【Python3爬虫】网易云音乐歌单下载
一、目标:
下载网易云音乐热门歌单
二、用到的模块:
requests,multiprocessing,re。
三、步骤:
(1)页面分析:首先打开网易云音乐,选择热门歌单,可以看到以下歌单列表,然后打开开发者工具
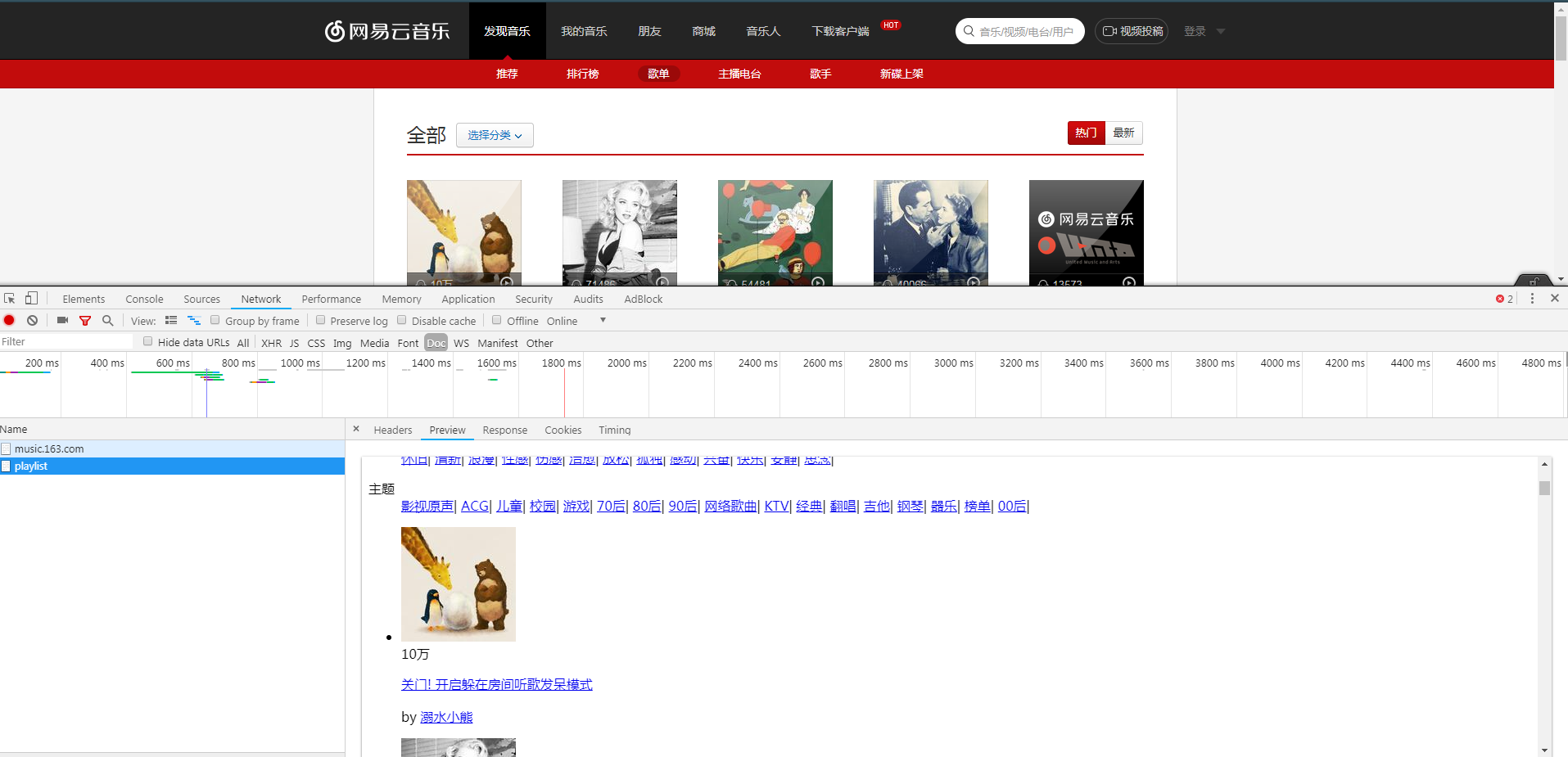

因此我们需要请求的url就是https://music.163.com/discover/playlist,然后用requests.get()方法请求页面,对于返回的结果,用正则表达式进行解析,得到歌单名字和歌单id,解析的正则表达式如下:
res = requests.get(url, headers=headers)
data = re.findall('<a title="(.*?)" href="/playlist\?id=(\d+)" class="msk"></a>', res.text)
(2)得到歌单名字和歌单id后,构造歌单的url,然后模仿步骤(1)可以得到歌曲名字和歌曲id,解析的正则表达式如下:
re.findall(r'<a href="/song\?id=(\d+)">(.*?)</a>', res.text)
再得到歌曲id后,构造歌曲的url,然后用requests.get().content方法下载歌曲,歌曲的url构造方法如下:
"http://music.163.com/song/media/outer/url?id=%s" %(歌曲id)
(3)由于部分歌曲的名字并不能作为文件名保存下来,所以用到了try...except,对于不能保存为文件名的歌曲,我选择pass掉==
(4)因为要下载多个歌单,一个歌单里又有很多歌曲,所以用到了multiprocessing模块的Pool方法,提高程序运行的效率。
四、具体代码
因为下载所有歌单会需要很长时间,所以我们先下载前三个歌单试试==
import requests
import re
from multiprocessing import Pool headers = {
'Referer': 'https://music.163.com/',
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 "
