关于PCA
PCA是常见的降维技术。
对于使用PCA来进行降维的数据,需要进行预处理,是指能够实现均值为0,以及方差接近。如何来确定到底哪个维度是"主成分"?就要某个axis的方差。
为什么要减去均值?目的就是要获取矩阵为0,以及方差相同。为什么均值会为0?
mean = (a + b + c)/3
val = (a - m + b - m + c - m)/3 = (a + b + c)/ 3 - m/3 = 0 => 均值为0
注意,这里均值是指某个特征的,比如某个数据样本有两个特征,那么a,b,c是指其中一个特征的样本值;所以在计算均值的时候需要指定axis = 0,即在纵向上计算均值。

通过上图,我们可以看到,很明显B线的方差最大;然后数据将会做旋转(rotation),然后数据将会在这个轴上面做投影;然后我们再找第二个维度,这个维度需要正交并且垂直于第一个维度(二维世界里面正交和垂直是一个概念),这里线段C,同样的数据还会沿着C轴做旋转,然后做映射。
我理解其实旋转只是一种便于理解的方式,其实就可以理解为将空间中的数据的特征(每个特征都一个维度)要乘以一个数字,将其映射为某个新的维度,之前有N个维度,将会从其中选出一些可以很好覆盖数据的新的维度,将原来的特征做映射,映射到一个新的特征空间中:K维空间(K < N);那么怎么映射,于是就有了旋转这个概念,其实本质就是所有样本的指定特征都乘以一个数(不同的数),这些树也是一个矩阵,以一个用于旋转的矩阵;按照K个维度坐旋转。
现在问题就是如何来获得这个新的特征空间呢?想要求出特征空间就要求出这个旋转矩阵;这个旋转矩阵就可以通过特征值和特征向量来搞掂;求得是什么特征值和特征向量?协方差,至于为什么要用协方差,还记得上面我们提到的:要找到方差最大的角度,其实就是求解上图中两个特征的最大差距,这个可以用协方差来表示。
另外我们简单讲一下特征值和特征向量:Av=λv,描述的是这样数据关系:一个矩阵A左乘矩阵v,等价于一个标量λ*矩阵v。所谓标量值就是一个数(多个数就可以组成一个矩阵就是矢量),但是注意这里λ其实是多个数,但是每一个数都是代表一个独立的解,根据这个独立解可以获得一个特征向量,所以特征值和特征向量是一一对应的关系;特征值他们之间的关系并不能组成矩阵(具体可以参见《线性代数》特征值和特征向量章节)。对于特征值和特征向量一般应用的场景是A已知,求λ和v,前者就是特征值,后者就是特征向量。
在PCA算法中,协方差就是那个矩阵A,根据矩阵A可以求出λ和v;λ大小可以方便的判断坐标轴的方差大小,根据λ的大小我们可以推测出对应的特征向量的(旋转角度)数据的方差排序;很多场景下排名靠前的特征向量可以包揽大部分的方差,后面的特征向量(旋转角度)所占用的份额非常小,基本可以忽略不计。
这里牵涉到一个问题,怎么计算这个份额,还是使用特征值:
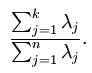
注意:上面采用特征值来评估特征向量的排序,这里还是使用特征向量来计算份额,我们其实可以这么来理解特征值,其实他就是特征向量的一个缩影(特征向量的计算和特征值密切相关)。再回到份额,我们可以根据上面的公式来计算份额。那么这里牵涉到了一个问题,就是如何来获取主成分的数量?根据份额;比如我们打算保留98%的份额,那么就逐个添加特征值(此时的特征值已经是按照从大到小排列),直到份额达到了比例。
from numpy import mean
from numpy import linalg
from numpy import argsort
from numpy import cov # 哪里看出来是降维呢?降维的依据又是什么呢?注意,eigValInd最后只是取值前topNfeat个成分
def PCA(dataMat, topNfeat=99999):
# 计算方差,然后用原始数据集-均值,减去均值目的就是要计算方差,为下一步求解协方差矩阵做准备
# 求解完协方差之后,就可以利用协方差值来求特征值以及特征矩阵
meanValue = mean(dataMat, axis = 0)
print("meanValue: ", meanValue)
# 源数据减去均值,整个特征的特征均值为0
meansRemoved = dataMat - meanValue
print("meansRemoved: ", meansRemoved)
covMat = cov(meansRemoved, rowvar=0)
print("covMat: ", covMat)
eigVals, eigVects = linalg.eig(mat(covMat))
print("eigVals: \n", eigVals)
print("eigVects: \n", eigVects)
# 对特征值进行排序,并基于此来获取特征向量,之所以通过-1来取倒序,是因为要按照特征权重从大到小获取
eigValInd = argsort(eigVals)
print("eigValInd: ", eigValInd)
eigValInd = eigValInd[:-(topNfeat+1):-1]
print("eigValInd sorted: ", eigValInd)
regeigVects = eigVects[:, eigValInd]
print("regeigVects: ", regeigVects)
# 获取降维之后的数据,以及逆运算推出原始数据
lowDDataMat = meansRemoved * regeigVects
reconMat = (lowDDataMat * regeigVects.T) + meanValue return lowDDataMat, reconMat
上面的一段代码中第28,29行其实并不是很懂,为什么分别计算lowDDataMat和reconMat?从是应用来看其实最终降维后,参与运算的数据是reconMat。
下面就是最后一个问题:如何对于降维后数据进行还原?降维的本质其实就是将非核心特征设置值为0;我们在算法一般会把把0值添加回去,而是直接采用xHat * Uk(xHat是旋转以后降维数据,Uk是特征向量空间的前K个向量)
参考:
解释特征矩阵和特征向量
http://mini.eastday.com/bdmip/180328092726628.html#
关于主成分分析
《机器学习实战》 Peter
关于PCA的更多相关文章
- 用scikit-learn学习主成分分析(PCA)
在主成分分析(PCA)原理总结中,我们对主成分分析(以下简称PCA)的原理做了总结,下面我们就总结下如何使用scikit-learn工具来进行PCA降维. 1. scikit-learn PCA类介绍 ...
