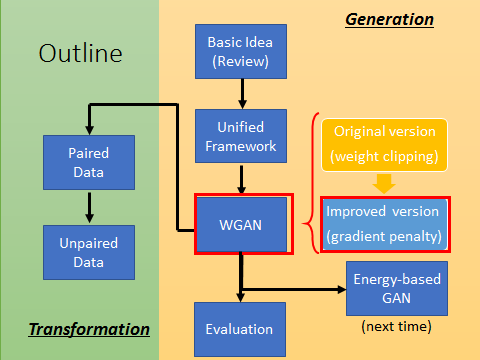
W-GAN系 (Wasserstein GAN、 Improved WGAN)
学习总结于国立台湾大学 :李宏毅老师
WGAN前作:Towards Principled Methods for Training Generative Adversarial Networks
WGAN: Wasserstein GAN
Improved WGAN: Improved Training of Wasserstein GANs
本文outline
一句话介绍WGAN: Using Earth Mover’s Distance to evaluate two distribution Earth Mover‘s Distance(EMD) = Wasserstein Distance
一. WGAN
1. Earth Mover’s Distance(EMD)
EMD: P和Q为两个分布:P分布为一堆土,Q分布为要移到的目标,那么要移动P达到Q,哪种距离更小呢?
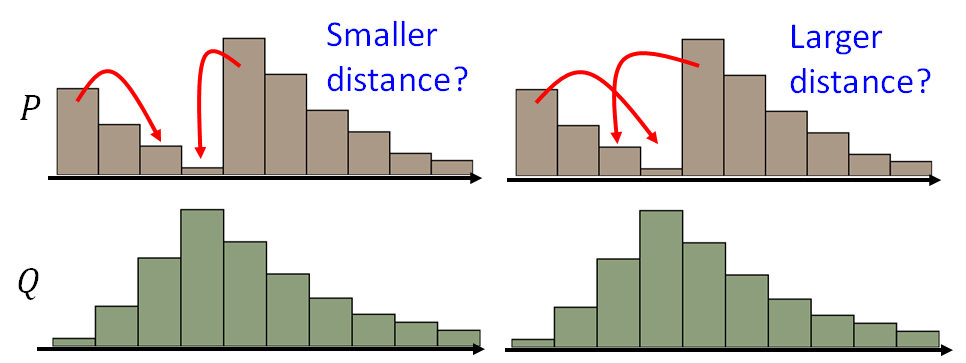
这里有许多种可能的moving plans,利用最小平均距离的moving plans来定义EMD
那么以下是最好的moving plans:
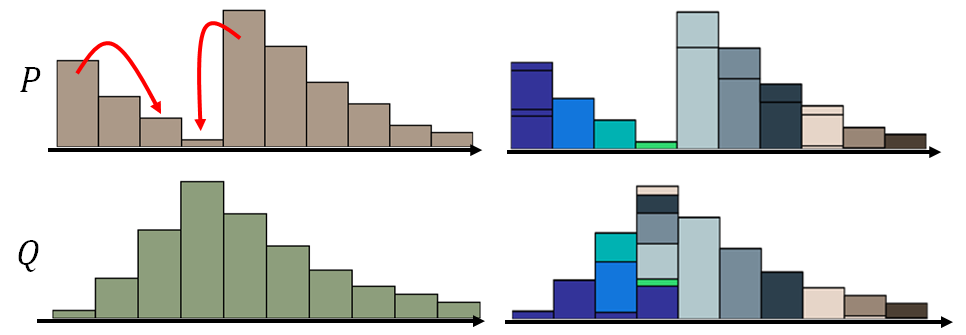
来用矩阵直观解释移土方案:

图中每个像素点对应row需要移出多少土到对应column, 越亮表示移动越多。注意每一个row的值加起来为对应P行的分布, 每个column的值加起来为对应Q行的分布。所以可以有很多的moving plan来实现:
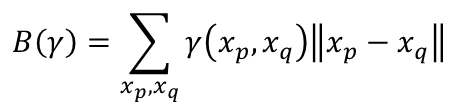
γ(xp,xq)表示从p移动多少土到q, || xp - xq ||表示pq之间的距离。上式就是给定一个plan时需要平均移动的距离。 那么EMD定义就是
穷举所有plan,EMD为最小的距离(最优的plan):
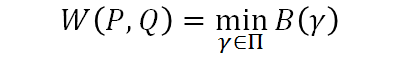
2. Why EMD
在更新过程中我们希望PG的分布和Pdata越来越相似:

但是Df(Pdata||PG): 因为从JS-divergence来看:无法从G0变到G100, 因为G50并没有比G0变小
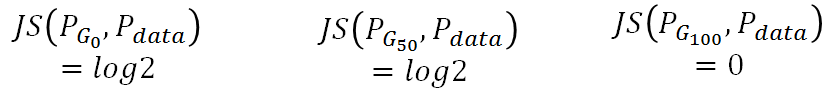
用W(Pdata, PG)则不同,G0对应的距离就是d0, G50对应的距离就是G50:所以利用Wasserstein距离时,model就会有动机使得分布趋于真实分布。
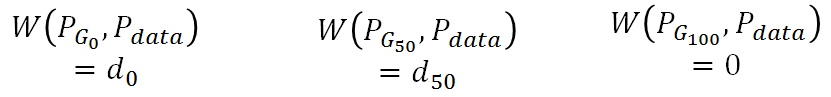
3. 回到GAN框架

我们知道所有的f-divergence都可以写成以下形式:
