Python自动化开发 - 面向对象(一)
本节内容
| 一、编程范式 |
编程是程序员 用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程
一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式,
对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。
不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,
当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。
1、面向过程编程(Procedural Programming)
Procedural programming uses a list of instructions to tell the computer what to do step-by-step.
面向过程编程依赖 procedures,一个procedure包含一组要被进行计算的步骤, 面向过程又被称为top-down languages,
就是程序从上到下一步步执行,一步步从上到下,从头到尾的解决问题 。
基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个小问题或子过程,
这些子过程再执行的过程再继续分解直到小问题足够简单到可以在一个小步骤范围内解决。
举个典型的面向过程的例子, 数据库备份, 分三步,连接数据库,备份数据库,测试备份文件可用性。
def db_conn():
print("connecting db...") def db_backup(dbname):
print("导出数据库...",dbname)
print("将备份文件打包,移至相应目录...") def db_backup_test():
print("将备份文件导入测试库,看导入是否成功") def main():
db_conn()
db_backup('my_db')
db_backup_test() if __name__ == '__main__':
main()
存在问题:
要对程序进行修改,依赖于这个修改部分的各个部分都也要跟着修改。
假如程序开头设置了一个变量值 为1 , 但如果其它子过程依赖这个值 为1的变量才能正常运行,那如果改了这个变量,那这个子过程你也要修改。
假如又有一个其它子程序依赖这个子过程 , 那就会发生一连串的影响,随着程序越来越大, 这种编程方式的维护难度会越来越高。
所以一般认为:
写一些简单的脚本,去做一些一次性任务,用面向过程的方式是极好的;
但如果要处理的任务是复杂的,且需要不断迭代和维护 的, 那还是用面向对象最方便
2、面向对象编程
OOP编程是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,使用面向对象编程的原因一方面是因为它可以使程序的维护和扩展变得更简单,
并且可以大大提高程序开发效率 ,另外,基于面向对象的程序可以使它人更加容易理解你的代码逻辑,从而使团队开发变得更从容。
Class 类
一个类即是对一类拥有相同属性的对象的抽象、蓝图、原型。在类中定义了这些对象的都具备的属性(variables(data))、共同的方法
Object 对象
一个对象即是一个类的实例化后实例,一个类必须经过实例化后方可在程序中调用,一个类可以实例化多个对象,每个对象亦可以有不同的属性,就像人类是指所有人,每个人是指具体的对象,人与人之前有共性,亦有不同
Encapsulation 封装
隐藏功能,外部不能访问;隐藏实现细节,提供外部访问接口
Inheritance 继承
一个类可以派生出子类,父类里定义的属性、方法自动被子类继承
Polymorphism 多态
一个接口,多种实现
| 二、面向对象编程(Object-Oriented Programming )介绍 |
老程序员经验总结:
1.写重复代码是低级行为
2.代码肯定会经常变更
1、类的语法
# 基本规则:函数内局部变量,不能让其他函数调用
# 设计一种方法,类内部函数可以访问构造函数的变量,self class Dog(object):
def __init__(self, name, dog_type): # 初始化函数,即构造函数 self = d
self.name = name # d.name = name
self.dog_type = dog_type # d.dog_type = dog_type def bark(self): # self = d
print("[%s] say: I am a dog." % self.name) def eat(self, food): # self = d
print("[%s] is eating [%s]" % (self.name, food)) d = Dog("Linda", "哈巴") # 对象,d print(d.name, d.dog_type)