- 主成分分析(PCA)原理总结
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一.在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用.一般我们提到降维最容易想到的算法就 ...
- 机器学习基础与实践(三)----数据降维之PCA
写在前面:本来这篇应该是上周四更新,但是上周四写了一篇深度学习的反向传播法的过程,就推迟更新了.本来想参考PRML来写,但是发现里面涉及到比较多的数学知识,写出来可能不好理解,我决定还是用最通俗的方法 ...
- 数据降维技术(1)—PCA的数据原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 深度学习笔记——PCA原理与数学推倒详解
PCA目的:这里举个例子,如果假设我有m个点,{x(1),...,x(m)},那么我要将它们存在我的内存中,或者要对着m个点进行一次机器学习,但是这m个点的维度太大了,如果要进行机器学习的话参数太多, ...
- PCA、ZCA白化
白化是一种重要的预处理过程,其目的就是降低输入数据的冗余性,使得经过白化处理的输入数据具有如下性质:(i)特征之间相关性较低:(ii)所有特征具有相同的方差. 白化又分为PCA白化和ZCA白化,在数据 ...
- PCA 协方差矩阵特征向量的计算
人脸识别中矩阵的维数n>>样本个数m. 计算矩阵A的主成分,根据PCA的原理,就是计算A的协方差矩阵A'A的特征值和特征向量,但是A'A有可能比较大,所以根据A'A的大小,可以计算AA'或 ...
- 【统计学习】主成分分析PCA(Princple Component Analysis)从原理到实现
[引言]--PCA降维的作用 面对海量的.多维(可能有成百上千维)的数据,我们应该如何高效去除某些维度间相关的信息,保留对我们"有用"的信息,这是个问题. PCA给出了我们一种解决 ...
- 主成分分析 (PCA) 与其高维度下python实现(简单人脸识别)
Introduction 主成分分析(Principal Components Analysis)是一种对特征进行降维的方法.由于观测指标间存在相关性,将导致信息的重叠与低效,我们倾向于用少量的.尽可 ...
- PCA与LDA的区别与联系
由于涉及内容较多,这里转载别人的博客: http://blog.csdn.net/sunmenggmail/article/details/8071502 其实主要在于:PCA与LDA的变换矩阵不同, ...
随机推荐
- input(Text)控件作为填空输入,但运行后,有曾经输入的记录显示,用autocomplete="off"解决
系统中,有设计填空题,原来程序中,用input(Text)控件, <input type="text" name="NO<%=rs("id&qu ...
- 运行 vue 报node错
当报错 为这样时: 执行--npm install node-sass 即可
- 关于MySQL5.7 这几天的总结(json类型)
一开始,老板让调整一下 innodb_buffer_pool_size 大小,因为这台机器内存大. 看了下内存,16G,再SQL下面命令,得到结果是4G. SELECT @@innodb_buffer ...
- python之django母板页面
其实就是利用{% block xxx %} {% endblock %}的方式定义一个块,相当于占位.存放在某个html中,比如base.html 然后在需要实现这些块的文件中,使用继承{% ex ...
- 马凯军201771010116《面向对象与程序设计Java》
实验十八 总复习 实验时间 2018-12-30 1.实验目的与要求 (1) 综合掌握java基本程序结构: (2) 综合掌握java面向对象程序设计特点: (3) 综合掌握java GUI 程序设 ...
- 使用mbedtls的使用说明和AES加密方法(原来的PolarSSL)
关于PolarSSL mbed TLS(以前称为PolarSSL)是TLS和SSL协议的实现,并且需要相应的加密算法和支持代码.这是双重许可与Apache许可证 2.0版(与GPLv2许可也可).网站 ...
- 微信小程序scroll-view滚动一次多次触发的问题解决方案
最近使用微信小程序开发的时候,需要用scroll-view的bindscrolltolower事件,控制加载下一页的内容.但是发现在ios里,下拉滚动一次,事件触发两次,导致重复加载数据. 经过百度和 ...
- 自动化测试-17.selenium数据的分离之txt文本的写入与读取
前言 数据量偏小时,用txt文本保存数据比较合适,以-进行区分,为什么不用:呢?原因是,我们在使用数据时,会存在url地址的情况,里面宝行:所以用-进行替代 此处附上代码 #encoding=utf- ...
- 理解JavaScript中的属性描述符
我们把描述JavaScript中定义内部特性的属性叫做属性描述符 分为两大类:数据描述符和存取描述符 数据描述符是一个拥有可写或不可写的属性(Writable); 存取描述符不包含数据值,是一组拥有g ...
- 随手小代码——Python 从集合中随机抽取元素
=================================版权声明================================= 版权声明:原创文章 谢绝转载 请通过右侧公告中的“联系邮 ...