B+树索引和哈希索引的区别[转]
导读
在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议。
二者区别
备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BTREE,例如像下面这样的写法:
CREATE TABLE t(
aid int unsigned not null auto_increment,
userid int unsigned not null default 0,
username varchar(20) not null default ‘’,
detail varchar(255) not null default ‘’,
primary key(aid),
unique key(uid) USING BTREE,
key (username(12)) USING BTREE — 此处 uname 列只创建了最左12个字符长度的部分索引
)engine=InnoDB;
一个经典的B+树索引数据结构见下图: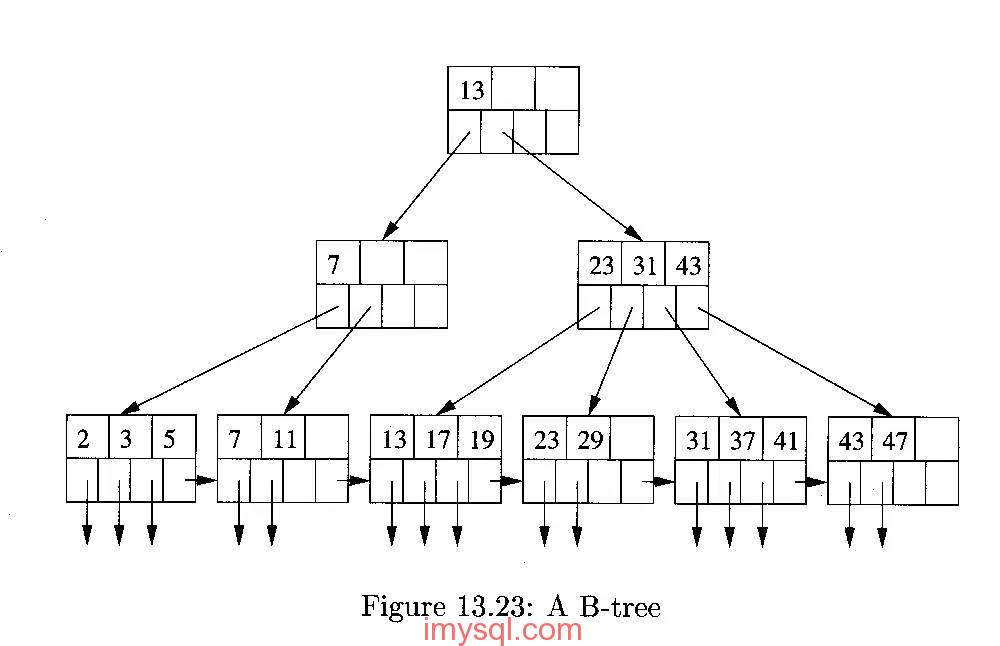
(图片源自网络)
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接。
在B+树上的常规检索,从根节点到叶子节点的搜索效率基本相当,不会出现大幅波动,而且基于索引的顺序扫描时,也可以利用双向指针快速左右移动,效率非常高。
因此,B+树索引被广泛应用于数据库、文件系统等场景。顺便说一下,xfs文件系统比ext3/ext4效率高很多的原因之一就是,它的文件及目录索引结构全部采用B+树索引,而ext3/ext4的文件目录结构则采用Linked list, hashed B-tree、Extents/Bitmap等索引数据结构,因此在高I/O压力下,其IOPS能力不如xfs。
详细可参见:
https://en.wikipedia.org/wiki/Ext4
https://en.wikipedia.org/wiki/XFS
而哈希索引的示意图则是这样的:
(图片源自网络)
简单地说,哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
从上面的图来看,B+树索引和哈希索引的明显区别是:
- 如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
- 从示意图中也能看到,如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
- 同理,哈希索引也没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
- 哈希索引也不支持多列联合索引的最左匹配规则;
- B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
后记
在MySQL中,只有HEAP/MEMORY引擎表才能显式支持哈希索引(NDB也支持,但这个不常用),InnoDB引擎的自适应哈希索引(adaptive hash index)不在此列,因为这不是创建索引时可指定的。
还需要注意到:HEAP/MEMORY引擎表在mysql实例重启后,数据会丢失。
通常,B+树索引结构适用于绝大多数场景,像下面这种场景用哈希索引才更有优势:
在HEAP表中,如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,没有范围查询、没有排序的时候,特别适合采用哈希索引
例如这种SQL:
SELECT … FROM t WHERE C1 = ?; — 仅等值查询
在大多数场景下,都会有范围查询、排序、分组等查询特征,用B+树索引就可以了。
http://imysql.com/2016/01/06/mysql-faq-different-between-btree-and-hash-index.shtml
B+树索引和哈希索引的区别[转]的更多相关文章
- B+树索引和哈希索引的区别——我在想全文搜索引擎为啥不用hash索引而非得使用B+呢?