d.bark() d.eat("bone") # 等价于 Dog.eat(d, "bone")
Dog.eat(d, "bone")
2、类与实例内存分配
print(Dog) 结果为<class '__main__.Dog'>这代表即使不实例化,这个Dog类本身也是已经存在内存里
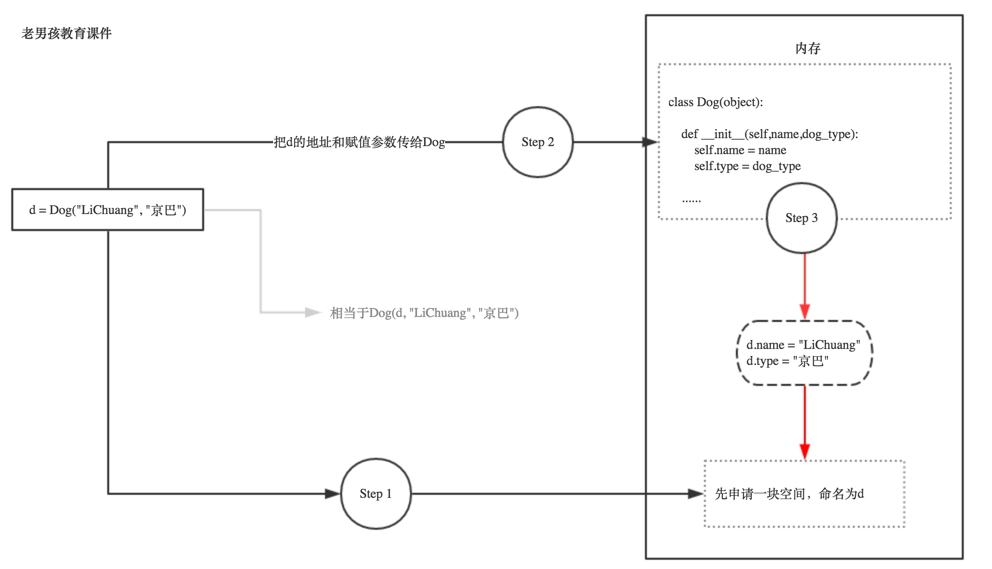
根据上图我们得知,其实self,就是实例本身!你实例化时python会自动把这个实例本身通过self参数传进去
3、构造方法
class Role(object): #定义一个类, class是定义类的语法,Role是类名,(object)是新式类的写法,必须这样写
def __init__(self,name,role,weapon,life_value=100,money=15000): #初始化函数,在生成一个角色时要初始化的一些属性就填写在这里
self.name = name # 即为__init__中的第一个参数self
self.role = role
self.weapon = weapon
self.life_value = life_value
self.money = mone
面的这个__init__()叫做初始化方法(或构造方法),
在类被调用时,这个方法(虽然它是函数形式,但在类中就不叫函数了,叫方法)会自动执行,进行一些初始化的动作,
所以我们这里写的__init__(self,name,role,weapon,life_value=100,money=15000)就是要在创建一个角色时给它设置这些属性
初始化一个角色,就需要调用这个类一次:
r1 = Role('Alex','police','AK47’) # 生成一个角色 , 会自动把参数传给Role下面的__init__(...)方法
r2 = Role('Jack','terrorist','B22’) # 生成一个角色
上面的创建角色时,我们并没有给__init__传值,程序也没未报错,是因为,类在调用它自己的__init__(…)时自己帮你给self参数赋值
r1 = Role('Alex','police','AK47’) # 此时self 相当于 r1, Role(r1,'Alex','police','AK47’)
r2 = Role('Jack','terrorist','B22’) # 此时self 相当于 r2, Role(r2,'Jack','terrorist','B22’)
执行r1 = Role('Alex','police','AK47’)时,python的解释器其实干了两件事:
1、在内存中开辟一块空间指向r1这个变量名
2、调用Role这个类并执行其中的__init__(…)方法,相当于Role.__init__(r1,'Alex','police',’AK47’),这么做是为什么呢
是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,
是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,
是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,
重要的事情说3次, 因为关联起来后,你就可以直接r1.name, r1.weapon 这样来调用啦。
所以,为实现这种关联,在调用__init__方法时,就必须把r1这个变量也传进去,否则__init__不知道要把那3个参数跟谁关联
3、这个__init__(…)方法里的,self.name = name , self.role = role 等等的意思就是要把这几个值 存到r1的内存空间里
4、自定义方法
上面类中的一个buy_gun的方法
def buy_gun(self,gun_name):
print(“%s has just bought %s” %(self.name,gun_name) )
上面这个方法通过类调用的话要写成如下:
r1 = Role('Alex','police','AK47')
r1.buy_gun("B21”) #python 会自动帮你转成 Role.buy_gun(r1,”B21")
依然没给self传值 ,但Python还是会自动的帮你把r1 赋值给self这个参数。
在buy_gun(..)方法中可能要访问r1的一些其它属性, 比如这里就访问 了r1的名字,怎么访问呢?你得告诉这个方法呀,于是就把r1传给了这个self参数,
然后在buy_gun里调用 self.name 就相当于调用r1.name ,如果还想知道r1的生命值 有多少,直接写成self.life_value就可以了
1、上面的这个r1 = Role('Alex','police','AK47’)动作,叫做类的“实例化”,
就是把一个虚拟的抽象的类,通过这个动作,变成了一个具体的对象了, 这个对象就叫做实例
2、刚才定义的这个类体现了面向对象的第一个基本特性,封装。
