语音通信中终端上的时延(latency)及减小方法
时延是语音通信中的一个重要指标,当端到端(end2end)的时延(即one-way-delay,单向时延)低于150Ms时人感觉不到,当端到端的时延超过150Ms且小于450Ms时人能感受到但能忍受不影响通话交流,当端到端的时延大于1000Ms时严重影响通话交流,用户体验很差。同时时延也是语音方案过认证的必选项,超过了规定值这个方案是过不了认证的。今天我们就讲讲时延是怎么产生的以及怎么样在通信终端上减小时延。
1,时延产生
下图是语音从采集到播放的传输过程。
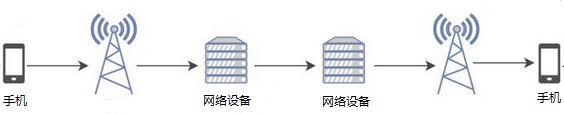
从上图看出,传输过程包括三部分,一是从发送端采集到语音数据处理后发送到网络设备,二是网络设备之间传送,三是从网络设备发送给接收端并播放出来。每个过程都会产生时延,总体可以分为三类。一是通信终端上引入的时延,这时本文要讲的重点,后面具体讲。二是通信终端和网络设备之间的时延,包括采集终端到网络设备的延时和网络设备到播放设备的延时。三是网络设备之间的时延。二和三属于网络设备引入的延时,本文不讨论。
现在我们具体看通信终端上引入的时延,它在发送端(或者叫上行/TX)和接收端(或者叫下行/RX)都有。在发送端主要包括声音的采集引入的延时、前处理算法引入的延时和编码算法引入的时延。声音采集时通常5Ms或者10Ms从采集DMA中取一次语音数据,但是编码时多数codec要求的一帧是20Ms(比如AMR-WB),这两者之间不匹配,就要求采集到的数据放在buffer里缓一段时间,等到帧长时再取出来去编码,这就引入了时延。以一帧20Ms为例,就会引入20Ms的延时。前处理算法主要有AEC、ANS、AGC,这些算法都会引入延时,这跟滤波器的阶数有关,阶数越多,延时越大。编码算法同前处理算法一样也引入了延时。在接收端主要包括端网络延时、解码算法延时、后处理算法延时和播放延时。端网络延时主要出现在解码之前的jitter buffer内,如果有抗丢包处理(例如FEC)延时还会增加(有FEC增加延时的原因是要等接收到的包到指定个数才能做FEC解码还原出原始包,用FEC抗丢包的原理我在前面的文章(语音通信中提高音质的方法)中写过)。解码和后处理算法和发送端的编码前处理类似有延时。播放前为了保持播放的流畅性会在语音数据进播放DMA前加一级buffer,这也引入了延时。
2,时延测量
时延是过认证的必选项。对于语音通信解决方案来说,先得让时延低于认证指定的值,然后再看有没有减小的可能。如可以将时延做到更小,则是该方案的亮点。要测量时延就得在实验室搭建一个理想的端到端的语音通信系统(理想是指网络几乎不引入时延),同时两端均采用该语音方案,这样就可以用仪器测出端到端的延时了。测时延时,仪器上显示的时延是一个平均值,等通话时长达到一定值后就会稳定下来。拿它跟认证指定的值比较,如果大于指定值,认证是过不了的,先要减小时延让它低于指定值。如果低于指定值,则说明该方案有一个好的起点,可以继续减小让其成为亮点。
用仪器测出来的单向时延大体上应该是终端上各个模块引入的时延之和。要减小时延首先得搞清楚是哪个模块引入的时延较大。有些模块引入的时延是已知固定的,且不能减少,比如信号处理算法模块。有些模块引入的时延是未知的,我们就需要去测量这个模块引入的时延具体是多少。做这些前需要对该语音通信方案的软件架构熟悉,知道方案中有几个(除了信号处理算法模块外)引入时延的点。这种时延通常是对buffer的存取引入的时间差,该怎么测出时延值呢?我一般用如下的方法:当把语音数据放进buffer时记下当时的时间t1,保存在这段数据开始的地方(虽然破坏了语音数据,不过没关系,我们只是用来测延时,是一种手段,不关心语音质量),当从buffer中取出这段语音数据时,再记录下时间t2,将t2减去保存在数据中的t1就得到本次存取引入的延时。