"Safari/537.36"
} def get_page(url):
res = requests.get(url, headers=headers)
data = re.findall('<a title="(.*?)" href="/playlist\?id=(\d+)" class="msk"></a>', res.text) pool = Pool(processes=4)
pool.map(get_songs, data[:3])
print("下载完毕!") def get_songs(data):
playlist_url = "https://music.163.com/playlist?id=%s" % data[1]
res = requests.get(playlist_url, headers=headers)
for i in re.findall(r'<a href="/song\?id=(\d+)">(.*?)</a>', res.text):
download_url = "http://music.163.com/song/media/outer/url?id=%s" % i[0]
try:
with open('music/' + i[1]+'.mp3', 'wb') as f:
f.write(requests.get(download_url, headers=headers).content)
except FileNotFoundError:
pass
except OSError:
pass if __name__ == '__main__':
hot_url = "https://music.163.com/discover/playlist/?order=hot"
get_page(hot_url)
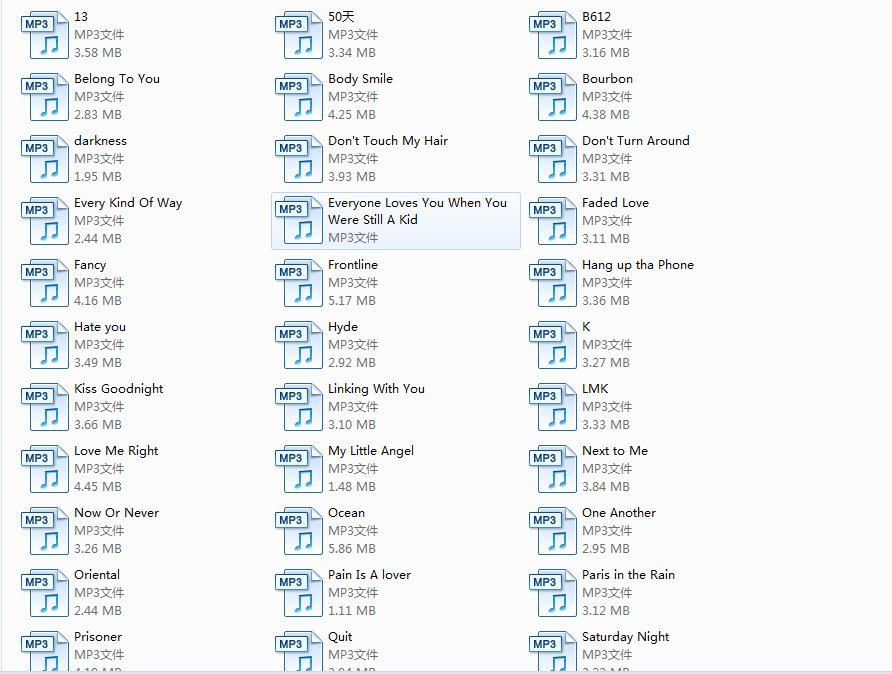
五、运行结果
【Python3爬虫】网易云音乐歌单下载的更多相关文章
- 使用python3下载网易云音乐歌单歌曲,附源代码
""" 用selenium+PhantomJS配合,不需要进行逆向工程 python 3下的selenium不能默认安装,需要指定版本2.48.0 "" ...
