kappa系数
kappa计算结果为-1~1,通常kappa是落在 0~1 间,可分为五组来表示不同级别的一致性:
| 0.0~0.20 | 极低的一致性(slight) |
| 0.21~0.40 | 一般的一致性(fair) |
| 0.41~0.60 | 中等的一致性(moderate) |
| 0.61~0.80 | 高度的一致性(substantial) |
| 0.81~1 | 几乎完全一致(almost perfect) |
计算公式:

po是每一类正确分类的样本数量之和除以总样本数.
假设每一类的真实样本个数分别为a1,a2,...,aC,预测出来的每一类的样本个数分别为b1,b2,...,bC,总样本个数为n,则有:pe=(a1×b1+a2×b2+...+aC×bC) / (n×n).
举例分析:
学生考试的作文成绩,由两个老师给出 好、中、差三档的打分,现在已知两位老师的打分结果,需要计算两位老师打分之间的相关性kappa系数:
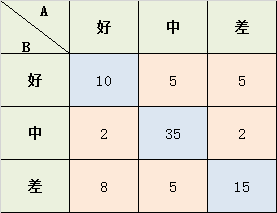
Po = (10+35+15) / 87 = 0.689
a1 = 10+2+8 = 20; a2 = 5+35+5 = 45; a3 = 5+2+15 = 22;
b1 = 10+5+5 = 20; b2 = 2+35+2 = 39; b3 = 8+5+15 = 28;
Pe = (a1*b1 + a2*b2 + a3*b3) / (87*87) = 0.455
K = (Po-Pe) / (1-Pe) = 0.4293578
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix X,y = make_classification()
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) svc = SVC()
svc.fit(X_train,y_train)
y_pred = svc.predict(X_test) result = confusion_matrix(y_test, y_pred) def kappa_coefficient(confusion_matrix):
"""
descibe:compute kappa coefficient
param confusion_matrix:matrix
return kappa coefficient
"""
import numpy as np P_0 = 0
for i in range(len(confusion_matrix)):
P_0 = P_0+confusion_matrix[i,i] a = []
b = []
for i in range(len(confusion_matrix)):
a.append(sum(confusion_matrix[i]))
b.append(sum(confusion_matrix[:,i])) P_e = sum(np.array(a)*np.array(b))/(sum(a)*sum(a))
kappa = (P_0/sum(a)-P_e)/(1-P_e) return kappa kappa_coefficient(confusion_matrix=result)
kappa系数的更多相关文章
- 10. 混淆矩阵、总体分类精度、Kappa系数
一.前言 表征分类精度的指标有很多,其中最常用的就是利用混淆矩阵.总体分类精度以及Kappa系数. 其中混淆矩阵能够很清楚的看到每个地物正确分类的个数以及被错分的类别和个数.但是,混淆矩阵并不能一眼就 ...
- kappa系数在评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- kappa系数在大数据评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- kappa 一致性系数计算实例
kappa系数在遥感分类图像的精度评估方面有重要的应用,因此学会计算kappa系数是必要的 实例1 实例2
- Kappa(cappa)系数只需要看这一篇就够了,算法到python实现
1 定义 百度百科的定义: 它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平 ...
- 【一致性检验指标】Kappa(cappa)系数
1 定义 百度百科的定义: 它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平 ...
- python数据分析所需要了解的操作。
import pandas as pd data_forest_fires = pd.read_csv("data/forestfires.csv", encoding='gbk' ...
- 基于sklearn的metrics库的常用有监督模型评估指标学习
一.分类评估指标 准确率(最直白的指标)缺点:受采样影响极大,比如100个样本中有99个为正例,所以即使模型很无脑地预测全部样本为正例,依然有99%的正确率适用范围:二分类(准确率):二分类.多分类( ...
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
随机推荐
- JQuery左右切换实现
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Understanding how uid and gid work in Docker containers
转自:https://medium.com/@mccode/understanding-how-uid-and-gid-work-in-docker-containers-c37a01d01cf Un ...
- Scalable MySQL Cluster with Master-Slave Replication, ProxySQL Load Balancing and Orchestrator
MySQL is one of the most popular open-source relational databases, used by lots of projects around t ...
- 理解Lambda表达式和闭包
了解由函数指针到Lambda表达式的演化过程 Lambda表达式的这种简洁的语法并不是什么古老的秘法,因为它并不难以理解(难以理解的代码只有一个目的,那就是吓唬程序员) #include " ...
- Hi3536DV100 SDK 安装以及升级使用说明
第一章 Hi3536DV100_SDK_Vx.x.x.x版本升级操作说明 如果您是首次安装本SDK,请直接参看第2章. 第二章 首次安装SDK1.Hi3536DV100 SDK包位置 在"H ...
- 通过 DDNS 解决宽带拨号 ip 变化问题
前面你的文章我已经写了 写了 DMZ 内网映射的 方式. 这样内网主机已经暴露在外网中了. 但是 拨号上网我们的ip是 会变化的.大概规律就是 每次拨号都会变化.如果不拨号,每 24 小时 ip也会自 ...
- oauth2 java 代码示例
@RequestMapping("/oauth") @Controller public class OauthController { String clientId = &qu ...
- scrapy 项目通过scrapyd部署
年前的时候采用scrapy 爬取了某网站的数据,当时只是通过crawl 来运行了爬虫,现在还想通过持续的爬取数据所以需要把爬虫部署起来,查了下文档可以采用scrapyd来部署scrapy项目,scra ...
- C# 打印、输入和for循环的使用
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- XE5 Android 开发数据访问server端[转]
建立一个webservices stand-alone vcl application 作为手机访问的服务端 1.new->other->webservices 2.选择 stand-a ...