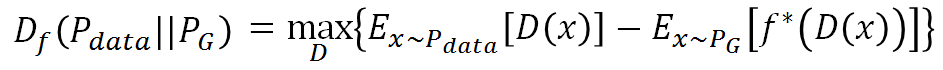 1)
1)
而Earth Mover’s Distance可以写成以下形式:
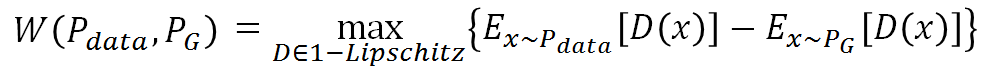 2)
2)
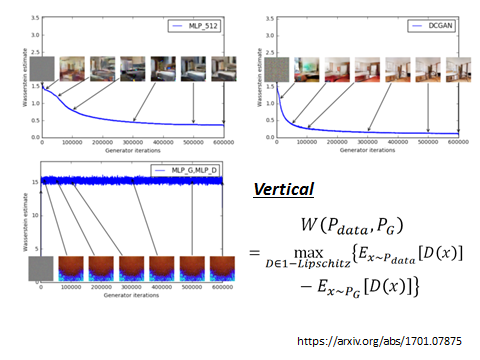
即找一个D使得大括号里的值最大,而限制是D属于1-Lipschitz。
Lipschitz Function: 输出的变化小于等于输入的变化, k=1时为 1-Lipschitz ,即变化的不要太猛烈。
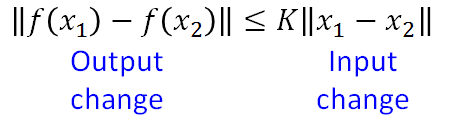
栗子:黑线为基准, 蓝线变化很猛烈不是1-Lipschitz, 而绿线变化缓和属于1-Lipschitz。
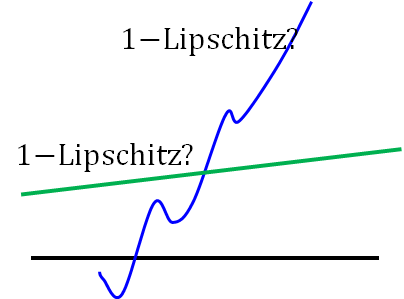
所以回到 2)式,如果没有对D的限制,当D(x1) 和D(x2)为正负无穷时可以最大化2)式,下图左。而现在对D有此限制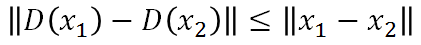 ,则D的取值如下图右:
,则D的取值如下图右:
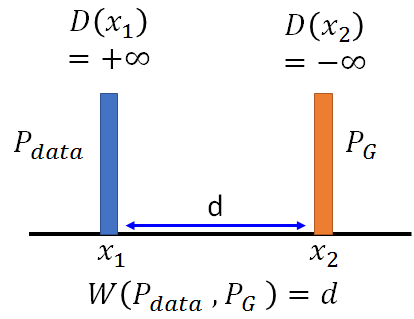
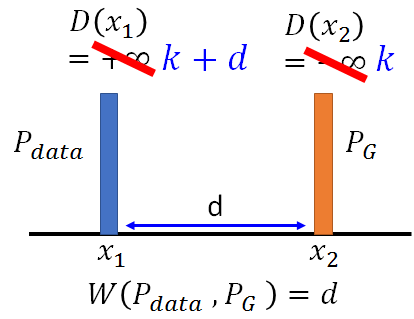
D(x1) 和D(x2)差距一定要小于d。下图说明了利用EMD的好处是PG可以沿着梯度移动到蓝色Pdata,而原生GAN的判别器D为而二元分类器,输出为sigmoid函数。对于蓝色和橙色的分布,原生GAN可能为蓝线:对应Pdata的输出值为1,对应PG的输出值为0。所以蓝色曲线在蓝色和橙色分布的梯度为0,根本没有动力去挪动generator的输出来更新。而EMD在两个分布附近都有梯度,可以继续更新。
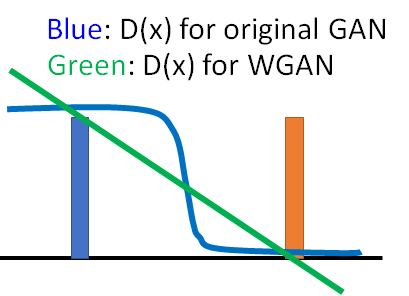
WGAN优点: WGAN will provide gradient to push PG towards Pdata
4. WGAN优化
那么怎么梯度更新呢?因为D有了限制,无法直接利用SGD。这里引入一种方法:Weight clipping
就是强制令权重w 限制在c ~ -c之间。在参数更新后,如果w>c,则令w=c, 如果w<-c,则令w=-c。我们这样做只为保证: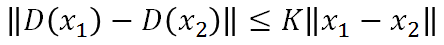
对权重的限制表示对NN的输入做一个变化,输出的变化总是有限的。实做上对于w进行限制:就可以限制了这条直线的斜率,否则D的输出为一条很斜的直线,且不断变直,给橙色的值越来越小,给蓝色的值越来越大,无法停止。

5. WGAN 算法


result:

