Spark 贝叶斯分类算法
一、贝叶斯定理数学基础
我们都知道条件概率的数学公式形式为
 即B发生的条件下A发生的概率等于A和B同时发生的概率除以B发生的概率。
即B发生的条件下A发生的概率等于A和B同时发生的概率除以B发生的概率。
根据此公式变换,得到贝叶斯公式: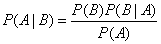 即贝叶斯定律是关于随机事件A和B的条件概率(或边缘概率)的一则定律。通常,事件A在事件B发生的条件溪的概率,与事件B在事件A的条件下的概率是不一样的,而贝叶斯定律就是描述二者之间的关系的。
即贝叶斯定律是关于随机事件A和B的条件概率(或边缘概率)的一则定律。通常,事件A在事件B发生的条件溪的概率,与事件B在事件A的条件下的概率是不一样的,而贝叶斯定律就是描述二者之间的关系的。
更进一步将贝叶斯公式进行推广,假设事件A发生的概率是由一系列的因素(A1,A2,A3,...An)决定的,则事件A的全概率公式为:
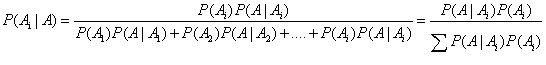
二、朴素贝叶斯分类
朴素贝叶斯分类是一种十分简单的分类算法,其思想基础是:对于给定的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项就属于哪个类别。
假设V=(v1,v2,v3....vn)是一个待分项,而vn为V的每个特征向量;
B=(b1,b2,b3...bn)是一个分类集合,bn为每个具体的分类;
如果需要测试某个Vn归属于B集合中的哪个具体分类,则需要计算P(bn|V),即在V发生的条件下,归属于b1,b2,b3,....bn中哪个可能性最大。即:
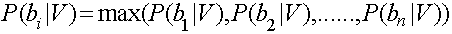
因此,这个问题转换成求每个待分项分配到集合中具体分类的概率是多少。而这个·具体概率的求法可以使用贝叶斯定律。
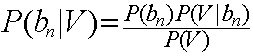
经过变换得出:
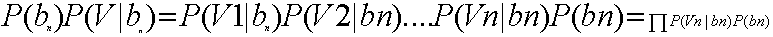
三、MLlib对应的API
1、贝叶斯分类伴生对象NativeBayes,原型:
object NaiveBayes extends scala.AnyRef with scala.Serializable {
def train(input : org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint]) : org.apache.spark.mllib.classification.NaiveBayesModel = { /* compiled code */ }
def train(input : org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint], lambda : scala.Double) : org.apache.spark.mllib.classification.NaiveBayesModel = { /* compiled code */ }
}
其主要定义了训练贝叶斯分类模型的train方法,其中input为训练样本,lambda为平滑因子参数。
2、train方法,其是NativeBayes对象的静态方法,根据设置的朴素贝叶斯分类参数新建朴素贝叶斯分类类,并执行run方法进行训练。
3、朴素贝叶斯分类类NaiveBayes,原型:
class NaiveBayes private (private var lambda : scala.Double) extends scala.AnyRef with scala.Serializable with org.apache.spark.Logging {
def this() = { /* compiled code */ }
def setLambda(lambda : scala.Double) : org.apache.spark.mllib.classification.NaiveBayes = { /* compiled code */ }
def run(data : org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint]) : org.apache.spark.mllib.classification.NaiveBayesModel = { /* compiled code */ }
}
4、run方法,该方法主要计算先验概率和条件概率。首先对所有样本数据进行聚合,以label为key,聚合同一个label的特征features,得到所有label的统计(label,features之和),然后根据label统计数据,再计算p(i),和theta(i)(j),最后,根据类别标签列表、类别先验概率、各类别下的每个特征的条件概率生成贝叶斯模型。
先验概率并取对数p(i)=log(p(yi))=log((i类别的次数+平滑因子)/(总次数+类别数*平滑因子)))
各个特征属性的条件概率,并取对数
theta(i)(j)=log(p(ai|yi))=log(sumTermFreqs(j)+平滑因子)-thetaLogDenom
其中,theta(i)(j)是类别i下特征j的概率,sumTermFreqs(j)是特征j出现的次数,thetaLogDenom一般分2种情况,如下:
1.多项式模型
thetaLogDenom=log(sumTermFreqs.values.sum+ numFeatures* lambda)
其中,sumTermFreqs.values.sum类别i的总数,numFeatures特征数量,lambda平滑因子
2.伯努利模型
thetaLogDenom=log(n+2.0*lambda)
5、aggregated:对所有样本进行聚合统计,统计没个类别下的每个特征值之和及次数。
6、pi表示各类别·的·先验概率取自然对数的值
7、theta表示各个特征在各个类别中的条件概率值
8、predict:根据模型的先验概率、条件概率,计算样本属于每个类别的概率,取最大项作为样本的类别
9、贝叶斯分类模型NaiveBayesModel包含参数:类别标签列表(labels)、类别先验概率(pi)、各个特征在各个类别中的条件概率(theta)。
四、使用示例
1、样本数据:
0,1 0 0
0,2 0 0
1,0 1 0
1,0 2 0
2,0 0 1
2,0 0 2
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkConf, SparkContext} object Bayes {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("BayesDemo").setMaster("local")
val sc=new SparkContext(conf)
//读取样本数据,此处使用自带的处理数据方式·
val data=MLUtils.loadLabeledPoints(sc,"d://bayes.txt")
//训练贝叶斯模型
val model=NaiveBayes.train(data,1.0)
//model.labels.foreach(println)
//model.pi.foreach(println)
val test=Vectors.dense(0,0,100)
val res=model.predict(test)
println(res)//输出结果为2.0
}
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.{SparkConf, SparkContext}
object Bayes {
def main(args: Array[String]): Unit = {
//创建spark对象
val conf=new SparkConf().setAppName("BayesDemo").setMaster("local")
val sc=new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
//读取样本数据
val data=sc.textFile("d://bayes.txt")//读取数据
val demo=data.map{ line=>//处理数据
val parts=line.split(',')//分割数据·
LabeledPoint(parts(0).toDouble,//标签数据转换
Vectors.dense(parts(1).split(' ').map(_.toDouble)))//向量数据转换
}
//将样本数据分为训练样本和测试样本
val sp=demo.randomSplit(Array(0.6,0.4),seed = 11L)//对数据进行分配
val train=sp(0)//训练数据
val testing=sp(1)//测试数据
//建立贝叶斯分类模型,并进行训练
val model=NaiveBayes.train(train,lambda = 1.0)
//对测试样本进行测试
val pre=testing.map(p=>(model.predict(p.features),p.label))//验证模型
val prin=pre.take(20)
println("prediction"+"\t"+"label")
for(i<- 0 to prin.length-1){
println(prin(i)._1+"\t"+prin(i)._2)
}
val accuracy=1.0 *pre.filter(x=>x._1==x._2).count()//计算准确度
println(accuracy)
}
}
Spark 贝叶斯分类算法的更多相关文章
- 从决策树学习谈到贝叶斯分类算法、EM、HMM --别人的,拷来看看
从决策树学习谈到贝叶斯分类算法.EM.HMM 引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
从决策树学习谈到贝叶斯分类算法.EM.HMM (Machine Learning & Recommend Search交流新群:172114338) 引言 log ...
