python3 爬虫---爬取糗事百科
这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1
分析网址,参数'page/'后面的数字''指的是页数,第二页就是'/page/2',以此类推。。。
一、分析网页

然后明确要爬取的元素:作者名、内容、好笑数、以及评论数量
每一个段子的信息存放在'div id="content-left"'下的div中
爬取元素的所在位置
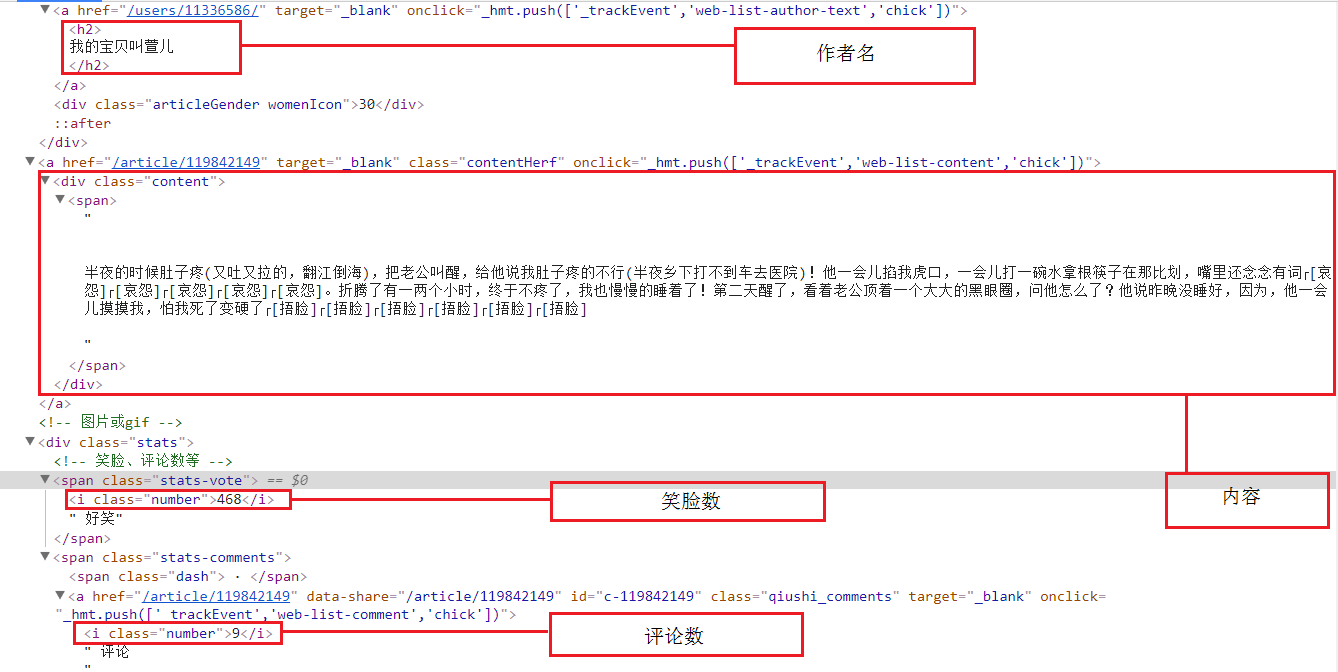
二、爬取部分
工具:
Python3
requests
xpath
1、获取每一个段子
# 返回页面的div_list
def getHtmlDivList(self, pageIndex):
pageUrl = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex)
html = requests.get(url=pageUrl, headers=self.headers).text
selector = etree.HTML(html)
divList = selector.xpath('//div[@id="content-left"]/div')
return divList
每一个段子都在div中,这里用xpath,筛选出来后返回的是一个列表,每一个div都在里面
2、获取每一个段子中的元素
def getHtmlItems(self, divList):
items = []
for div in divList:
item = []
# 发布人
name = div.xpath('.//h2/text()')[0].replace("\n", "")
item.append(name)
# 内容(阅读全文)
contentForAll = div.xpath('.//div[@class="content"]/span[@class="contentForAll"]')
if contentForAll:
contentForAllHref = div.xpath('.//a[@class="contentHerf"]/@href')[0]
contentForAllHref = "https://www.qiushibaike.com" + contentForAllHref
contentForAllHrefPage = requests.get(url=contentForAllHref).text
selector2 = etree.HTML(contentForAllHrefPage)
content = selector2.xpath('//div[@class="content"]/text()')
content = "".join(content)
content = content.replace("\n", "")
else:
content = div.xpath('.//div[@class="content"]/span/text()')
content = "".join(content)
content = content.replace("\n", "")
item.append(content)
# 点赞数
love = div.xpath('.//span[@class="stats-vote"]/i[@class="number"]/text()')
love = love[0]
item.append(love)
# 评论人数
num = div.xpath('.//span[@class="stats-comments"]//i[@class="number"]/text()')
num = num[0]
item.append(num)
items.append(item)
return items
这里需要注意的是,xpath返回的是一个列表,筛选出来后需要用[0]获取到字符串类型
上面的代码中,爬取的内容里,有的段子是这样的,如下图: 
内容中会有标签<br>,那么用xpath爬取出来后,里面的内容都会成一个列表(这里的div就是列表),
那div[0]就是"有一次回老家看姥姥,遇到舅妈说到表弟小时候的事~",所以需要将div转换成字符串
其他的部分就xpath语法的使用
3、保存进文本
# 保存入文本
def saveItem(self, items):
f = open('F:\\Pythontest1\\qiushi.txt', "a", encoding='UTF-8') for item in items:
name = item[0]
content = item[1]
love = item[2]
num = item[3] # 写入文本
f.write("发布人:" + name + '\n')
f.write("内容:" + content + '\n')
f.write("点赞数:" + love + '\t')
f.write("评论人数:" + num)
f.write('\n\n') f.close()
4、全部代码
import os
import re
import requests
from lxml import etree # 糗事百科爬虫
class QSBK:
# 初始化方法,定义变量
def __init__(self):