统计非常多次(我通常用一万次)再算平均值,就可以得到这个点引入的时延了。下面举例说明。有一块可以存5帧(每帧20Ms)的buffer,某一帧语音数据放在第三帧处。放时的时间是158120毫秒,将这个值放在放这段数据开始的地方。将这段数据从buffer里取出来时的时间是158180秒,可以算出本次延时是60Ms(158180-158120=60),统计10000次,算出延时总和,再除以10000,得到延时平均值是58Ms。所以这个点引入的时延是58Ms。
3,时延的减小方法
知道了各个点引入的时延大小,下面就要看怎么减小时延了。这里的减小是指能减小的,有些是不能减小的,比如codec引入的时延。我用过的方法主要有以下两种。
1)用减小缓冲深度来减小时延
这种方法说白了就是让语音数据在buffer里呆的时间短些,比如以前在buffer里有了3帧(假设每帧20Ms)语音数据才会从buffer中取出给下一模块,这样平均就会引入60Ms的时延。如果将3帧改为2 帧,则平均引入的时延就降为40Ms,这样就减少了20Ms的时延。不过用这种方法是有条件的,要确保语音质量不下降。改了后要用仪器测,如果长时测试下语音质量不下降就说明这个改后的值是可以接受的。经过试验后找到一个可以接受的缓冲深度的最小的值,就把这个值用在方案中。
2)用加速信号处理算法来减少时延
音频信号处理中有个算法叫加速,它是对PCM信号进行处理,在不丢失语音信息的前提下把时长减小,它的原理是WSOLA。比如原PCM数据时长是5秒,经过加速处理后变成了4秒,人听上去信息没丢失,但是语速变快了。如果在buffer中待播放的PCM数据较长,肯定延时较大,可以通过这种加速算法把要播放的数据处理一下,变成短时长的PCM数据,这样就可以减小延时了。我第一次做voice engine的时候,除了减小buffer缓冲深度没有其他好的方法来减小延时。后来做了语音加速播放的功能(具体见我前面的文章:音频处理之语音加速播放),觉得可以用这个算法来减小延时。可是当时事情非常多,再加上要做到延时减小了但同时也要让听者感觉不到在加速播放还有很多细节工作要做,也就没做成。随着webRTC风靡音视频开发圈,我也开始关注。了解到其中的netEQ就有用加速算法来减小延时的功能,看来英雄所见略同啊。哈哈。同时我也感觉到要多做东西,见多才能识广呀,说不定结合以前做过的东西就能得到解决问题的好的思路呢。当然加速减少延时功能只是netEQ的一部分。netEQ主要是解决网络抖动延时丢包等问题来提高语音质量的,可以说说目前公开的处理此类问题的最佳方案了。从下篇开始,我将花几篇文章来详细的讲讲netEQ。netEQ是webRTC中音频相关的两大核心技术之一(另一个是前后处理,有AEC/ANS/AGC等),很值得研究。
语音通信中终端上的时延(latency)及减小方法的更多相关文章
- 谈谈语音通信中的各种tone
今天谈的这个主题(tone)存在于我们的日常打电话过程中.先举两个场景:1,你拿起固话话筒准备打电话,按电话号码前先从话筒里听到"嗡"的连续音,这叫dial tone(拨号音,表示 ...
- python中获取上一个月一号的方法
业务场景: 我们经常会跑一些月级别或者周级别的报表. 周级别的报表还比较好确定,就是七天前的直接用timedelta(days=7)来获取开始日期就可以了; 但是月级别的报表就要麻烦一些,因为time ...
- 浅谈传统语音通信和APP语音通信音频软件开发之不同点
本人在传统的语音通信公司做过手机和IP电话上的语音软件开发,也在移动互联网公司做过APP上的语音软件开发.现在带实时语音通信功能的APP有好多,主流的有微信语音.QQ电话.钉钉等,当然也包括我开发过的 ...