哈希文件也称为散列文件,是利用哈希存储方式组织的文件,亦称为直接存取文件.它类似于哈希表,即根据文件中关键字的特点,设计一个哈希函数和处理冲突的方法,将记录哈希到存储设备上. 在哈希文件中,是使用一个 ...
- MySQL B+树索引和哈希索引的区别
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BT ...
- MySQL B+树索引和哈希索引的区别(转 JD二面)
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BTRE ...
- mysql索引之一:索引基础(B-Tree索引、哈希索引、聚簇索引、全文(Full-text)索引区别)(唯一索引、最左前缀索引、前缀索引、多列索引)
没有索引时mysql是如何查询到数据的 索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储10 ...
- mysql索引之哈希索引
哈希算法 哈希算法时间复杂度为O(1),且不只存在于索引中,每个数据库应用中都存在该数据结构. 哈希表 哈希表也为散列表,又直接寻址改进而来.在哈希的方式下,一个元素k处于h(k)中,即利用哈希函数h ...
- B+树索引和哈希索引的明显区别是:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值:当然了,这个前提是,键值都是唯一的.如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到 ...
- mysql索引是什么?索引结构和使用详解
索引是什么 mysql索引: 是一种帮助mysql高效的获取数据的数据结构,这些数据结构以某种方式引用数据,这种结构就是索引.可简单理解为排好序的快速查找数据结构.如果要查“mysql”这个单词,我们 ...
- MySQL索引(一)索引基础
索引是数据库系统里面最重要的概念之一.一句话简单来说,索引的出现其实是为了提高数据查询的效率,就像书的目录一样. 常见模型 索引的出现是为了提高查询效率,但是实现索引的方式却有很多种,这里就介绍三种常 ...
- Mysql-高性能索引策略及不走索引的例子总结
Mysql-高性能索引策略 正确的创建和使用索引是实现高性能查询的基础.我总结了以下几点索引选择的策略和索引的注意事项: 索引的使用策略: (PS:索引的选择性是指:不重复的索引值,和数据表的记录总数 ...
随机推荐
- [转] equals和==的区别小结
==: == 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象.比较的是真正意义上的指针操作. 1.比较的是操作符两端的操作数是否是同一个对象 ...
- thinkphp验证码的使用
thinkphp不仅封装了验证规则 还封装了验证码 文件的位置是ThinkPHP\Library\Think\Verify.class.php 下面简单的说一下如何使用 我们现在控制器里新建一个方法 ...
- Redis数据结构之字符串
学习阶段分成两个部分,一个是redis客户端,一个是java客户端操作 一:在redis客户端操作 1.先删除里面的几个key 2.set与get与getset 3.数值的增减 值递增1,或者减一 如 ...
- 用mybatis的代码自动生成工具,炒鸡好用,推荐一下别人的操作
http://www.cnblogs.com/smileberry/p/4145872.html
- [OpenCV-Python] OpenCV 中视频分析 部分 VI
部分 VI视频分析 OpenCV-Python 中文教程(搬运)目录 39 Meanshift 和 和 Camshift 目标 • 本节我们要学习使用 Meanshift 和 Camshift 算法在 ...
- HDU 2612 find a way 【双BFS】
<题目链接> 题目大意:两个人分别从地图中的Y 和 M出发,要共同在 @ 处会面(@不止有一处),问这两个人所走距离和的最小值是多少. 解题分析: 就是对这两个点分别进行一次BFS,求出它 ...
- 【*】CAS 是什么,Java8是如何优化 CAS 的
文章结构 前言 想要读懂 Java 中的并发包,就是要先读懂 CAS 机制,因为 CAS 是并发包的底层实现原理.本文主要讨论 CAS 是如何保证操作的原子性的 Java8 对 CAS 进行了哪些 ...
- 三篇文章带你极速入门php(二)之迅速搭建php环境
前言 今天讲一下php在windows,mac,linux上的集成环境搭建,目标是简单快速,环境这个事得对号入座,windows用phpstudy,mac用mamp,linux用lnmp一键安装,直接 ...
- UTF8编码的Base64解密 MSSQL实现
GO CREATE FUNCTION [dbo].[c_GetUTF8Code] ( @char Nchar ) RETURNS int AS --UTF8转码 BEGIN Declare @Code ...
- beta到production版本上线
1.beta版本到production上线,production要发到预发布测试一下避免配置问题导致发布异常.