self.pageIndex = 1
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"
}
self.enable = False # 返回页面的div_list
def getHtmlDivList(self, pageIndex):
pageUrl = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex)
html = requests.get(url=pageUrl, headers=self.headers).text
selector = etree.HTML(html)
divList = selector.xpath('//div[@id="content-left"]/div')
return divList # 获取文本中要截取的元素
def getHtmlItems(self, divList): items = [] for div in divList:
item = []
# 发布人
name = div.xpath('.//h2/text()')[0].replace("\n", "")
item.append(name) # 内容(阅读全文)
contentForAll = div.xpath('.//div[@class="content"]/span[@class="contentForAll"]')
if contentForAll:
contentForAllHref = div.xpath('.//a[@class="contentHerf"]/@href')[0]
contentForAllHref = "https://www.qiushibaike.com" + contentForAllHref
contentForAllHrefPage = requests.get(url=contentForAllHref).text
selector2 = etree.HTML(contentForAllHrefPage)
content = selector2.xpath('//div[@class="content"]/text()')
content = "".join(content)
content = content.replace("\n", "")
else:
content = div.xpath('.//div[@class="content"]/span/text()')
content = "".join(content)
content = content.replace("\n", "")
item.append(content) # 点赞数
love = div.xpath('.//span[@class="stats-vote"]/i[@class="number"]/text()')
love = love[0]
item.append(love) # 评论人数
num = div.xpath('.//span[@class="stats-comments"]//i[@class="number"]/text()')
num = num[0]
item.append(num) items.append(item) return items # 保存入文本
def saveItem(self, items):
f = open('F:\\Pythontest1\\qiushi.txt', "a", encoding='UTF-8') for item in items:
name = item[0]
content = item[1]
love = item[2]
num = item[3] # 写入文本
f.write("发布人:" + name + '\n')
f.write("内容:" + content + '\n')
f.write("点赞数:" + love + '\t')
f.write("评论人数:" + num)
f.write('\n\n') f.close() # 判断文本是否已创建,添加路径
def judgePath(self):
if os.path.exists('F:\\Pythontest1') == False:
os.mkdir('F:\\Pythontest1')
if os.path.exists("F:\\Pythontest1\\qiushi.txt") == True:
os.remove("F:\\Pythontest1\\qiushi.txt") def start(self):
self.judgePath()
print("正在读取糗事百科,按回车继续保存下一页,Q退出")
self.enable = True
while self.enable:
divList = self.getHtmlDivList(self.pageIndex)
data = self.getHtmlItems(divList)
self.saveItem(data)
print('已保存第%d页的内容' % self.pageIndex)
pan = input('是否继续保存:')
if pan != 'Q':
self.pageIndex += 1
self.enable = True
else:
print('程序运行结束!!')