- 如何在嵌入式Linux上开发一个语音通信解决方案
开发一个语音通信解决方案是一个软件项目.既然是软件项目,就要有相应的计划:有多少功能,安排多少软件工程师去做,这些工程师在这一领域的经验如何,是否需要培训,要多长时间做完,中间有几个主要的milest ...
- C# 最基本的涉及模式(单例模式) C#种死锁:事务(进程 ID 112)与另一个进程被死锁在 锁 | 通信缓冲区 资源上,并且已被选作死锁牺牲品。请重新运行该事务,解决方案: C#关闭应用程序时如何关闭子线程 C#中 ThreadStart和ParameterizedThreadStart区别
C# 最基本的涉及模式(单例模式) //密封,保证不能继承 public sealed class Xiaohouye { //私有的构造函数,保证外部不能实例化 private ...
- 腾讯云H5语音通信QoE优化
本文首发在云+社区,未经许可,不得转载. 云+导语:4月21日,腾讯云+社区在京举办"'音'你而来,'视'而可见--音视频技术开发实战沙龙",腾讯音视频实验室高级工程师张轲围绕网络 ...
- 串口通信中ReadFile和WriteFile的超时详解!
源:串口通信中ReadFile和WriteFile的超时详解! 在用ReadFile和WriteFile读写串行口时,需要考虑超时问题.如果在指定的时间内没有读出或写入指定数量的字符,那么ReadFi ...
- Android IOS WebRTC 音视频开发总结(七五)-- WebRTC视频通信中的错误恢复机制
本文主要介绍WebRTC视频通信中的错误恢复机制(我们翻译和整理的,译者:jiangpeng),最早发表在[这里] 支持原创,转载必须注明出处,欢迎关注我的微信公众号blacker(微信ID:blac ...
- 使用SSL确保通信中的数据安全
#region Server /// <summary> /// 用于保存非对称加密(数字证书)的公钥 /// </summary> private string public ...
随机推荐
- WEB 设计规范
WEB端设计规范 一.网页尺寸 一般网站宽为996px:国内网站大部分还是以1000个像素为界限,因超过1000像素适合在大屏幕上浏览,小屏幕会显得拥挤.国内尺寸设置比较保守,这样可以保证 ...
- MySQL 使用join操作时出现重复数据
使用 group by 'id'' 如:SELECT e.* FROM excel e INNER JOIN task t ON t.eid=e.id where e.id>0 and t. ...
- IDEA创建简单SpringBoot项目
环境:jdk 1.打开IDEA -->New --> Project -->Spring Initalizer-->next 2.此处,只做创建示例,所以next后Group等 ...
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- 前端开发:一个开源、简单易用的jQuery表格插件(DataTables)
DataTables是一个基于jQuery库的开源(MIT协议)表格插件,支持添加.排序.分页.搜索.过滤等功能,使用简单.广受欢迎,能够与主流前端UI整合(如bootstrap.jQuery UI等 ...
- Feign源码解析系列-最佳实践
前几篇准备写完feign的源码,这篇直接给出Feign的最佳实践,考虑到目前网上还没有一个比较好的实践解释,对于新使用spring cloud的同学会对微服务之间的依赖产生一些迷惑,也会走一些弯路.这 ...
- spark学习笔记_1
简单的讲,Apache Spark是一个快速且通用的集群计算系统. Apache Spark 历史: 2009年由加州伯克利大学的AMP实验室开发,并在2010年开源,13年时成长为Apache旗下大 ...
- 右键菜单添加包含ICON图片的快捷打开方式
右键菜单添加包含ICON图片的快捷打开方式: ①保存如下代码为“submit.reg”, ②修改对应的程序地址 ③双击创建的文件,导入到注册表中,即可 Windows Registry Editor ...
- Python之简单验证码实现
def v_code(): ret = '' for i in range(5): num = random.randint(0,9) alf = chr(random.randint(65,122) ...
- 根据某字段将其他字段进行拼接的两种方法(SYS_CONNECT_BY_PATH及wm_concat)
秘书姐姐说想知道她发起的所有流程,现在都到谁审批了.由于一条流程当前审批人可能有多个,故需根据单据编号(djbh)将审批人拼接到一个字段中. 说明: wfn审批历史记录表,djbh 单据编号,pk_c ...