Hadoop学习笔记之五:HDFS功能逻辑(1)
Block Report
DataNode会周期性(默认1小时)将自身节点全部block信息发送给NameNode,以让NameNode正确确维护block信息。
在Block Report的数据源DataNode端,处理逻辑比较简单,对磁盘上的所有Block文件进行遍历保存到一张表中,然后发送给NameNode;
在NameNode端,将该block report与blocksMap中该DataNode的block列表(参见BlocksMap)进行比较和处理,比较处理过程如下: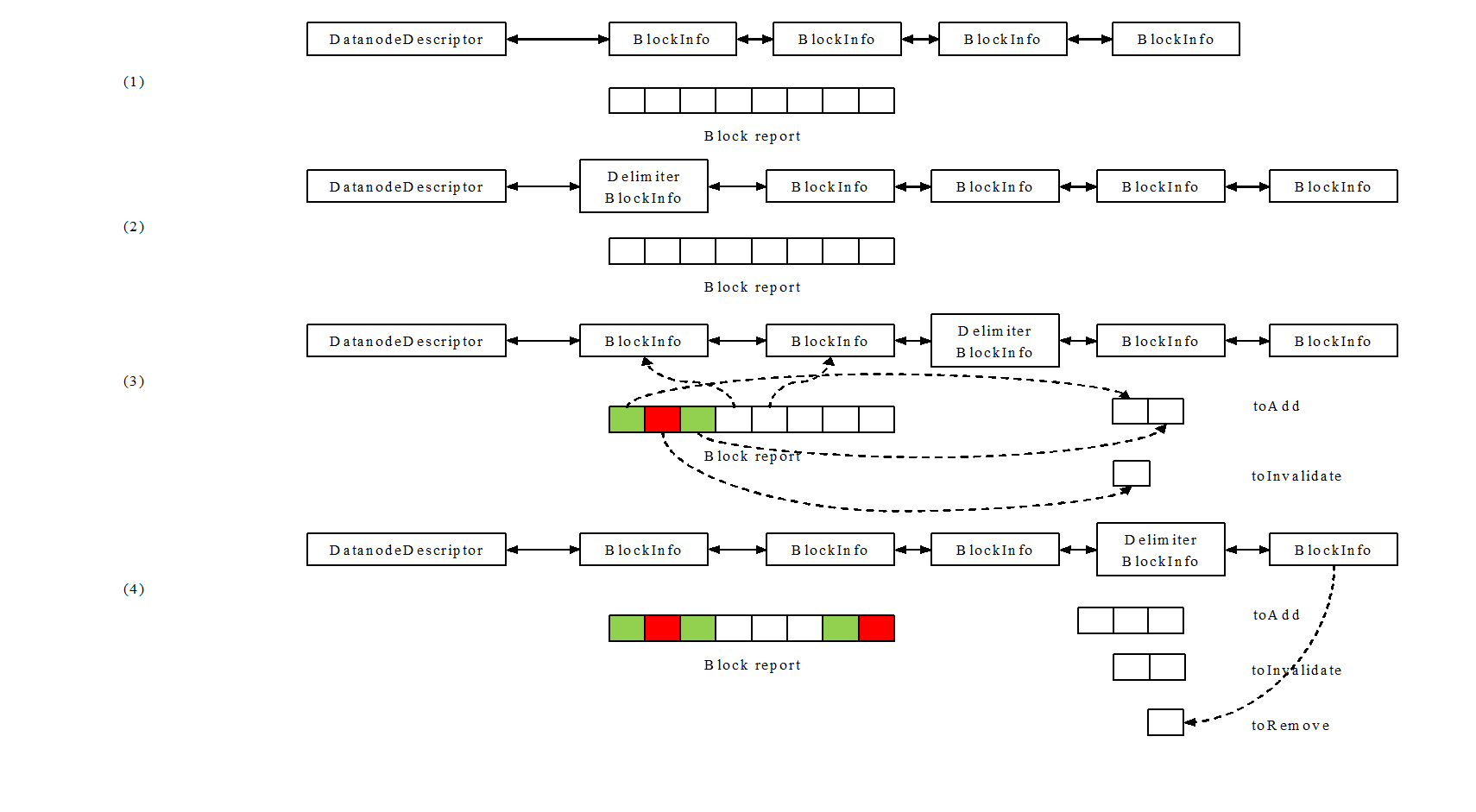
- 获取同一datanode的block list和最新的block report;
- 在block list头部插入一个分割用的空BlockInfo(Delimiter BlockInfo);
- 将block report中的block与block list及整个blocksMap进行比较,如果
- 在blocksMap中找到完全相符的block,则接收该block;(a)
- 在blocksMap中找到id相同、版本号不同的block,且所属文件仍然存在,且如果block report的版本号较高、或文件仍未关闭,则接收该block;(b)
- 对于a、b中接收的block,如果其存在该datanode的block list中,则将该block移到block list头部;(c)
- 对于a、b中接收的block,如果其不存在该datanode的block list中,则添加到toAdd队列中,之后会更新blocksMap,使其进入该datanode的block list;(d)
- 对于a、b中不接收的block,添加到toInvalidate中,之后会通知datanode对该block文件进行删除;(e)
- 此时Delimiter BlockInfo之前的是在block report中出现过的Block,之后的是未在block report中出现过的Block;将Delimiter BlockInfo之后的block加入toRemove队列;之后会更新blocksMap,将这些block对象从该datanode的block list中删除;
Checkpoint(检查点)
HDFS通过检查点机制对命名空间的磁盘存储文件进行合并,生成新的fsImage及edits,这个过程简记为doCheckpoint。关于命名空间的磁盘存储详见Namespace;
整个过程由secondaryNameNode发起,并引发NameNode内存经过一轮状态机变换,最终完成合并。下图描述的是整个doCheckpoint过程中NameNode的CheckPointState状态转换: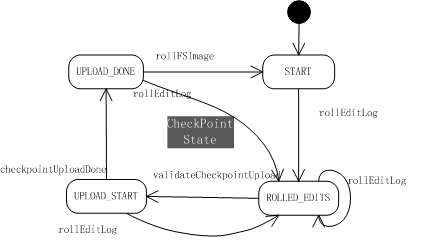
- 初始状态为START;当NameNode处于UPLOAD_DONE状态,通过rollFSImage舍弃旧的fsImage和旧的edits,保存新的fsImage和新的edits,会将状态置回START;