原来的GAN是衡量JS-divergence,GAN是把JS-divergence train到底,所有case的结果几乎都是0,不管你generate的image好不好,JS-divergence都是个定值。那Discriminator就不是衡量JS-divergence,D的output就变得没有意义了。但是如果我们用WGAN的话,discriminator衡量的是EMD,而这个earth mover’s distance 衡量的就是两个分布真正的距离。所以看discriminator的loss可以真的表示出generate的图片的好坏。
6. WGAN 归纳
在 WGAN 中,D 的任务不再是尽力区分生成样本与真实样本,而是尽量拟合出样本间的 Wasserstein 距离,从分类任务转化成回归任务。而 G 的任务则变成了尽力缩短样本间的 Wasserstein 距离。
故 WGAN 对原始 GAN 做出了如下改变:
- D 的最后一层取消 sigmoid
- D 的 w 取值限制在 [-c,c] 区间内。
- 使用 RMSProp 或 SGD 并以较低的学习率进行优化 (论文作者在实验中得出的 trick)
WGAN 的个人一些使用经验总结,这些经验是基于自身的实验得出,仅供参考:
- WGAN 的论文指出使用 MLP,3 层 relu,最后一层使用 linear 也能达到可以接受的效果,但根据我实验的经验上,可能对于彩色图片,因为其数值分布式连续,所以使用 linear 会比较好。但针对于 MINST 上,因为其实二值图片,linear 的效果很差,可以使用 batch normalization sigmoid 效果更好。
- 不要在 D 中使用 batch normalization,估计原因是因为 weight clip 对 batch normalization 的影响
- 使用逆卷积来生成图片会比用全连接层效果好,全连接层会有较多的噪点,逆卷积层效果清晰。
- 关于衡量指标,Wasserstein distance 距离可以很好的衡量 WGAN 的训练进程,但这仅限于同一次,即你的代码从运行到结束这个过程内。
7. WGAN总结
WGAN前作分析了Ian Goodfellow提出的原始GAN两种形式各自的问题,第一种形式等价在最优判别器下等价于最小化生成分布与真实分布之间的JS散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及JS散度的突变特性,使得生成器面临梯度消失的问题;第二种形式在最优判别器下等价于既要最小化生成分布与真实分布直接的KL散度,又要最大化其JS散度,相互矛盾,导致梯度不稳定,而且KL散度的不对称性使得生成器宁可丧失多样性也不愿丧失准确性,导致collapse mode现象。
WGAN前作针对分布重叠问题提出了一个过渡解决方案,通过对生成样本和真实样本加噪声使得两个分布产生重叠,理论上可以解决训练不稳定的问题,可以放心训练判别器到接近最优,但是未能提供一个指示训练进程的可靠指标,也未做实验验证。
