Conv1D、Conv2D、Conv3D
由于计算机视觉的大红大紫,二维卷积的用处范围最广。因此本文首先介绍二维卷积,之后再介绍一维卷积与三维卷积的具体流程,并描述其各自的具体应用。
1. 二维卷积
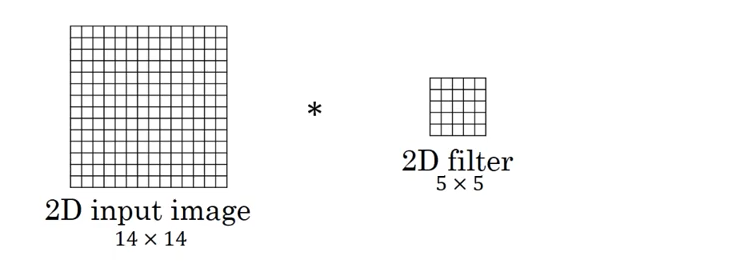
图中的输入的数据维度为14×1414×14,过滤器大小为5×55×5,二者做卷积,输出的数据维度为10×1010×10(14−5+1=1014−5+1=10)。如果你对卷积维度的计算不清楚,可以参考我之前的博客吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(CNN)(上)。
上述内容没有引入channel的概念,也可以说channel的数量为1。如果将二维卷积中输入的channel的数量变为3,即输入的数据维度变为(14×14×314×14×3)。由于卷积操作中过滤器的channel数量必须与输入数据的channel数量相同,过滤器大小也变为5×5×35×5×3。在卷积的过程中,过滤器与数据在channel方向分别卷积,之后将卷积后的数值相加,即执行10×1010×10次3个数值相加的操作,最终输出的数据维度为10×1010×10。
以上都是在过滤器数量为1的情况下所进行的讨论。如果将过滤器的数量增加至16,即16个大小为10×10×310×10×3的过滤器,最终输出的数据维度就变为10×10×1610×10×16。可以理解为分别执行每个过滤器的卷积操作,最后将每个卷积的输出在第三个维度(channel 维度)上进行拼接。
二维卷积常用于计算机视觉、图像处理领域。
2. 一维卷积

图中的输入的数据维度为8,过滤器的维度为5。与二维卷积类似,卷积后输出的数据维度为8−5+1=48−5+1=4。
如果过滤器数量仍为1,输入数据的channel数量变为16,即输入数据维度为8×168×16。这里channel的概念相当于自然语言处理中的embedding,而该输入数据代表8个单词,其中每个单词的词向量维度大小为16。在这种情况下,过滤器的维度由55变为5×165×16,最终输出的数据维度仍为44。
如果过滤器数量为nn,那么输出的数据维度就变为4×n4×n。
一维卷积常用于序列模型,自然语言处理领域。
3. 三维卷积
这里采用代数的方式对三维卷积进行介绍,具体思想与一维卷积、二维卷积相同。
假设输入数据的大小为a1×a2×a3a1×a2×a3,channel数为cc,过滤器大小为ff,即过滤器维度为f×f×f×cf×f×f×c(一般不写channel的维度),过滤器数量为nn。
基于上述情况,三维卷积最终的输出为(a1−f+1)×(a2−f+1)×(a3−f+1)×n(a1−f+1)×(a2−f+1)×(a3−f+1)×n。该公式对于一维卷积、二维卷积仍然有效,只有去掉不相干的输入数据维度就行。
三维卷积常用于医学领域(CT影响),视频处理领域(检测动作及人物行为)。
Conv1D、Conv2D、Conv3D的更多相关文章
- 学习笔记TF048:TensorFlow 系统架构、设计理念、编程模型、API、作用域、批标准化、神经元函数优化
系统架构.自底向上,设备层.网络层.数据操作层.图计算层.API层.应用层.核心层,设备层.网络层.数据操作层.图计算层.最下层是网络通信层和设备管理层.网络通信层包括gRPC(google Remo ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com VGGNet在2014年ImageNet图像分类任务竞赛中有出色的表现.网络结构如下图所示: 同样的, ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(二)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com AlexNet在2012年ImageNet图像分类任务竞赛中获得冠军.网络结构如下图所示: 对CIFA ...
