Kasaraju算法--强连通图遍历及其python实现
在理解有向图和强连通分量前必须理解与其对应的两个概念,连通图(无向图)和连通分量。
连通图的定义是:如果一个图中的任何一个节点可以到达其他节点,那么它就是连通的。
例如以下图形:
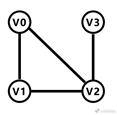
这是最简单的一个连通图,即使它并不闭合。由于节点间的路径是没有方向的,符合从任意一个节点出发,都可以到达其他剩余的节点这一条件,那么它就是连通图了。
连通分量

显然这也是一个图,只不过是由三个子图组成而已,但这并非一个连通图。这三个子图叫做这个图的连通分量,连通分量的内部归根还是一个连通图。
有向图:
在连通图的基础上增加了方向,两个节点之间的路径只能有单一的方向,即要么从节点A连向节点B,要么从节点B连向节点A。有向图与连通图(更准确来说是无向图)最大的区别在于节点之间的路径是否有方向。
有向图也分两种,一种是有环路的有向图。另外一种是无环路的有向图,即通常所说的有向无环图DAG(Directed Acyclic Graph)。严格来说,第一种有环路的图,如果任意一个节点都可以与其他节点形成环路,那么它也是一个连通图。
例如下面的就为一个有向图同时也是连通图:
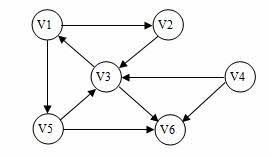
强连通分量
强连通分量SCCs(strongly connected components)是一种有向的连通图。
如果一个图的连通分量是它里面所有节点到能够彼此到达的最大子图,那么强连通分量SCCs就是一个有向图中所有节点能够彼此到达的子图。
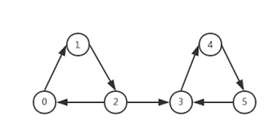
显然由345组成的子图是无法到达由012组成的子图的。那么012和345分别组成两个强连通分量。
在实际的现实问题中,我们考虑问题可能就不会简单地研究无向图。例如地图上的最短路径规划,ARP路由算法等等,考虑的都是有向图的问题。
如果有这样一个需求,我们希望用最少的次数遍历所有节点,怎么处理呢?
时间效应问题,强连通分量间的时间问题。
如果有向图的各个强连通分量中的元素个数相仿,那么,它们内部分别进行遍历的时间量级别是相等的,但实际情况是,这种情况很少发生。一般从一个强连通分量到另一个强连通分量。
正如上面的需求:如何用最少的次数遍历整个有向图的所有节点。假设我们将0、1、2组成子图1,将3、4、5组成子图,子图1有一条指向子图2的路径。这时候,我们从子图1的任意一点开始遍历。假设我们从1开始遍历,那么遍历的顺序将会是1—2,那么来到2的时候问题来了,是先走0的路径还是走子图1和子图2之间的路径去遍历节点3呢?
如果我们先遍历节点0,那么我们遍历完节点0之后,发现节点1已经遍历过,就会返回节点2,再沿着子图1和子图2之间的路径去遍历子图2。这看起来是挺合理的。
但问题是,如果是先遍历节点3(也就是说先遍历子图2)呢?
