[Spark內核] 第42课:Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践
本课主题
- Broadcast 运行原理图
- Broadcast 源码解析
Broadcast 运行原理图
Broadcast 就是将数据从一个节点发送到其他的节点上; 例如 Driver 上有一张表,而 Executor 中的每个并行执行的Task (100万个Task) 都要查询这张表的话,那我们通过 Broadcast 的方式就只需要往每个Executor 把这张表发送一次就行了,Executor 中的每个运行的 Task 查询这张唯一的表,而不是每次执行的时候都从 Driver 中获得这张表!
Broadcast 是分布式的共享数据,默认情况下只要程序在运行 Broadcast 变量就会存在,因为 Broadcast 在底层是通过 BlockManager 管理的,Broadcast 是在创建 SparkContext 时被创建的!你也可以手动指定或者配置具体周期来销毁 Broadcast 变量!Broadcast 一般用于处理共享配置文件,通用的数据子,常用的数据结构等等;但是不适合存放太大的数据在Broadcast。Broadcast 不会内存溢出,因为其数据的保存的 Storage Level 是 MEMORY_AND_DISK 的方式(首先优先放在内存中,如果内存不够才放在磁盘上)虽然如此,我们也不可以放入太大的数据在 Broadcast 中,因为网络 I/O 和可能的单点压力会非常大!Broadcast 有两种方式,HttpBroadcast 和 TorrentBroadcast。
广播 Broadcast 变量只是只读变量,最为轻松的保持数据的一致性!
Broadcast 的使用如下:
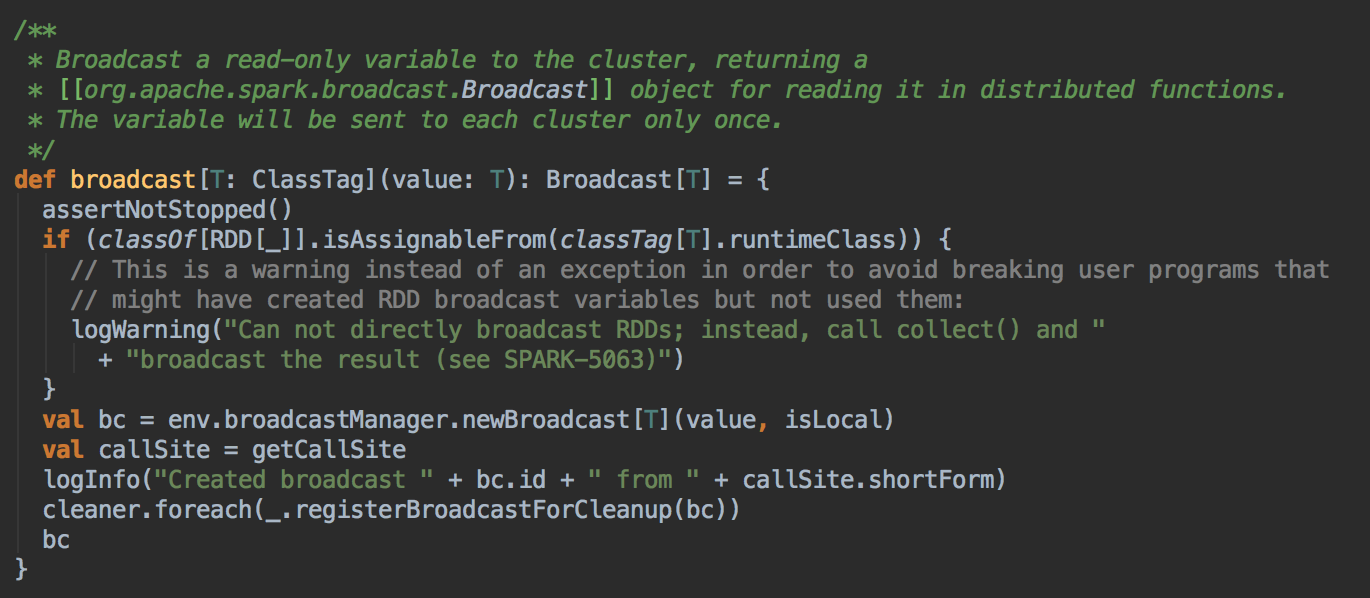
val broadcastVar = sc.broadcast(Array(1, 2, 3))
// broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0) broadcastVar.value
// res0: Array[Int] = Array(1, 2, 3)
[下图是 Broadcast 的原理图 - HttpBroadcast 的方式]
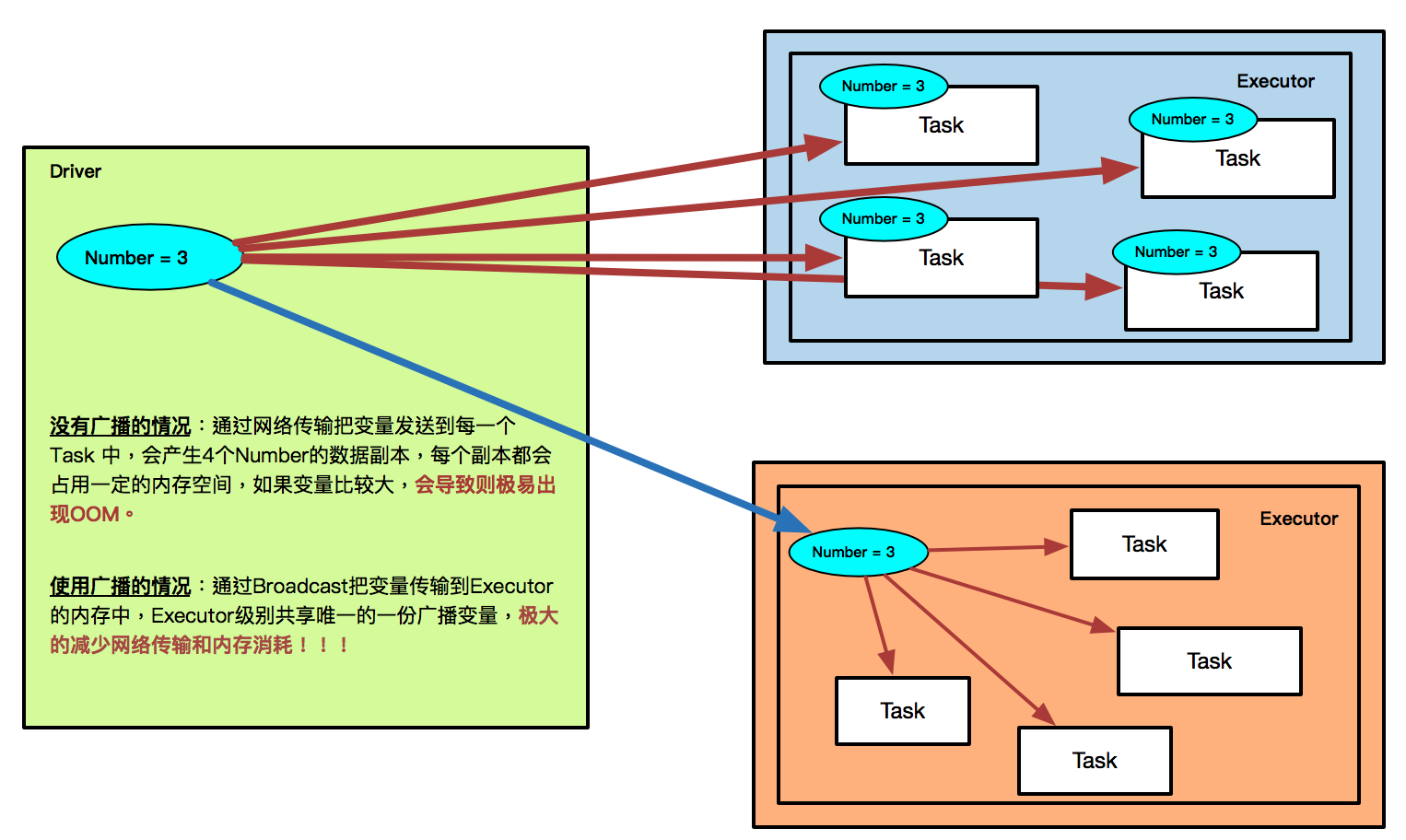
- 没有广播的情况:通过网络传输把变量发送到每一个 Task 中,会产生4个Number的数据副本,每个副本都会占用一定的内存空间,如果变量比较大,会导致则极易出现OOM。
- 使用广播的情况:通过Broadcast把变量传输到Executor的内存中,Executor级别共享唯一的一份广播变量,极大的减少网络传输和内存消耗! ! !
