i in range(len(confusion_matrix)):
P_0 = P_0+confusion_matrix[i,i] a = []
b = []
for i in range(len(confusion_matrix)):
a.append(sum(confusion_matrix[i]))
b.append(sum(confusion_matrix[:,i])) P_e = sum(np.array(a)*np.array(b))/(sum(a)*sum(a))
kappa = (P_0/sum(a)-P_e)/(1-P_e) return kappa kappa_coefficient(confusion_matrix=result)
kappa系数的更多相关文章
- 10. 混淆矩阵、总体分类精度、Kappa系数
一.前言 表征分类精度的指标有很多,其中最常用的就是利用混淆矩阵.总体分类精度以及Kappa系数. 其中混淆矩阵能够很清楚的看到每个地物正确分类的个数以及被错分的类别和个数.但是,混淆矩阵并不能一眼就 ...
- kappa系数在评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- kappa系数在大数据评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- kappa 一致性系数计算实例
kappa系数在遥感分类图像的精度评估方面有重要的应用,因此学会计算kappa系数是必要的 实例1 实例2
- Kappa(cappa)系数只需要看这一篇就够了,算法到python实现
1 定义 百度百科的定义: 它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平 ...
- 【一致性检验指标】Kappa(cappa)系数
1 定义 百度百科的定义: 它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平 ...
- python数据分析所需要了解的操作。
import pandas as pd data_forest_fires = pd.read_csv("data/forestfires.csv", encoding='gbk' ...
- 基于sklearn的metrics库的常用有监督模型评估指标学习
一.分类评估指标 准确率(最直白的指标)缺点:受采样影响极大,比如100个样本中有99个为正例,所以即使模型很无脑地预测全部样本为正例,依然有99%的正确率适用范围:二分类(准确率):二分类.多分类( ...
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
随机推荐
- nginx unit nodejs 模块试用(续)
最新(应该是18 年了)nginx unit 发布了新的版本,对于nodejs 的支持有很大的改进,上次测试过,问题还是 比较多,这次使用新版本在测试下对于nodejs 的支持,以及以前block ...
- C# to IL 3 Selection and Repetition(选择和重复)
In IL, a label is a name followed by the colon sign i.e ":". It gives us the ability to ju ...
- 利用express托管静态文件
通过express内置的express.static可以方便的托管静态文件,例如图片.css.javascript文件等. 将静态资源文件所在的目录作为参数传递给express.static中间件就可 ...
- 如何让你的 KiCad 在缩放时不眩晕?
如何让你的 KiCad 在缩放时不眩晕? 使用 KiCAD 第一感觉是打开速度非常快,而且 PCB 拉线也非常快,封装库又多. 但有一个问题,缩放时总给人一种眩晕,原来是因为鼠标自动跑到屏幕中间去了, ...
- 爱今天 APP 闪退怎么办?
爱今天 APP 闪退怎么办? 爱今天是一款简洁优秀的时间记录 APP. 但也有一些小 Bug,可能是因为不同的手机兼容问题,在添加时间时会出现闪退现象. 可能是因为自己修改了添加时间的方式. 可以通过 ...
- 【转】C#获取当前日期时间(转)
我们可以通过使用DataTime这个类来获取当前的时间.通过调用类中的各种方法我们可以获取不同的时间:如:日期(2008-09-04).时间(12:12:12).日期+时间(2008-09-04 12 ...
- windows下搭建voip服务器
软件: yate-6.0.0-1-setup.exe 服务端,里面也有个客户端 eyeBeam.exe 客户端 步骤: 失败....
- dojo:为数据表格添加复选框
一.添加复选框 此时应该选用EnhancedGrid,而不是普通的DataGrid.添加复选框需要设置EnhancedGrid的plugins属性,如下: gridLayout =[{ default ...
- AXI Quad SPI
AXI Quad SPI 信息来源
- Debian下Netbeans编辑器字体锯齿现象
第一步:到你netbeans安装目录下的etc目录下,找到netbeans.conf文件,打开准备编辑:第二步:在netbeans_default_options后面加上-J-Dawt.useSyst ...