seq2seq和attention应用到文档自动摘要
一、摘要种类
抽取式摘要
直接从原文中抽取一些句子组成摘要。本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余(方法是MMR)等。这种方式应用最广泛,因为比较简单。经典方法有LexRank和整数线性规划(ILP)。
LexRank是将文档中的每个句子都看作节点,句子之间的相似度看作节点之间的边的权重,构建一个graph;然后再计算每个节点的分数,这个打分的计算方式可以是度中心度(Degree centrality)、PageRank中心度等(论文里说这两种计算方式其实效果没有太大差别,文中用的ROUGE-1作为指标);这个方法的要点在于:不能每两个句子之间都有边,要设定一个阈值,只有相似度大于这个阈值才能有边,阈值太大则丢失太多信息,阈值太小则又引入了太多噪声。
压缩式摘要
有两种方式:一种是pipeline,先抽取出句子,再做句子压缩,或者先做句子压缩,再抽句子。另一种是jointly的方式,抽句子和压缩句子这两个过程是同时进行的。
句子压缩(Sentence compression)的经典方法是ILP:句子中的每个词都对应一个二值变量表示该词是否保留,并且每个词都有一个打分(比如tf-idf),目标函数就是最大化句子中的词的打分;既然是规划那当然要给出限制,最简单的限制比如说至少保留一个词,再比如说当形容词被保留时其修饰的词也要保留(根据parse tree)。
理解式摘要
也叫产生式摘要,试图理解原文的意思,然后生成摘要,也就是像我们人做摘要那样来完成任务。
从是否有用户查询的角度来说,可以分为通用型摘要(generic)和基于用户查询的摘要(query-oriented),其中后者不仅要求生成的摘要应概括原文关键信息,还要尽可能与用户查询具有很高的相关性。
二、评价指标
首先可以是人工评价。目前来说,自动评价指标采用的是ROUGE,R是recall的意思,换句话说,这个指标基于摘要系统生成的摘要与参考摘要的n元短语重叠度:
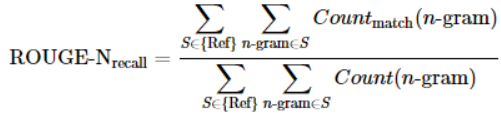
摘要这个任务要求用短序列概括长序列,用召回率这样的计算思路可以反映出人工给出的参考摘要所列出的要点中有多少被包含在了机器生成的摘要中。这个指标用来应付抽取式摘要可能问题不大,但是由于其无法评价所生成摘要的语法和语义,而且倾向于长摘要,所以其实还应该继续探索更合理的指标来评价理解式摘要。此外,当然也可以计算基于precision的ROUGE,而且ROUGE还有ROUGE-L等多种版本;最常使用的是ROUGE-N的N取2的方式(也就是ROUGE-2)。评测工具的链接是这里(https://github.com/RxNLP/ROUGE-2.0)。
三、Seq2seq与encoder-decoder
如果只说“序列到序列”的话,那么词性标注(POS)其实也是这样的过程。但是它跟翻译、摘要显著不同的地方在于:在POS问题中,输入和输出是一一对应的,而翻译、摘要的输出序列与输入序列则没有显著的对应关系。所以如下图所示,POS问题可以用最右边的那个RNN结构来建模,每个时刻的输入与输出就是词与词性。相比之下,翻译、摘要这种则可以通过倒数第二张图那样的结构来解决,这个结构可以看作是encoder和decoder都是RNN的encoder-decoder框架。

1. encoder-decoder
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。
这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
2. attention mechanism 注意力机制
为了解决上面提到的问题,一种可行的方案是引入attention mechanism。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention:
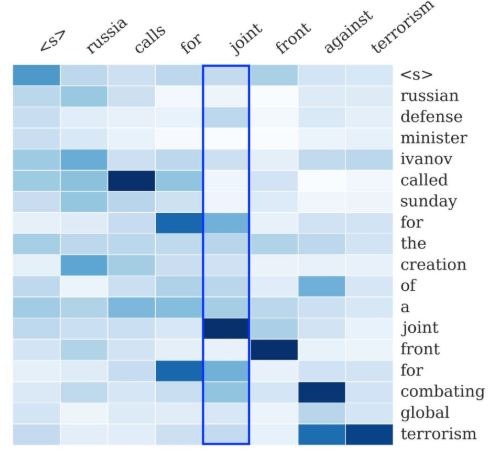
下图也展示了这一点:右侧序列是输入序列,上方序列是输出序列。输出序列的每个词都对应一个概率分布,这个概率分布决定了在生成这个词的时候,对于输入序列的各个词的关注程度。如图所示,看蓝色框起来的那一列,就是模型在生成joint这个词时的概率分布,颜色最深的地方对应的是输入的joint,说明模型在生成joint这个词时最为关注的输入词是joint。所谓attention,就是说生成每个词时都为这个词得到这个概率分布,进而可以使生成的词“更好”。
参考文献:
【1】seq2seq和attention如何应用到文档自动摘要
seq2seq和attention应用到文档自动摘要的更多相关文章
- DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
两周以前读了些文档自动摘要的论文,并针对其中两篇( [2] 和 [3] )做了presentation.下面把相关内容简单整理一下. 文本自动摘要(Automatic Text Summarizati ...