BT 的方式是,假设你 A 节点用了这个数据,A 节点也会作为一个数据来源或者是供应源,这个时候就有两个节点可以供应原数据,然后第三个节点用完之后也变成一个供应源,愈多节点用这副广播数据,会愈多供应源。
Broadcast 源码解析
HttpBroadcast 方式的 Broadcast
- 最开始的时候数据放在 Driver 的本地文件系统中,Driver 在本地会创建一个文件夹来存放 Broadcast 中的 data,然后启动 HttpServer 来访问文件夹中的数据,同时写入到BlockManager (Storage Level 是MEMORY_AND_DISK) 中获得 BlockId (BroadcastBlockId) ,当第一次 Executor 中的 Task 要访问 Broadcast 变量的时候,会向 Driver 通过 HttpServer 来访问数据, 然后会在 Executor 中的 Broadcast 中注册该 Broadcast 中的数据,这样后续需要的 Task 访问的 Broadcast 的变量的时候会首先查询BlockManager 中有没有该数据,如果有就直接使用;
- BroadcastManager 是用来管理 Broadcast,该实例是在 SparkContext 创建 SparkEnv 的时候创建的。

在实例化 BroadcastManager 的时候调用 initialized 方法,这个方法通过创建 BroadcastFactory 工厂类来构建具体的实际的 Broadcast 类型,默认是情况下是 TorrentBroadcastFactory
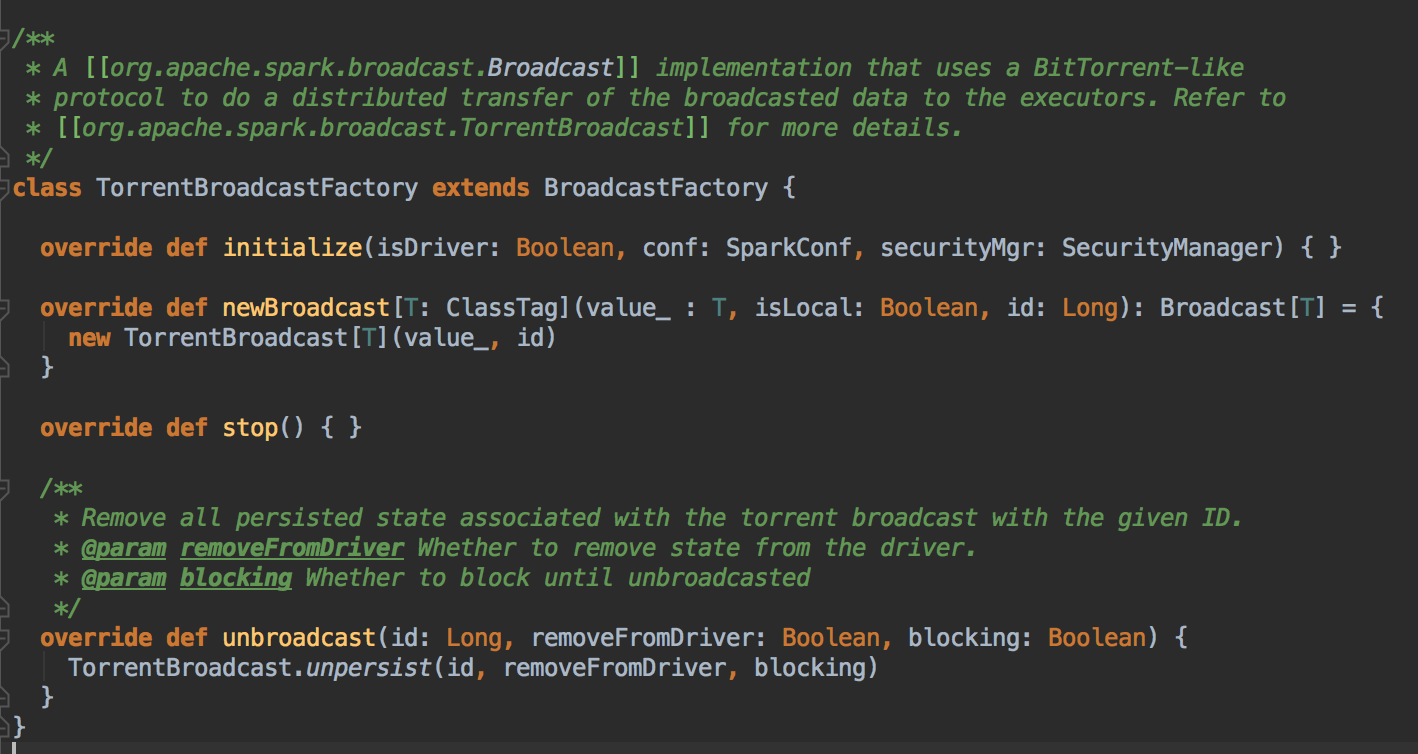
- HttpBroadcast 存在单点故障,和网络IO性能问题,所以默认使用 TorrentBroadcast 的方式,开始数据在 Driver 中,假设 A 节点用了数据,B 访问的时候 A 节点就变成数据源,依次类推,都是数据源,你数据的节点愈多,你获取数据的选择性就愈多,这样就不是导致一个节点压力太大,也不会导致在特定的节点上网络压力太大,数据源越多,节点压力会大大降低,当然是被 BlockManager 进行管理的。
- TorrentBroadcast 按照 Block_Size (默认是 4MB) 讲 Broadcast 中的数据划分为不同的 Block

然后将分块信息也就是 meta 信息存放到 Driver 的 BlockManager 中,同时会告诉 BlockManagerMaster,此时就会变成全局信息说明 Meta 信息存放完毕。
在 SparkContext 中手动调用 broadcast 方法
总结
第一种就是 HttpBroadcast,在 Driver 中创建一个文件夹,搞一个 HttpServer,你需要的话 Executor 通过 Http 抓一份过来,放在 BlockManager 中,下一次再用的话就首先到 BlockManager 取,BlockManager 没有再去 Driver 去取,所以这存在单点故障,和网络IO性能问题。
第二种就是 TorrentBroadcast,首先是 Driver 中有,创建一个文件夹,它是向 BroadcastManagerMaster 注册,然后 Executor 需要的话自己拿一份,拿一份的时候它要通知 BlockManagerMaster 就有另外一份副本,后绩 Executor 要拿副本就有多种选择。
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第42课:Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践
Spark源码图片取自于 Spark 1.6.0版本
[Spark內核] 第42课:Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践的更多相关文章
- [Spark內核] 第41课:Checkpoint彻底解密:Checkpoint的运行原理和源码实现彻底详解
本课主题 Checkpoint 运行原理图 Checkpoint 源码解析 引言 Checkpoint 到底是什么和需要用 Checkpoint 解决什么问题: Spark 在生产环境下经常会面临 T ...
- Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践
