决策树 Decision Tree
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
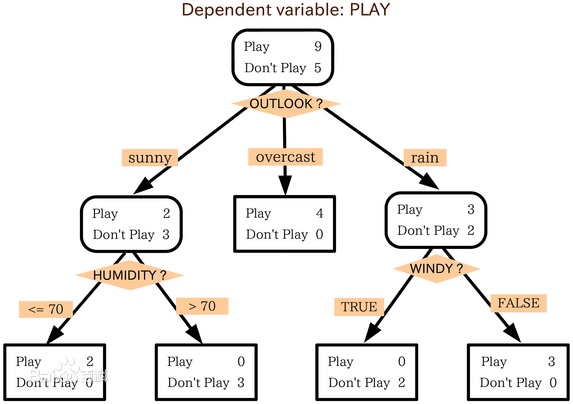 

决策树的构建
想要构建一个决策树,那么咱们首先就需要有一定的已知信息来作为决策树的构建依据。
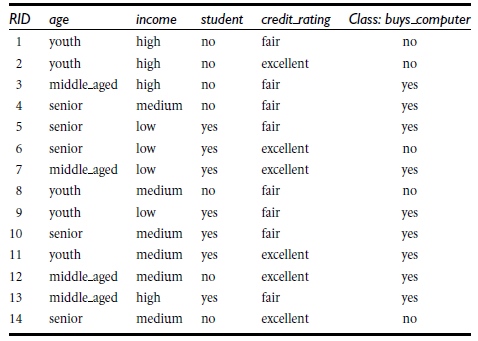
我们采用下图的数据来进行构建 决策树
一个完整的数据应该包括数据特征和对应的决策信息
下表中的数据,代表对购买电脑的客户信息的记录,分为age/imcome/student...等信息
在该数据源中,age 到 credit_rating 这4列称为特征,最后的class:buys_computer 代表最终的决策信息

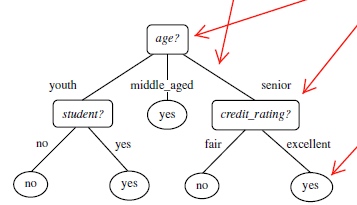
首先选择一个节点为开始(age),再根据该节点往下拓展,分为youth,middle_aged,seniors
根据这三类去上图的数据源检索,可以得出 当middle_aged时,clas_lable全部为yes,所以该分支就结束了。
重复上面的流程...知道最后的节点都是 决策结果信息

信息熵
流程和基本原理了解后,我们就要考虑一个问题:
信息,如何度量?
1948年,香农提出了 ”信息熵(entropy)“的概念
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少
例子:猜世界杯冠军,假如一无所知,猜多少次?
每个队夺冠的几率不是相等的
信息熵用 比特(bit) 来衡量信息的多少
信息熵公式为:
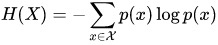 

大写X代表信息集合
小写x代表集合中的某一
p(x)代表概率
假设 X={A,B,C}
A概率为0.2,
B概率为0.4,
C概率为0.6
那么计算结果为
-0.2 * log 0.2 +
-0.4 * log 0.4 +
-0.6 * log 0.6 的和
策树归纳算法 (ID3)
ID3算法是根据信息获取量(Information Gain):
Gain(A) = Info(D) - Infor_A(D)
通过A来作为节点分类获取了多少信息
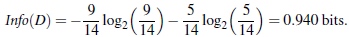 