- 学习笔记TF015:加载图像、图像格式、图像操作、颜色
TensorFlow支持JPG.PNG图像格式,RGB.RGBA颜色空间.图像用与图像尺寸相同(height*width*chnanel)张量表示.通道表示为包含每个通道颜色数量标量秩1张量.图像所有 ...
- 学习笔记TF013:卷积、跨度、边界填充、卷积核
卷积运算,两个输入张量(输入数据和卷积核)进行卷积,输出代表来自每个输入的信息张量.tf.nn.conv2d完成卷积运算.卷积核(kernel),权值.滤波器.卷积矩阵或模版,filter.权值训练习 ...
- 图像分类丨浅析轻量级网络「SqueezeNet、MobileNet、ShuffleNet」
前言 深度卷积网络除了准确度,计算复杂度也是考虑的重要指标.本文列出了近年主流的轻量级网络,简单地阐述了它们的思想.由于本人水平有限,对这部分的理解还不够深入,还需要继续学习和完善. 最后我参考部分列 ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- CNN中feature map、卷积核、卷积核的个数、filter、channel的概念解释
CNN中feature map.卷积核.卷积核的个数.filter.channel的概念解释 参考链接: https://blog.csdn.net/xys430381_1/article/detai ...
- Kaggle竞赛丨入门手写数字识别之KNN、CNN、降维
引言 这段时间来,看了西瓜书.蓝皮书,各种机器学习算法都有所了解,但在实践方面却缺乏相应的锻炼.于是我决定通过Kaggle这个平台来提升一下自己的应用能力,培养自己的数据分析能力. 我个人的计划是先从 ...
随机推荐
- IDEA_教你十分钟下载并破解IntelliJ IDEA(2017)(转)
之前都是用myeclipse,但是最近发现看的很多教学视频都是使用 IntelliJ IDEA,于是决定换个软件开始新的学习征程! 下面讲讲我是如何在十分钟之内安装并破解该软件. 1.首先,我找到了 ...
- [LeetCode] Most Common Word 最常见的单词
Given a paragraph and a list of banned words, return the most frequent word that is not in the list ...
- 23 创建ArcMap启动日志
在ArcMap的启动过程中,我们可以看到软件的界面上分别会显示[初始化许可……].[初始化应用……].[加载文档……]字样,当ArcMap打开出现问题时,我们可以根据以上文字来判断出现错误的情况,还有 ...
- python在读取文件时出现 'gbk' codec can't decode byte 0x89 in position 68: illegal multibyte sequence
python在读取文件时出现“UnicodeDecodeError:'gbk' codec can't decode byte 0x89 in position 68: illegal multiby ...
- LocalDate
java中做时间处理时一般会采用java.util.Date,但是相比于Date来说,还有更好的选择 -- java.time.LocalDate. 这是jdk8中新增的日期处理类,同时新增的还有ja ...
- 如何从日期对象python获取以毫秒(秒后3位小数)为单位的时间值?
要在python中,要获取具有毫秒(秒后3位小数)的日期字符串,请使用以下命令: %f 显示毫秒 import datetime # 获得当前时间 now=datetime.datetime.now( ...
- LeetCode 34 - 在排序数组中查找元素的第一个和最后一个位置 - [二分][lower_bound和upper_bound]
给定一个按照升序排列的整数数组 nums,和一个目标值 target.找出给定目标值在数组中的开始位置和结束位置. 你的算法时间复杂度必须是 O(log n) 级别. 如果数组中不存在目标值,返回 [ ...
- Math工具类
public static void main(String[] args) { // 工具类,所有方法都以静态方法提供,没有实例存在的意义 // 不提供任何实例的方法,代表当前类属于无状态的. // ...
- 软件分享--EditPlus
有些人分享的报毒,不好用,所以在这分享个好用的.百度网盘地址: 链接: https://pan.baidu.com/s/15s7I6p0K_36KPtzRDbHfrw 密码:kl5w
- poj1699
#include<iostream> #include<cstring> using namespace std; ][]; ],len[],addlen[][]; int m ...