self.enable = False spider = QSBK()
spider.start()
python3 爬虫---爬取糗事百科的更多相关文章
- python学习(十六)写爬虫爬取糗事百科段子
原文链接:爬取糗事百科段子 利用前面学到的文件.正则表达式.urllib的知识,综合运用,爬取糗事百科的段子先用urllib库获取糗事百科热帖第一页的数据.并打开文件进行保存,正好可以熟悉一下之前学过 ...
- Python爬虫爬取糗事百科段子内容
参照网上的教程再做修改,抓取糗事百科段子(去除图片),详情见下面源码: #coding=utf-8#!/usr/bin/pythonimport urllibimport urllib2import ...
- Python爬虫-爬取糗事百科段子
闲来无事,学学python爬虫. 在正式学爬虫前,简单学习了下HTML和CSS,了解了网页的基本结构后,更加快速入门. 1.获取糗事百科url http://www.qiushibaike.com/h ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
随机推荐
- awk练习题
1. sed和awk有什么区别? (1)awk:按列(域)操作:sed:按行操作 (2)awk:文本处理语言,适合对文本进行抽取处理:sed:非交互式的编辑器,适合对文本进行编辑 2. awk要处理域 ...
- IIC接口下的24C02 驱动分析
本节来学习IIC接口下的24C02 驱动分析,本节学完后,再来学习Linux下如何使用IIC操作24C02 1.I2C通信介绍 它是由数据线SDA和时钟SCL构成的串行总线,可发送和接收数据,是一个多 ...
- struts2常见错误
1.Caught exception while loading file struts-default.xml - [unknown location]解决办法:由于lib包冲突造成的,将两个解析x ...
- Linux特殊字符用法、后台命令管理
!! 重复前一个命令!字符 重复前一个以"字符"开头的命令!num 安装history命令的序号执行命令!?abc 重复之前包含"abc"的命令!-n 重复倒数 ...
- WPF TextBox按字节长度限制输入
前两天做一个项目的时候,由于页面没有限制TextBox的输入长度,所以,后台直接报错了,超出数据库最大的长度. 数据库的长度是按照字节来计算的,而且不同的编码格式,汉字占用的字节长度又不相同,比如,我 ...
- scala读取parquet文件
import org.apache.spark.SparkConfimport org.apache.spark.SparkContextimport org.apache.spark.sql.SQL ...
- JAVA爬虫代码
工程目录: 所需要的jar包为: jsoup-1.10.2.jar /** * Created by wangzheng on 2017/2/19. */ public class Article ...
- Struts2-Tiles整合
Apache Tiles是一个JavaEE应用的页面布局框架.Tiles框架提供了一种模板机制,可以为某一类页面定义一个通用的模板,该模板定义了页面的整体布局.布局由可以复用的多个块组成,每个页面可以 ...
- [转载] Rss 与 Feed 的概念区别
转载自http://www.chinaz.com/news/2011/0831/207961.shtml 可能很多刚刚接触博客的童鞋们,也和我一样不太了解:rss和feed概念或者说不了解rss和fe ...
- 拼写纠错的利器,BK树算法
BK树或者称为Burkhard-Keller树,是一种基于树的数据结构,被设计于快速查找近似字符串匹配,比方说拼写纠错,或模糊查找,当搜索”aeek”时能返回”seek”和”peek”. 本文首先剖析 ...