假设沿着子图1和子图2的路径去遍历子图2,那么子图2遍历完后,子图1还剩下节点0没有被遍历,这时候就会出现很为难的事情,因为之前遍历的情况无法判断哪些节点是没有遍历的,只能是原路返回,依次去从新遍历,“发现”哪些节点是还没去遍历的。似乎上图比较简单,这种方法不会耗费太多的时间。但如果是节点2连接着(并指向)许多个强连通子图的有向图,这种“返回式”的遍历将会是很费劲的一件事。
为了解决这个问题,Kosaraju算法提出了它的解决方案。Kosaraju算法的核心操作是将所有节点间的路径都翻转过来。下面分析一下为什么这种算法有它的优势。
还是拿上面的图来讲述。想象一下上面的有向图中的所有节点间的路径都翻转过来了。读者可以自己用一张纸简单画一下。就像下面的图:
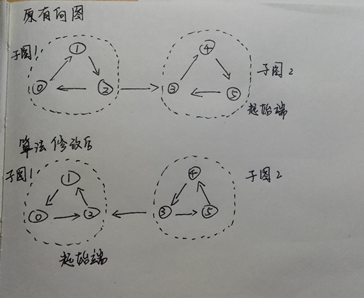
这一次,我们还是以0、1、2组成子图1,以3、4、5组成子图2。所不同的是,这次遍历的起始点从子图1开始。
多强连通分量的有向图
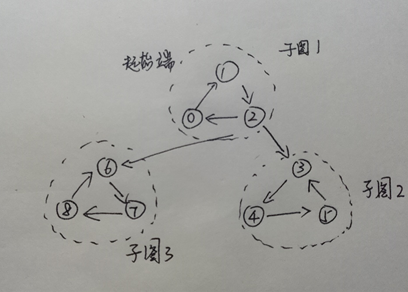
再来看一下这个多子图的强连通图,如果像上图所示,从子图1开始,就会像上文提到的那样,遍历到节点2,会出现多个去向的问题。而在还没有遍历完子图1的前提下,从节点2过渡到子图2/子图3,再回溯的时候会引来较大的麻烦。通过Kosaraju算法之后,从2节点出发的路径都会变成指向2。此时,遍历的起点还是从子图1开始,由于子图1没有出路,就不会出现上面所说的问题。再遍历完子图1后,继续遍历子图2、子图3。而子图2、子图3的遍历都是在强连通分量内部实现的。
算法实现
邻接集表示的有向图
N={
"a":{"b"}, #a
"b":{"c"}, #b
"c":{"a","d","g"}, #c
"d":{"e"}, #d
"e":{"f"}, #e
"f":{"d"}, #f
"g":{"h"}, #g
"h":{"i"}, #h
"i":{"g"} #i
}
翻转图实现代码:
def re_tr(G):
GT = {}
for u in G:
for v in G[u]:
# print(GT)
if GT.get(v):
GT[v].add(u)
else:
GT[v] = set()
GT[v].add(u) return GT
深度遍历算法实现代码:
#递归实现深度优先排序
def rec_dfs(G,s,S=None):
if S is None:
#S = set() #集合存储已经遍历过的节点
S = list() #用列表可以更方便查看遍历的次序,而用集合可以方便用difference求差集
# S.add(s)
S.append(s)
print(S)
for u in G[s]:
if u in S:continue
rec_dfs(G,u,S) return S
在强连通图内遍历
#遍历有向图的强连通分量
def walk(G,start,S=set()): #传入的参数S,即上面的seen很关键,这避免了通过连通图之间的路径进行遍历
P,Q = dict(),set() #list存放遍历顺序,set存放已经遍历过的节点
P[start] = None
Q.add(start)
while Q:
u = Q.pop() #选择下一个遍历节点(随机性)
for v in G[u].difference(P,S): #返回差集
Q.add(v)
P[v] = u
print(P)
return P
获得强连通分量
#获得各个强连通图
def scc(G):
GT = re_tr(G)
sccs,seen = [],set()
for u in rec_dfs(G,"a"): #以a为起点
if u in seen:continue
C = walk(GT,u,seen)
seen.update(C)
sccs.append(C)
return sccs
单元测试
print(scc(N)) 结果:
{'a': None, 'c': 'a', 'b': 'c'}
{'d': None, 'f': 'd', 'e': 'f'}
{'g': None, 'i': 'g', 'h': 'i'}
[{'a': None, 'c': 'a', 'b': 'c'}, {'d': None, 'f': 'd', 'e': 'f'}, {'g': None, 'i': 'g', 'h': 'i'}]
这是本人学习过程所写的第一篇关于图的算法文章,供大家一起学习讨论。其中难免会有错误。如有错误之处,请各位指出,万分感谢!