其实就是使用构造方法将内容封装到某个具体对象中,然后通过对象直接或者self间接获取被封装的内容
| 三、面向对象特性 |
1、封装
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏
2、继承
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。
被继承的类称为“基类”、“父类”或“超类”。
继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。
在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。
继承概念的实现方式主要有2类:实现继承、接口继承。
实现继承是指使用基类的属性和方法而无需额外编码的能力;
接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力(子类重构爹类方法);
在考虑使用继承时,有一点需要注意,那就是两个类之间的关系应该是“属于”关系。
例如,Employee 是一个人,Manager 也是一个人,因此这两个类都可以继承 Person 类。但是 Leg 类却不能继承 Person 类,因为腿并不是一个人。
抽象类仅定义将由子类创建的一般属性和方法。
OO开发范式大致为:划分对象→抽象类→将类组织成为层次化结构(继承和合成) →用类与实例进行设计和实现几个阶段。
继承示例:
#!_*_coding:utf-8_*_
#__author__:"Alex Li" class SchoolMember(object):
members = 0 #初始学校人数为0
def __init__(self,name,age):
self.name = name
self.age = age def tell(self):
pass def enroll(self):
'''注册'''
SchoolMember.members +=1
print("\033[32;1mnew member [%s] is enrolled,now there are [%s] members.\033[0m " %(self.name,SchoolMember.members)) def __del__(self):
'''析构方法'''
print("\033[31;1mmember [%s] is dead!\033[0m" %self.name)
class Teacher(SchoolMember):
def __init__(self,name,age,course,salary):
super(Teacher,self).__init__(name,age)
self.course = course
self.salary = salary
self.enroll() def teaching(self):
'''讲课方法'''
print("Teacher [%s] is teaching [%s] for class [%s]" %(self.name,self.course,'s12')) def tell(self):
'''自我介绍方法'''
msg = '''Hi, my name is [%s], works for [%s] as a [%s] teacher !''' %(self.name,'Oldboy', self.course)
print(msg) class Student(SchoolMember):
def __init__(self, name,age,grade,sid):
super(Student,self).__init__(name,age)
self.grade = grade
self.sid = sid
self.enroll() def tell(self):
'''自我介绍方法'''
msg = '''Hi, my name is [%s], I'm studying [%s] in [%s]!''' %(self.name, self.grade,'Oldboy')
print(msg) if __name__ == '__main__':
t1 = Teacher("Alex",22,'Python',20000)
t2 = Teacher("TengLan",29,'Linux',3000) s1 = Student("Qinghua", 24,"Python S12",1483)
s2 = Student("SanJiang", 26,"Python S12",1484) t1.teaching()
t2.teaching()
t1.tell()
3、多态
Python自动化开发 - 面向对象(一)的更多相关文章
- Python自动化开发 - 面向对象(二)
本节内容 1.isinstance(obj,cls)和issubclass(sub,super) 2.反射 3.__setattr__,__delattr__,__getattr__ 一. isins ...
