Linux性能优化实战:系统的swap变高(08)
一、Swap 原理
前面提到,Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程
1、所谓换出
就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
2、换入
则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来
所以你看,Swap 其实是把系统的可用内存变大了。这样,即使服务器的内存不足,也可以运行大内存的应用程序
3、应用场景
即是内存不足时,有些程序也并不像被OOM杀死,二十希望能缓一段时间,等待人工介入,或者等系统自动释放其他程序的内存,再分配给它(可以给运维人员处理故障一个缓冲的时间)
常见的笔记本电脑休眠和快速开机的功能,也基于Swap ,休眠时,把系统内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以,这样就省去了很多应用程序的初始化过程,加快了开机速度
二、那么 Linux 到底在什么时候需要回收内存呢?
1、直接内存回收
有新的大块内存分配请求,但是剩余内存不足,这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求,这个过程被称为直接内存回收
2、kswapd0(定期回收内存)
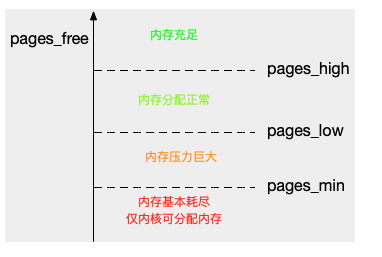
1、剩余内存页<最小阈值
root@openstack:~# free -h
total used free shared buff/cache available
Mem: 4.9G 114M 4.0G 992K 770M 4.5G
Swap: 3.9G 0B 3.9G
root@openstack:~# cat /proc/sys/vm/min_free_kbytes
67584
说明进程可用内存都耗尽了,只有内核才可以分配内存
2、页最小阈值<剩余内存页<页低阈值
内存压力比较大,剩余内存不多了,这是kswapd0会执行内存回收,直接剩余内存大于高阈值为止
3、页低阈值<剩余内存<页高阈值
说明有一定压力,但还可以满足新内存请求
4、剩余内存>页高阈值
说明剩余内存比较多,没有内存压力
watch -d grep -A 15 'Normal' /proc/zoneinfo
Every 2.0s: grep -A 15 Normal /proc/zoneinfo openstack: Wed Feb 6 08:45:01 2019 Node 0, zone Normal
pages free 146583
min 4986
low 6232
high 7478
spanned 399872
present 399872
managed 373102
protection: (0, 0, 0, 0, 0)
nr_free_pages 146583
nr_zone_inactive_anon 35
nr_zone_active_anon 11422
nr_zone_inactive_file 64699
nr_zone_active_file 120441
nr_zone_unevictable 1352
nr_zone_write_pending 0
三、为什么剩余内存很多的情况下,也会发生 Swap 呢?
这正是处理器的 NUMA (Non-Uniform Memory Access)架构导致的。
在 NUMA 架构下,多个处理器被划分到不同 Node 上,且每个 Node 都拥有自己的本地内存空间。
而通一个Node内部的内存空间实际上可以进一步分为不同的内存域。比如直接内存访问区域、普通内存区,伪内存去等如下图所示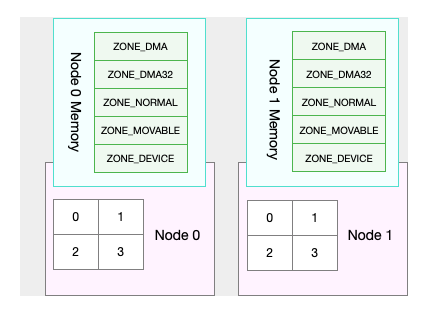
1、通过numactl查询node的分布情况
root@openstack:~# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 4976 MB
node 0 free: 4088 MB
node distances:
node 0
0: 10
1、NUMA和swap什么关系?
1、三个内存阈值(页最小阈值、页低阈值和页高阈值)查询
cat /proc/zoneinfo
Node 0, zone Normal
pages free 146583
min 4986
low 6232
high 7478
spanned 399872
present 399872
managed 373102
protection: (0, 0, 0, 0, 0)
nr_free_pages 146583
nr_zone_inactive_anon 35
nr_zone_active_anon 11422
nr_zone_inactive_file 64699
nr_zone_active_file 120441
nr_zone_unevictable 1352
nr_zone_write_pending 0
1、pages 处的 min、low、high,就是上面提到的三个内存阈值,而 free 是剩余内存页数,它跟后面的nr_free_pages 相同
2、nr_zone_active_anon 和 nr_zone_inactive_anon,分别是活跃和非活跃的一名页数
3、nr_zone_active_file 和 nr_zone_inactive_anon,分别是活跃和非活跃的文件页数
从这个输出结果可以发现,剩余内存远大于高阈值,所以此时的不会回收内存
2、Node寻找空闲内存还是本地内存中回收内存?
root@openstack:~# cat /proc/sys/vm/zone_reclaim_mode
0
默认的0,也就是刚刚提到的模式,表示既可以从其他Node寻找空闲内存,也可以从本地回收内存
1、1、2、4都表示只回收本地内存,
2、2表示可以回写脏数据回收内存
3、4表示可以用方式回收
3、到底该先回收哪一种呢?