- python爬取网易云音乐歌单音乐
在网易云音乐中第一页歌单的url:http://music.163.com/#/discover/playlist/ 依次第二页:http://music.163.com/#/discover/pla ...
- python3爬虫-网易云排行榜,网易云歌手及作品
import requests, re, json, os, time from fake_useragent import UserAgent from lxml import etree from ...
- 《云阅》一个仿网易云音乐UI,使用Gank.Io及豆瓣Api开发的开源项目
CloudReader 一款基于网易云音乐UI,使用GankIo及豆瓣api开发的符合Google Material Desgin阅读类的开源项目.项目采取的是Retrofit + RxJava + ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 网易云音乐 歌词制作软件 BesLyric (最新版本下载)
导读 BesLyric , 一款专门制作 网易云音乐 LRC 滚动歌词的软件! 搜索.下载.制作 歌词更方便! 哈哈,喜欢网易云音乐,又愁于制作歌词的童鞋有福啦!Beslyric 为你排忧解难! 本文 ...
- 在Ubuntu18.04.2LTS上使用wine安装qq,微信,迅雷,百度网盘,网易云音乐等软件
在Ubuntu18.04.2LTS上使用wine安装qq,微信,迅雷,百度网盘,网易云音乐等软件 一.前言 在Linux上办公有一点一直是大家的痛,那就是这些系统上没有我们常用的一些软件,比如QQ,微 ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
- 【Python3爬虫】网易云音乐爬虫
此次的目标是爬取网易云音乐上指定歌曲所有评论并生成词云 具体步骤: 一:实现JS加密 找到这个ajax接口没什么难度,问题在于传递的数据,是通过js加密得到的,因此需要查看js代码. 通过断掉调试可以 ...
随机推荐
- 【转】Socket接收字节缓冲区
原创本拉灯 2014年04月16日 10:06:55 标签: socket / 数据包 4448 我们接收Socket字节流数据一般都会定义一个数据包协议( 协议号,长度,内容),由于Socket接收 ...
- 针对 jQuery Gridly 控件显示多少列的问题。
针对 jQuery Gridly 控件显示多少列的问题,完全根据 columns 的值来显示. 但是显示columns,并不是给多少值显示几列.到目前还是很模糊的.官方文档没有给出具体的一个解释. $ ...
- may be a diary?
[About Me] SD某弱校高二的OIer. qq 995681518,欢迎一起交流~ 喵喵喵喵喵 "当你想要颓废的那一刻,想一想当初为什么走到了这里." 以下文字充满负面情绪 ...
- Makefile自学
MakeFile的规则 如果这个工程没有编译过,那么我们的所有C文件都要编译并被链接. 如果这个工程的某几个C文件被修改,那么我们只编译被修改的C文件,并链接目标程序. 如果这个工程的头文件被改变了, ...
- AppImage格式安装包使用
AppImage(以及前身klik和portablelinuxapps)不会安装传统意义上的软件(即它不会将文件放在系统中的所有位置). 它每个应用程序使用一个文件.每个都是自包含的:它包括应用程序所 ...
- opencv imwrite保存图片花屏的问题
问题:在项目中用opencv的imwrite保存图片出现花屏的问题,如下图: 思路:1. 因为项目中的图像数据(float类型,0-255)是在GPU中,保存的话:可以用CPU保存图片,也可以用GP ...
- [BZOJ1925][SDOI2010]地精部落(DP)
题意 传说很久以前,大地上居住着一种神秘的生物:地精. 地精喜欢住在连绵不绝的山脉中.具体地说,一座长度为 N 的山脉 H可分 为从左到右的 N 段,每段有一个独一无二的高度 Hi,其中Hi是1到N ...
- c# Winform Invoke 的用法
在Winform中线程更新UI线程 例如:Form中有一个DataGridView,我们使用Thread查询后,更新这个表格,如果在Thread中直接更新会报错. Thread th = new Th ...
- JDK各个版本的新特性
对于很多刚接触java语言的初学者来说,要了解一门语言,最好的方式就是要能从基础的版本进行了解,升级的过程,以及升级的新特性,这样才能循序渐进的学好一门语言.今天先为大家介绍一下JDK1.5版本到JD ...
- 全志a20安卓电视盒子安装可道云kodexplorer服务-编译安装php7.3+nginx
可道云真的很强大,安装包很小,功能却很齐全,还可以自定义轻应用如果有手机客户端就更好了 研究了一下,可道云根目录放到外置存储设备(移动硬盘)会更合适,改路径的方法下面有提到上传文件时一个文件会在用户目 ...