Kasaraju算法--强连通图遍历及其python实现的更多相关文章
- 图的遍历(Python实现)
图的遍历(Python实现) 记录两种图的遍历算法——广度优先(BFS)与深度优先(DFS). 图(graph)在物理存储上采用邻接表,而邻接表是用python中的字典来实现的. 两种遍历方式的代码如 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- javascript数据结构与算法--二叉树遍历(后序)
javascript数据结构与算法--二叉树遍历(后序) 后序遍历先访问叶子节点,从左子树到右子树,再到根节点. /* *二叉树中,相对较小的值保存在左节点上,较大的值保存在右节点中 * * * */ ...
- javascript数据结构与算法--二叉树遍历(先序)
javascript数据结构与算法--二叉树遍历(先序) 先序遍历先访问根节点, 然后以同样方式访问左子树和右子树 代码如下: /* *二叉树中,相对较小的值保存在左节点上,较大的值保存在右节点中 * ...
- javascript数据结构与算法--二叉树遍历(中序)
javascript数据结构与算法--二叉树遍历(中序) 中序遍历按照节点上的键值,以升序访问BST上的所有节点 代码如下: /* *二叉树中,相对较小的值保存在左节点上,较大的值保存在右节点中 * ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
- 【Python算法】遍历(Traversal)、深度优先(DFS)、广度优先(BFS)
图结构: 非常强大的结构化思维(或数学)模型.如果您能用图的处理方式来规范化某个问题,即使这个问题本身看上去并不像个图问题,也能使您离解决问题更进一步. 在众多图算法中,我们常会用到一种非常实用的思维 ...
随机推荐
- JDK 8 之 Stream sorted() 示例
原文链接:http://www.concretepage.com/java/jdk-8/java-8-stream-sorted-example 国外对Java8一系列总结的不错, 翻译过来给大家共享 ...
- [Swift]LeetCode494. 目标和 | Target Sum
You are given a list of non-negative integers, a1, a2, ..., an, and a target, S. Now you have 2 symb ...
- python之定义参数模块argparse(一)基本使用
在shell脚本中,若脚本带参数,则在脚本中使用$1.$2...等引用, 在python中,也可以定义类似的引用参数,可以为必选项也可以可选项. 基本用法如下三种: 1.必选项(位置参数) impor ...
- RSA算法原理——(2)RSA简介及基础数论知识
上期为大家介绍了目前常见加密算法,相信阅读过的同学们对目前的加密算法也算是有了一个大概的了解.如果你对这些解密算法概念及特点还不是很清晰的话,昌昌非常推荐大家可以看看HTTPS的加密通信原理,因为HT ...
- BBS论坛(五)
5.1.cms后台修改密码功能完成 (1)新建app/forms.py # app/forms.py from wtforms import Form class BaseForm(Form): de ...
- ThreadPoolExecutor线程池任务执行失败的时候会怎样
接上一篇 <JDK1.8中的线程池> 1. 任务执行失败时的处理逻辑 1.1. Worker Worker相当于线程池中的线程 可以看到,Worker有几个重要的属性: thread ...
- .NET Core WebApi中实现多态数据绑定
什么是多态数据绑定? 我们都知道在ASP.NET Core WebApi中数据绑定机制(Data Binding)负责绑定请求参数, 通常情况下大部分的数据绑定都能在默认的数据绑定器(Binder)中 ...
- Python爬虫入门教程 24-100 微医挂号网医生数据抓取
1. 写在前面 今天要抓取的一个网站叫做微医网站,地址为 https://www.guahao.com ,我们将通过python3爬虫抓取这个网址,然后数据存储到CSV里面,为后面的一些分析类的教程做 ...
- VueJs 源码分析 ---(一) 整体对 vuejs 框架的理解
vue-2.x SourceCode vue 2.x 源码解析 关于vue,以及为何要来写这份源码解析的原因 笔者从最开始接触到 vue 应该还是在 15年 10月份左右,当时听说 前端圈中发生很多的 ...
- 关于mybatis中typeHandler的两个案例
在做开发时,我们经常会遇到这样一些问题,比如我有一个Java中的Date数据类型,我想将之存到数据库的时候存成一个1970年至今的毫秒数,怎么实现?再比如我有一个User类,User类中有一个属性叫做 ...