- 朴素贝叶斯分类算法介绍及python代码实现案例
朴素贝叶斯分类算法 1.朴素贝叶斯分类算法原理 1.1.概述 贝叶斯分类算法是一大类分类算法的总称 贝叶斯分类算法以样本可能属于某类的概率来作为分类依据 朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一 ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例一)
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 名词解释: 先验概率:由以往的数据分析得到的概率, 叫做先验概率. 后验概率:而在 ...
- scikit-learn学习之贝叶斯分类算法
版权声明:<—— 用心写好你的每一篇文章,转载请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================= ...
- 《机器学习实战》基于朴素贝叶斯分类算法构建文本分类器的Python实现
============================================================================================ <机器学 ...
- 朴素贝叶斯分类算法-----java
1.贝叶斯分类的基础--贝叶斯定理 已知某条件概率.怎样得到两个事件交换后的概率,也就是在已知P(A|B)的情况下怎样求得P(B|A). 这里先解释什么是条件概率: 表示事件B已经发生的前提下,事件A ...
- spark 线性回归算法(scala)
构建Maven项目,托管jar包 数据格式 //0.fp_nid,1.nsr_id,2.gf_id,2.hydm,3.djzclx_dm,4.kydjrq,5.xgrq,6.je,7.se,8.jsh ...
- 利用朴素贝叶斯分类算法对搜狐新闻进行分类(python)
数据来源 https://www.sogou.com/labs/resource/cs.php介绍:来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL ...
随机推荐
- Android对话框和帧动画
Android对话框 在一个例子中展示四种对话框. 设置四个按钮 <LinearLayout xmlns:android="http://schemas.android.com/apk ...
- jquery.flexslider.js带左右箭头且带按钮可滚动的图片插件
一.插件介绍 FlexSlider是一个非常出色的jQuery滑动切换插件,它支持所有主流浏览器,并有淡入淡出效果.FlexSlider对于网站开发者来说是一个不错测JQUERY特效,因为支持全浏览器 ...
- OpenCV 之 Mat 类
以前看 OpenCV 的书,或者资料也好,遇到 Mat 类的介绍,一般都是匆匆带过,自以为已经很熟悉了,从来没有深入研究过. 结果前段时间面试了一家公司,被问到两个 Mat 的问题:一是,谈谈对 Ma ...
- 看完给跪了:技术大牛总结的Github与华为软件开发云完整对比
华为软件开发云配置管理 服务和Github是国内外比较有代表性的代码托管平台,它们以git作为版本管理工具,使项目中身处各地的人员可以协同工作,主要操作涉及仓库.分支.提交.pull request等 ...
- PHP部分问题的总结
一.php连接sql sever 2005 中文编码转换问题. 这个问题是近期做Yii项目遇到的,而且php项目中用sql server做数据库,就是一个很坑的事,但没办法啊,客户是大爷,得听他的.( ...
- MySQL之删_delete-truncate
MySQL增删改查之删_delete-truncate 一.DELETE语句 删除数据记录 1.在单表中删除行 语法: DELETE [IGNORE] FROM tbl_name [WHERE whe ...
- MySQL编程基础
本文是关于MySQL编程中的一些基础知识,包括变量和运算符.常用语句.函数. 一.变量与运算符 1.用户会话变量声明:SET @变量名 = 表达式;//即:用户会话变量无需提前定义,直接用赋值语句赋值 ...
- 【原创】Superset在windows下的安装配置
Superset是由Airbnb(知名在线房屋短租公司)开源BI数据分析与可视化平台(曾用名Caravel.Panoramix),该工具主要特点是可自助分析.自定义仪表盘.分析结果可视化(导出).用户 ...
- ssh相关问题
问题1 一般错误信息为:ssh: connect to host localhost port 22: Connection refused 这种错误很主要的一个原因是sshd服务没有启动,先启动ss ...
- Python2和Python3的一些语法区别
Python2和Python3的一些语法区别 python 1.print 在版本2的使用方法是: print 'this is version 2 也可以是 print('this is versi ...