- 【原创】利用doxygen来管理项目文档或注释
一.doxygen应用场景: doxygen可以用来管理目前主流的编程语言的注释而形成文档系统.(包括C, C++, C#, Objective-C, IDL, Java, VHDL, PHP, Py ...
- ABP文档 - 通知系统
文档目录 本节内容: 简介 发送模式 通知类型 通知数据 通知重要性 关于通知持久化 订阅通知 发布通知 用户通知管理器 实时通知 客户端 通知存储 通知定义 简介 通知用来告知用户系统里特定的事件发 ...
- 自动文档摘要评价方法:Edmundson,ROUGE
自动文档摘要评价方法大致分为两类: (1)内部评价方法(Intrinsic Methods):提供参考摘要,以参考摘要为基准评价系统摘要的质量.系统摘要与参考摘要越吻合, 质量越高. (2)外部评价方 ...
- ABP文档笔记 - 通知
基础概念 两种通知发送方式 直接发送给目标用户 用户订阅某类通知,发送这类通知时直接分发给它们. 两种通知类型 一般通知:任意的通知类型 "如果一个用户发送一个好友请求,那么通知我" ...
- 关于CSS自文档的思考_css声明式语言式代码注释
obert C. Martin写的<Clean Code>是我读过的最好的编程书籍之一,若没有读过,推荐你将它加入书单. 注释就意味着代码无法自说明 —— Robert C. Martin ...
- 文档生成工具——Doxygen
参考: 1.https://blog.csdn.net/liao20081228/article/details/77322584 2.https://blog.csdn.net/wang150619 ...
- hugo主题文档-manpassant
+++ date="2020-10-17T10:32:00+08:00" title="hugo主题文档manpassant" tags=["hugo ...
- C#给PDF文档添加文本和图片页眉
页眉常用于显示文档的附加信息,我们可以在页眉中插入文本或者图形,例如,页码.日期.公司徽标.文档标题.文件名或作者名等等.那么我们如何以编程的方式添加页眉呢?今天,这篇文章向大家分享如何使用了免费组件 ...
随机推荐
- PHP数组总结,,PHP面向对象思维思路。
<?php //定义数组 $attr = array(); $attr[] = ; //索引数组 $attr = array(,,,); //关联数组 $attr = array("c ...
- MSSQL SQL Server代理 作业 设置(调用存储过程)
1.新建作业名 “生成分区文件及文件组“ 2.新建 步骤 名 “CreatePartTable” 步骤名:CreatePartTable 类型:Transact-SQL 脚本(T-SQL) 数据库 ...
- hdu4763 Theme Section【next数组应用】
Theme Section Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tot ...
- HDU 4699 - Editor - [对顶栈]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4699 Problem Description Sample Input8I 2I -1I 1Q 3LD ...
- [cloud][sdn] neutron了解
了解 neutron 文档:https://yeasy.gitbooks.io/openstack_understand_neutron/content/ LB讲的不细.DVR讲的不清晰. 读了全文之 ...
- [cloud][sdn] openstack openflow opendaylight openvswitch
https://www.quora.com/What-is-the-relation-between-OpenStack-OpenDaylight-OpenFlow-and-Open-vSwitch- ...
- LeetCode 104 Maximum Depth of Binary Tree 解题报告
题目要求 Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the ...
- 《Linux 文本处理》- awk 分析 nginx 日志
废话不多说,简单了解一下 awk - 强大的文本分析工具,也就是分析日志 最常用的就是分析日志了吧,做统计什么,这里也拿 nginx 日志来做分析 1:统计出现次数 - 比如状态码出现次数 - 先直接 ...
- mysql分库 分表
原文链接:http://www.jianshu.com/p/89311703b320 传统的分库分表传统的分库分表都是通过应用层逻辑实现的,对于数据库层面来说,都是普通的表和库.分库分库的原因 首先, ...
- eclipse怎么解决Failed to load the JNIshared library
Q: 打开eclipse打开报Failed to load the JNIshared library的错误. A:jdk的位数跟eclipse位数一致即可解决. 把eclipse下载64位即可 cm ...