Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进
一、简单回顾ConcurrentHashMap在jdk1.7中的设计
先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示:
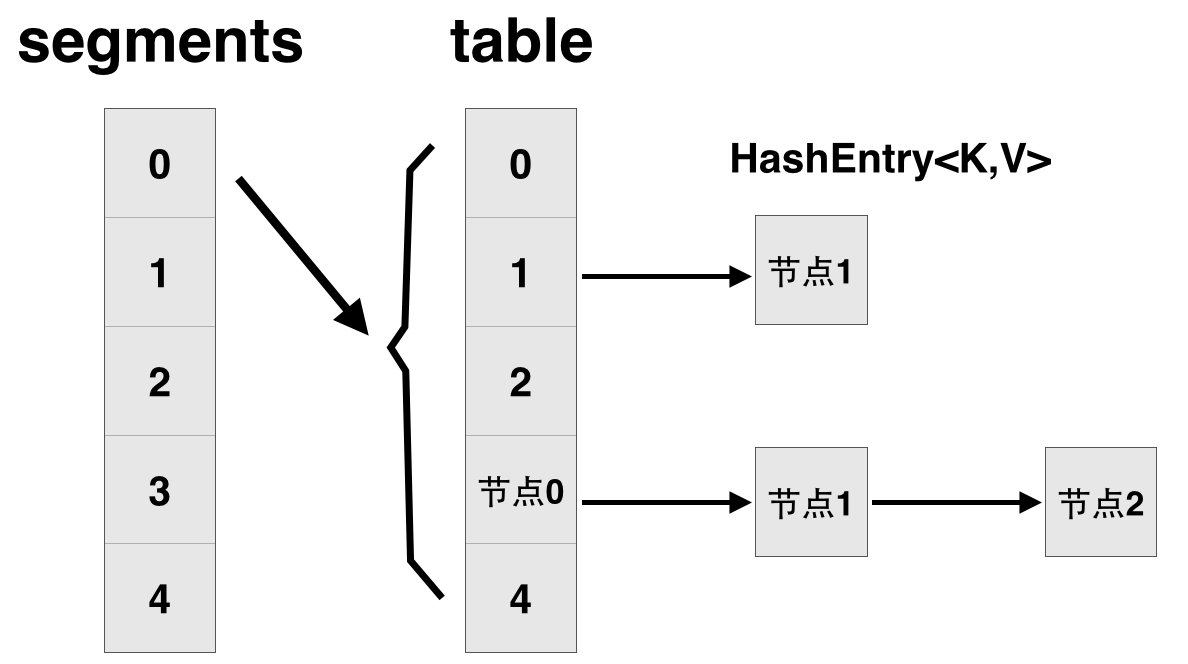
每一个segment都是一个HashEntry<K,V>[] table, table中的每一个元素本质上都是一个HashEntry的单向队列。比如table[3]为首节点,table[3]->next为节点1,之后为节点2,依次类推。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable { // 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments; // 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
} // 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
二、在jdk1.8中主要做了2方面的改进
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
为了说明以上2个改动,看一下put操作是如何实现的。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}
另外,在其他方面也有一些小的改进,比如新增字段 transient volatile CounterCell[] counterCells; 可方便的计算hashmap中所有元素的个数,性能大大优于jdk1.7中的size()方法。
三、ConcurrentHashMap jdk1.7、jdk1.8性能比较
测试程序如下:
public class CompareConcurrentHashMap {
private static ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String, Integer>(40000);
public static void putPerformance(int index, int num) {
for (int i = index; i < (num + index) ; i++)
map.put(String.valueOf(i), i);
}
public static void getPerformance2() {
long start = System.currentTimeMillis();
for (int i = 0; i < 400000; i++)
map.get(String.valueOf(i));
long end = System.currentTimeMillis();
System.out.println("get: it costs " + (end - start) + " ms");
}
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
final CountDownLatch cdLatch = new CountDownLatch(4);
for (int i = 0; i < 4; i++) {
final int finalI = i;
new Thread(new Runnable() {
public void run() {
CompareConcurrentHashMap.putPerformance(100000 * finalI, 100000);
cdLatch.countDown();
}
}).start();
}
cdLatch.await();
long end = System.currentTimeMillis();
System.out.println("put: it costs " + (end - start) + " ms");
CompareConcurrentHashMap.getPerformance2();
}
}
程序运行多次后取平均值,结果如下:

四、Collections.synchronizedList和CopyOnWriteArrayList性能分析
CopyOnWriteArrayList在线程对其进行变更操作的时候,会拷贝一个新的数组以存放新的字段,因此写操作性能很差;而Collections.synchronizedList读操作采用了synchronized,因此读性能较差。以下为测试程序:
public class App {
private static List<String> arrayList = Collections.synchronizedList(new ArrayList<String>());
private static List<String> copyOnWriteArrayList = new CopyOnWriteArrayList<String>();
private static CountDownLatch cdl1 = new CountDownLatch(2);
private static CountDownLatch cdl2 = new CountDownLatch(2);
private static CountDownLatch cdl3 = new CountDownLatch(2);
private static CountDownLatch cdl4 = new CountDownLatch(2);
static class Thread1 extends Thread {
@Override
public void run() {
for (int i = 0; i < 10000; i++)
arrayList.add(String.valueOf(i));
cdl1.countDown();
}
}
static class Thread2 extends Thread {
@Override
public void run() {
for (int i = 0; i < 10000; i++)
copyOnWriteArrayList.add(String.valueOf(i));
cdl2.countDown();
}
}
static class Thread3 extends Thread1 {
@Override
public void run() {
int size = arrayList.size();
for (int i = 0; i < size; i++)
arrayList.get(i);
cdl3.countDown();
}
}
static class Thread4 extends Thread1 {
@Override
public void run() {
int size = copyOnWriteArrayList.size();
for (int i = 0; i < size; i++)
copyOnWriteArrayList.get(i);
cdl4.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
long start1 = System.currentTimeMillis();
new Thread1().start();
new Thread1().start();
cdl1.await();
System.out.println("arrayList add: " + (System.currentTimeMillis() - start1));
long start2 = System.currentTimeMillis();
new Thread2().start();
new Thread2().start();
cdl2.await();
System.out.println("copyOnWriteArrayList add: " + (System.currentTimeMillis() - start2));
long start3 = System.currentTimeMillis();
new Thread3().start();
new Thread3().start();
cdl3.await();
System.out.println("arrayList get: " + (System.currentTimeMillis() - start3));
long start4 = System.currentTimeMillis();
new Thread4().start();
new Thread4().start();
cdl4.await();
System.out.println("copyOnWriteArrayList get: " + (System.currentTimeMillis() - start4));
}
}
结果如下:

Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进的更多相关文章
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进(转)
一.简单回顾ConcurrentHashMap在jdk1.7中的设计 先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示: 每一个segment都是一个HashE ...