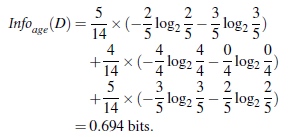 

类似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
代码实现
数据源为第一个表格的数据
# 决策树
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
import pydotplus
# Read csv file
allElectronicsData = open('AllElectronics.csv','r')
csvReader = csv.reader(allElectronicsData)
# csvList = [ r for r in csvReader]
# print(csvList)
# 取头
headers = next(csvReader)
# print(headers)
featureList =[] #特征
labelList = [] #头
# 字典化所有特征
for row in csvReader:
labelList.append(row[len(row) - 1])
rowDic = {}
for i in (range(1,len(row)-1)):
rowDic[headers[i]] = row[i]
# print(rowDic)
featureList.append(rowDic)
print(featureList)
print(labelList)
# 矢量化 特征
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:")
print(str(dummyX))
print(vec.get_feature_names())
# 矢量化 class label
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:")
print(dummyY)
# 构建决策树
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(dummyX,dummyY)
print("clf: ")
print(str(clf))
# 查看决策树
csvDot = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=None)
graph = pydotplus.graph_from_dot_data(csvDot)
graph.write_pdf('1.pdf')
# Image(graph.create_png())
# 使用决策树计算
# 这里直接使用已经矢量化完事的数据来修改一下 进行预测,正常应该采用原始数据进行预处理后 进行预测
new_Data = dummyX[0, :]
print(dummyX[0, :])
# print(new_Data)
new_Data[0] = 0
new_Data[2] = 1
# print(new_Data)
# 预测该数据
predictedY = clf.predict([new_Data])
print(predictedY)
决策树 Decision Tree的更多相关文章
- 机器学习算法实践:决策树 (Decision Tree)(转载)
前言 最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象.本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决 ...
- 数据挖掘 决策树 Decision tree
数据挖掘-决策树 Decision tree 目录 数据挖掘-决策树 Decision tree 1. 决策树概述 1.1 决策树介绍 1.1.1 决策树定义 1.1.2 本质 1.1.3 决策树的组 ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习方法(四):决策树Decision Tree原理与实现技巧
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 前面三篇写了线性回归,lass ...
- 机器学习-决策树 Decision Tree
咱们正式进入了机器学习的模型的部分,虽然现在最火的的机器学习方面的库是Tensorflow, 但是这里还是先简单介绍一下另一个数据处理方面很火的库叫做sklearn.其实咱们在前面已经介绍了一点点sk ...
- 【机器学习算法-python实现】决策树-Decision tree(2) 决策树的实现
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 接着上一节说,没看到请先看一下上一节关于数据集的划分数据集划分.如今我们得到了每一个特征值得 ...
随机推荐
- 微信小程序视频学习笔记
[清华大学]学做小程序 https://www.bilibili.com/video/av21987398 2.2创建项目和文件结构 小程序包含一个描述整体程序的app和多个描述各自页面的page 配 ...
- Capslock+ 键盘党都爱的高效利器 - 让 Windows 快捷键操作更加灵活强大
Capslock+ 键盘党都爱的高效利器 - 让 Windows 快捷键操作更加灵活强大 优化辅助 Windows 2016-06-05 91,167 微博微信QQ空间印象有道邮件 ...
- Java String类的intern()方法
该方法的作用是把字符串加载到常量池中(jdk1.6常量池位于方法区,jdk1.7以后常量池位于堆) 在jdk1.6中,该方法把字符串的值复制到常量区,然后返回常量区里这个字符串的值: 在jdk1.7里 ...
- leetcode-求众数
题目:求众数 给定一个大小为 n 的数组,找到其中的众数.众数是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素. 你可以假设数组是非空的,并且给定的数组总是存在众数. 示例 1: 输入: [3,2,3 ...
- Cordova打包vue项目生成Apk (解决cordova build android抛出的zip问题)
最近对vue前端框架情有独钟.但研究了一下怎么把vue项目打包成android apk来玩玩. 首先讲一下创建vue2.x项目.其实在之前的文章中都有写过,有兴趣的同学可以去看看.http://www ...
- echarts-for-react 从新渲染数据
<ReactEcharts option={option} notMerge={true} style={{height: '600px', width: '100%'}} className ...
- php使用protobuf3
protoc的介绍,安装 1.定义一个protoc 文件 示例:person.proto syntax="proto3"; //声明版本,3x版本支持php package tes ...
- 常用输入的js验证
身份证 var idnub = document.getElementById('idnub').value; if(idnub.length > 1){ var reg = /(^\d{15} ...
- spring-security权限管理学习目标
1.SVN基本介绍: 1.svn基本的概念 2.svn架构 3.svn下载与安装 4.svn搭建与基本操作 2.svn基本操作 1.操作1 2.操作2 3.冲突产生 4.冲突解决 3.SVN在IDEA ...
- windows10下Kafka环境搭建
内容小白,包含JDK+Zookeeper+Kafka三部分.JDK:1) 安装包:Java SE Development Kit 9.0.1 下载地址:http://www.oracle ...