- python自动化开发学习 进程, 线程, 协程
python自动化开发学习 进程, 线程, 协程 前言 在过去单核CPU也可以执行多任务,操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换任务2,任务2执行0.01秒,在切换到任务3,这 ...
- python自动化开发学习 I/O多路复用
python自动化开发学习 I/O多路复用 一. 简介 socketserver在内部是由I/O多路复用,多线程和多进程,实现了并发通信.IO多路复用的系统消耗很小. IO多路复用底层就是监听so ...
- python自动化开发-[第六天]-常用模块、面向对象
今日概要: 1.常用模块 - os模块 - random模块 - shutil模块 - hashlib模块 - pickle/json模块 - shelve模块 - configparser模块 - ...
- python自动化开发-[第八天]-面向对象高级篇与网络编程
今日概要: 一.面向对象进阶 1.isinstance(obj,cls)和issubclass(sub,super) 2.__setattr__,__getattr__,__delattr__ 3.二 ...
- python自动化开发-[第七天]-面向对象
今日概要: 1.继承 2.封装 3.多态与多态性 4.反射 5.绑定方法和非绑定方法 一.新式类和经典类的区别 大前提: 1.只有在python2中才分新式类和经典类,python3中统一都是新式类 ...
- Python自动化开发-简介
1.Python简介 Python创始人 Guido Van Rossum,人称"龟叔",1989年圣诞节期间,为了在阿姆斯特丹打发时间,开发的一个新的脚本解释程序 作为ABC语 ...
- python自动化开发-1
1.python简介 python是一门简明并且强大的面向对象的开发语言,已经在WEB开发,软件开发,科学计算,大数据分析,自动化运维等领域得到了广泛的应用. 注意:所有测试均已python3为主,与 ...
- 写给深圳首期Python自动化开发周未班的信
你是否做了正确的决定? 深圳首期周未班的同学们大家好,我是Alex, 老男孩教育的联合创始人,Python项目的发起人,51CTO学院连续2届最受学员喜爱的讲师,中国最早一批使用Python的程序员, ...
随机推荐
- linux 使用笔记1
Zox's code life 人生就是不停的战斗! xxx is not in the sudoers file.This incident will be reported.的解决方法 1.切换到 ...
- python多线程下载网页图片并保存至特定目录
#!python3 #multidownloadXkcd.py - Download XKCD comics using multiple threads. import requests impor ...
- JianShu_failban2实现动态屏蔽的功能
一,首先是服务安装 #vim /etc/yum.repos.d/Centos-Base.repo 在最新新增 [atrpms] name=Red Hat Enterprise Linux $relea ...
- Lazarus的二维码解决方案
不解释,直接上图
- SQL注入漏洞总结
目录: 一.SQL注入漏洞介绍 二.修复建议 三.通用姿势 四.具体实例 五.各种绕过 一.SQL注入漏洞介绍: SQL注入攻击包括通过输入数据从客户端插入或“注入”SQL查询到应用程序.一个成功的S ...
- Python 递归函数 详解
Python 递归函数 详解 在函数内调用当前函数本身的函数就是递归函数 下面是一个递归函数的实例: 第一次接触递归函数的人,都会被它调用本身而搞得晕头转向,而且看上面的函数调用,得到的结果会 ...
- 通过flask中的Response返回json数据
使用flask的过程中,发现有时需要生成一个Response并返回.网上查了查,看了看源码,找到了两种办法: from flask import Response, json Response(jso ...
- mybatis-mysql类型映射
JDBC Type Java Type CHAR String VARCHAR String LONGVARCHAR String NUMERIC java.math.BigDecimal DECIM ...
- 【Redis】Redis cluster集群搭建
Redis集群基本介绍 Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施installation. Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行 ...
- mybatis学习三 数据库连接池技术
1.在内存中开辟一块空间,存放多个数据库连接对象.就是Connection的多个实例2. 连接池技术有很多,c3p0,dbcp,druid,以及JDBC Tomcat Pool, JDBC Tomca ...