- Java并发编程系列-(9) JDK 8/9/10中的并发
9.1 CompletableFuture CompletableFuture是JDK 8中引入的工具类,实现了Future接口,对以往的FutureTask的功能进行了增强. 手动设置完成状态 Co ...
- Java并发编程笔记之ConcurrentHashMap原理探究
在多线程环境下,使用HashMap进行put操作时存在丢失数据的情况,为了避免这种bug的隐患,强烈建议使用ConcurrentHashMap代替HashMap. HashTable是一个线程安全的类 ...
- java 并发容器一之ConcurrentHashMap(基于JDK1.8)
上一篇文章简单的写了一下,BoundedConcurrentHashMap,觉得https://www.cnblogs.com/qiaoyutao/p/10903813.html用的并不多:今天着重写 ...
- 《Java并发编程实战》读书笔记(更新中)
一.简介 1.多线程编程要注意的几点: 安全性:永远不发生糟糕的事情 活跃性:某件正确的事情最终会发生(不会发生无限循环或者死锁) 性能:正确的事尽快发生(上下文切换消耗之类的) 二.线程安全 1.为 ...
- Java 并发编程(三)为线程安全类中加入新的原子操作
Java 类库中包括很多实用的"基础模块"类.通常,我们应该优先选择重用这些现有的类而不是创建新的类.:重用能减少开发工作量.开发风险(由于现有类都已经通过測试)以及维护成本.有时 ...
- java并发编程——并发容器
概述 java cocurrent包提供了很多并发容器,在提供并发控制的前提下,通过优化,提升性能.本文主要讨论常见的并发容器的实现机制和绝妙之处,但并不会对所有实现细节面面俱到. 为什么JUC需要提 ...
- JAVA并发编程J.U.C学习总结
前言 学习了一段时间J.U.C,打算做个小结,个人感觉总结还是非常重要,要不然总感觉知识点零零散散的. 有错误也欢迎指正,大家共同进步: 另外,转载请注明链接,写篇文章不容易啊,http://www. ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
随机推荐
- JAVA提高十:ArrayList 深入分析
前面一章节,我们介绍了集合的类图,那么本节将学习Collection 接口中最常用的子类ArrayList类,本章分为下面几部分讲解(说明本章采用的JDK1.6源码进行分析,因为个人认为虽然JDK1. ...
- oracle数据库无监听程序
在电脑---服务---启动oracle tns 如果还是出现错误的话,找到Net Manager,将网络的ip监听删除,将本机的主机名配好,即可打开tns服务
- C#中判断语句 if、if-else if、switch-case
1.if一般用于一个条件的判断: 2.if-else if 一般用于多个条件的判断: 3.switch-case一般用于多个条件的判断. 注:if-else if与switch-case的区别在于:一 ...
- 用C写的计算运行时间
#include <stdio.h> #include <stdlib.h> #include <time.h> int main( void ) { long i ...
- VS2008 C++ 利用WinHttp API获取Http请求/响应头部Header
http://www.cnblogs.com/LCCRNblog/p/3833472.html 这一篇博客中,实现了获取http请求/响应后的html源码,现在需要获取http请求/响应的头部Head ...
- K - Kia's Calculation (贪心)
Kia's Calculation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others ...
- 一个“”字引发的痛苦经历
(一篇老文章,还有点价值,特意整理了一下.由于涉及客户项目,已经进行了脱敏处理) 1 写在前面的话 虽然这个问题是有解决方案的,但我不建议大家提供给客户,理由见此. 2 问题描述 2010.10.12 ...
- C#写的较完美验证码通用类
using System; using System.Collections; using System.ComponentModel; using System.Data; using System ...
- C#调用DLL文件时参数对应表
Wtypes.h中的非托管类型 非托管 C语言类型 托管类名 说明HANDLE void* Syste ...
- 设计模式的征途—12.享元(Flyweight)模式
现在在大力推行节约型社会,“浪费可耻,节俭光荣”.在软件系统中,有时候也会存在资源浪费的情况,例如,在计算机内存中存储了多个完全相同或者非常相似的对象,如果这些对象的数量太多将导致系统运行代价过高.那 ...