本课主题 Broadcast 运行原理图 Broadcast 源码解析 Broadcast 运行原理图 Broadcast 就是将数据从一个节点发送到其他的节点上; 例如 Driver 上有一张表,而 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Scala 深入浅出实战经典 第65讲:Scala中隐式转换内幕揭秘、最佳实践及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- Scala 深入浅出实战经典 第60讲:Scala中隐式参数实战详解以及在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第48讲:Scala类型约束代码实战及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Spark技术内幕:Client,Master和Worker 通信源码解析
http://blog.csdn.net/anzhsoft/article/details/30802603 Spark的Cluster Manager可以有几种部署模式: Standlone Mes ...
- Spark 源码解析:TaskScheduler的任务提交和task最佳位置算法
上篇文章< Spark 源码解析 : DAGScheduler中的DAG划分与提交 >介绍了DAGScheduler的Stage划分算法. 本文继续分析Stage被封装成TaskSet, ...
随机推荐
- Qt 显示图片的三种方法
一. 直接用QLabel显示原图 //单独显示的QLabel 其大小为内容即图片的大小,若将QLabel放入QMainWindow中则QLabel的大小为其初始大小. /* QLabel *label ...
- 使用oracle DB_LINK的一个注意点
今天使用db_link的时候遇到了个有趣的问题,和大家分享一下; 环境:Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bi ...
- Azure ARM (19) 将传统的ASM VM迁移到ARM VM (2)
<Windows Azure Platform 系列文章目录> 因为我们在上一节中: Azure ARM (18) 将传统的ASM VM迁移到ARM VM (1) 已经创建了Azure V ...
- Python开发工具PyCharm个性化设置
Python开发工具PyCharm个性化设置,包括设置默认PyCharm解析器.设置缩进符为制表符.设置IDE皮肤主题等,大家参考使用吧 1.设置默认PyCharm解析器: 操作如下: Pyt ...
- JQuery学习(4-2-phpserver端1)
主要内容:介绍图片的上传过程,涉及PHP跟JQuery: 1. 读取配置文件,连接MySQL数据库. 配置文件主要实username和password. 3-5.php <?php /* * v ...
- Ubuntu 16.06 安装拼音输入法 设置双拼
一不小心把Ubuntu删东西删坏了 呜- 刚好跟可恶的 下载 文件夹告别了 现在百度上的相关教程多多少少有些问题,多数过时了. +++++++++++++++++++++说正事专用分隔符++++++ ...
- intelliJ IDEA自动优化导入包设置
Settings→Editor→General→Auto Import 选中Optimize imports on the fly和Add unambiguous imports on the fly ...
- Linux配置文件注释注意:行首注释,不要行中注释
正确注释: # 注释语句 错误注释:这种注释可能导致文件读取异常或报错 有效语句 # 注释语句 # 注释语句
- 【java】正则表达式简单示例
public class Test { public static void main(String[] args) { String str="135axy"; String r ...
- C++ 头文件系列(stdexcept)
预定义异常类 这个头文件包含的内容非常简单,只包含9个异常类,均从exception类派生,因此我们用三张图来描述: 这里仅解释两点: overflow : 指值的大小超过 整型 变量能表示的范围,即 ...