1、对文件页的回收
当然就是直接回收缓存,或者把脏页写回磁盘后再回收
2、而对匿名页的回收
其实就是通过 Swap 机制,把它们写入磁盘后再释放内存
root@openstack:~# cat /proc/sys/vm/swappiness
60
swappiness 的范围是 0-100,数值越大,越积极使用Swap,更倾向于回收匿名页;
也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页
虽然swappiness的范围是0-100,不过要注意,这并不是内存的百分比,而是Swap调整积极程度的权重
即使你把它设置成0,当剩余内存+文件页小于也高阈值时,还是会发生Swap
Linux性能优化实战:系统的swap变高(08)的更多相关文章
- Linux性能优化实战学习笔记:第四十九讲
一.上节回顾 上一期,我们一起梳理了,网络时不时丢包的分析定位和优化方法.先简单回顾一下.网络丢包,通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而会导致网络延迟增 ...
- 《Linux 性能优化实战—倪朋飞 》学习笔记 CPU 篇
平均负载 指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数 可运行状态:正在使用CPU或者正在等待CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态 (Run ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
- Linux性能优化实战学习笔记:第五十六讲
一.上节回顾 上一节,我带你一起梳理了,性能问题分析的一般步骤.先带你简单回顾一下. 我们可以从系统资源瓶颈和应用程序瓶颈,这两个角度来分析性能问题的根源. 从系统资源瓶颈的角度来说,USE 法是最为 ...
- Linux性能优化实战(一)
一.优化方向 1,性能指标 从应用负载的视角出发,考虑"吞吐"和"延时" 从系统资源的视角出发,考虑资源使用率.饱和度等 2,性能优化步骤 选择指标评估应用程序 ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战学习笔记:第五十七讲
一.上节回顾 上一节,我带你一起梳理了常见的性能优化思路,先简单回顾一下.我们可以从系统和应用程序两个角度,来进行性能优化. 从系统的角度来说,主要是对 CPU.内存.网络.磁盘 I/O 以及内核软件 ...
- Linux性能优化实战(二)
一.CPU使用率过高 1,CPU使用率 a>节拍率 为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为HZ),触发时间中断,并使用全局变量Jiffies记录开机以来的节拍数.每发生 ...
- Linux性能优化实战学习笔记:第十讲
一.坏境准备 1.拓扑图 2.安装包 在第9节的基础上 在VM2上安装hping3依奈包 wget http://www.tcpdump.org/release/libpcap-1.9.0.tar.g ...
随机推荐
- MySQL之Innodb恢复的学习笔记
MySQL · 引擎特性 · InnoDB 崩溃恢复过程 enum { SRV_FORCE_IGNORE_CORRUPT = 1, /*!< let the server run even if ...
- Linux中输入输出重定向的问题
Linux 命令默认从标准输入设备(stdin)获取输入,将结果输出到标准输出设备(stdout)显示.一般情况下,标准输入设备就是键盘,标准输出设备就是终端,即显示器. 输出重定向:命令的输出不 ...
- Linux学习之路(二)
4.Linux文件查找工具. Linux经常使用locate与find作为文件查找命令.find可以认为是系统自带的命令,功能也挺多但是使用方法相对有点繁琐.find查找的是实时文件数据,一般用于查询 ...
- SQLServer之删除触发器
删除触发器 注意事项 可以通过删除DML触发器或删除触发器表来删除DML触发器. 删除表时,将同时删除与表关联的所有触发器. 删除触发器时,会从 sys.objects.sys.triggers 和 ...
- 记录日常Linux常用软件
yum -y install gcc gcc-c++ autoconf pcre pcre-devel make automake yum -y install wget httpd-tools vi ...
- Extjs 解决grid分页bug问题
//从后端获取数据加载到grid中var mainStore = new HeJsonStore({ url:'xxx', autoLoad:true, pageSize:20 }) //此方法最好放 ...
- bootstrapt 使用遇到问题
1.布局的时候什么时候用xs,sm,md,lg? small grid (≥ 768px) = .col-sm-*, medium grid (≥ 992px) = .col-md-*, large ...
- 10-ajax技术简介
一.ajax是什么?是网页中的异步刷新技术.其核心是js+xml二.执行过程1.js的核心对象XMLHttpRequest是一个具备像后台发送请求的一个对象2.XMLHttpRequest可以异步发送 ...
- STM32F40G-EVAL_UC/OS III
micrum官网下载uc/os程序包: 包含文件cotex_M4.h:
- Spring boot整合Mybatis
时隔两个月的再来写博客的感觉怎么样呢,只能用“棒”来形容了.闲话少说,直接入正题,之前的博客中有说过,将spring与mybatis整个后开发会更爽,基于现在springboot已经成为整个业界开发主 ...