WGAN本作引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。接着通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来最大化这个形式,就可以近似Wasserstein距离。在此近似最优判别器下优化生成器使得Wasserstein距离缩小,就能有效拉近生成分布与真实分布。WGAN既解决了训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。作者对WGAN进行了实验验证。
二. Improved WGAN
A differentiable function is 1-Lipschitz if and only if it has gradients with norm less than or equal to 1 everywhere.
就是说如果一个函数是1-Lipschitz,那么它的gradients with morm <=1: 
注意这里的gradient不是对参数,而是input对output的gradient,即x对D(x)的gradient。
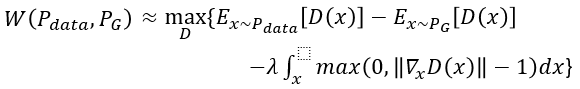
注意此惩罚项penalty:如果梯度的norm>1就会惩罚,即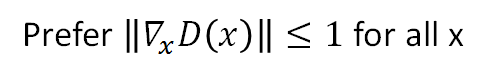 ,因不可能对所有x作积分,所以对sample的x求期望
,因不可能对所有x作积分,所以对sample的x求期望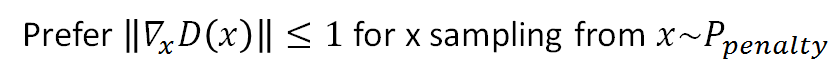
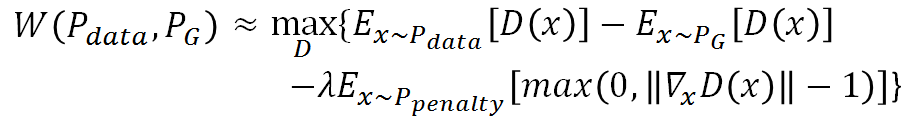
那Ppenalty是什么呢,怎么从Ppenalty sample x呢?首先从Pdata sample一个点,再从PG sample一个点,然后在其连线中sample出x,即x是在Pdata 和 PG 之间的区域中sample:
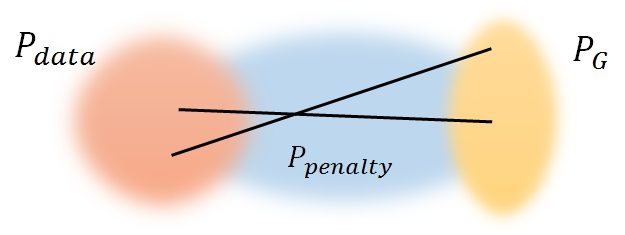
Only give gradient constraint to the region between
W-GAN系 (Wasserstein GAN、 Improved WGAN)的更多相关文章
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- (转) Read-through: Wasserstein GAN
Sorta Insightful Reviews Projects Archive Research About In a world where everyone has opinions, on ...
- Wasserstein GAN最新进展:从weight clipping到gradient penalty,更加先进的Lipschitz限制手法
前段时间,Wasserstein GAN以其精巧的理论分析.简单至极的算法实现.出色的实验效果,在GAN研究圈内掀起了一阵热潮(对WGAN不熟悉的读者,可以参考我之前写的介绍文章:令人拍案叫绝的Was ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
- 关于Wasserstein GAN的一些笔记
这篇笔记基于上一篇<关于GAN的一些笔记>. 1 GAN的缺陷 由于 $P_G$ 和 $P_{data}$ 它们实际上是 high-dim space 中的 low-dim manifol ...
- 使用Wasserstein GAN生成小狗图像
一.前期学习经过 GAN(Generative Adversarial Nets)是生成对抗网络的简称,由生成器和判别器组成,在训练过程中通过生成器和判别器的相互对抗,来相互的促进.提高.最近一段时间 ...
- Wasserstein GAN
在GAN的相关研究如火如荼甚至可以说是泛滥的今天,一篇新鲜出炉的arXiv论文<Wasserstein GAN>却在Reddit的Machine Learning频道火了,连Goodfel ...
- 不要怂,就是GAN (生成式对抗网络) (六):Wasserstein GAN(WGAN) TensorFlow 代码
先来梳理一下我们之前所写的代码,原始的生成对抗网络,所要优化的目标函数为: 此目标函数可以分为两部分来看: ①固定生成器 G,优化判别器 D, 则上式可以写成如下形式: 可以转化为最小化形式: 我们编 ...
- ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution
ASEGAN:WGAN音频超分辨率 这篇文章并不具有权威性,因为没有发表,说不定是外国的某个大学的毕业设计,或者课程结束后的作业.或者实验报告. CS230: Deep Learning, Sprin ...
随机推荐
- 自学Zabbix之路15.1 Zabbix数据库表结构简单解析-Hosts表、Hosts_groups表、Interface表
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix之路15.1 Zabbix数据库表结构简单解析-Hosts表.Hosts_grou ...
- 【51NOD 1847】奇怪的数学题(莫比乌斯反演,杜教筛,min_25筛,第二类斯特林数)
[51NOD 1847]奇怪的数学题(莫比乌斯反演,杜教筛,min_25筛,第二类斯特林数) 题面 51NOD \[\sum_{i=1}^n\sum_{j=1}^nsgcd(i,j)^k\] 其中\( ...
- luogu4268 Directory Traversal (dfs)
题意:给一个树状的文件结构,让你求从某个文件夹出发访问到所有文件,访问路径字符串长度之和的最小值,其中,访问父节点用..表示,两级之间用/分割 做两次dfs,第一次算DownN[x]和DownS[x] ...
- Java -- JDBC 学习--调用函数&存储过程
调用函数&存储过程 /** * 如何使用 JDBC 调用存储在数据库中的函数或存储过程 */ @Test public void testCallableStatment() { Connec ...
- Luogu 2540 斗地主增强版(搜索,动态规划)
Luogu 2540 斗地主增强版(搜索,动态规划) Description 牛牛最近迷上了一种叫斗地主的扑克游戏.斗地主是一种使用黑桃.红心.梅花.方片的A到K加上大小王的共54张牌来进行的扑克牌游 ...
- luogu P4198 楼房重建——线段树
题目大意: 小A在平面上(0,0)点的位置,第i栋楼房可以用一条连接(i,0)和(i,Hi)的线段表示,其中Hi为第i栋楼房的高度.如果这栋楼房上任何一个高度大于0的点与(0,0)的连线没有与之前的线 ...
- Gradle安装 Gradle效率提升 eclipse安装gradle插件 【我】
Gradle安装 从官网下载 gradle4.6版本,也可以从svn地址下载 https://downloads.gradle.org/distributions/gradle-4.6-bin.zip ...
- NOIP 普及组 2016 回文日期
传送门 https://www.cnblogs.com/violet-acmer/p/9859003.html 题解: 思路1: 相关变量解释: year1,month1,day1 : date1对应 ...
- (注意格式,代替C++的getchar())汉字统计hdu2030
汉字统计 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submi ...
- nginx 中配置多个location并解决js/css/jpg/等的加载问题
2017-11-09 22:07 277人阅读 评论(0) 收藏 举报 分类: linux(1) 版权声明:如有版权问题,请私信我. ECS:阿里云 系统:ubuntu 16.04 我的配置文件位 ...