- 通过rollEditLog函数后,生成新的edits.new文件存储新的命名空间修改,状态转换为ROLLED_EDITS;
- secondaryNameNode下载fsImage及旧的edits文件后,合并成新的检查点,通知NameNode下载;NameNode会通过validateCheckpointUpload进行检查,确认可以获取新的检查点后,状态转入UPLOAD_START;
- NameNode获取新的检查点后,通过checkpointUploadDone将状态置为UPLOAD_DONE;
doCheckpoint过程中命名空间磁盘存储文件的变化过程如下图所示:
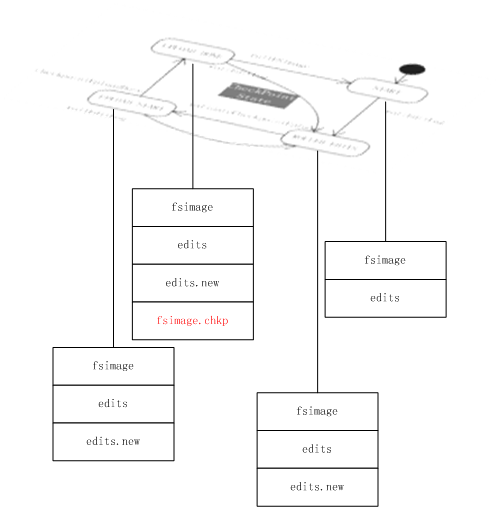
- START状态下始终是fsimage生edits文件;
- 状态机经过2后,出现edits.new文件,edits文件不再修改;
- 状态机经过4后,出现新的fsimage.chkp文件;
对该状态机进行几点特殊说明:
- NameNode为支持配备多个secondaryNameNode,因而当状态机转换至3、4步时,需要获取一个互斥锁;(防止多个SNN并发导致异常)
- 第2步rollEditLog时NameNode会生成一个令牌(edits的最终修改时间);在状态转换进入3时,会对令牌进行检查;(保证数据一致)
- 为应对SecondaryNameNode可能在任意状态意外宕机,rollEditLog函数不对前一状态进行检查(可从任意状态到达ROLLED_EDITS);
Decommission(退役)
hadoop管理员可以通过hdfs的配置文件hdfs-site.xml,设定dfs.hosts及dfs.hosts.exclude,指明对应的文件路径,以指定允许/排除的集群节点(写在文件内容中),如果不设定dfs.hosts,则认为任何节点都允许加入集群。
hadoop客户端可以向NameNode发起refreshNodes的请求,促使NameNode读取这两个文件,并与当前集群中的DataNode节点进行比对,如果:
- 某个DN不在允许的节点列表中,则立即设定其 Decommission;
- 某DN在允许的节点列表中,同时也在排除的节点列表中,则设定其开始进行Decommission(如果还没开始);
- 某DN在允许的节点列表中,且不在排除的节点列表中,但却处于已经Decommissioned或正在进行Decommission的状态,则立即停止其Decommission。
当NameNode标记一个DN进入Decommission状态后,该DN上所有数据块的副本都不再记入有效副本个数,导致NameNode发现这些数据块的副本数不足,从而加入到NameNode的neededReplications集合中,以便在适当的时候通知相应DN对数据块进行复制;
NameNode使用一个线程,通过 DecommissionManager.Monitor进行定期检查,默认是每30秒进行一次检查:
如果DN正在进行Decommission行为,查看其是否完成了所有数据块的副本复制(耗时操作),如果完成,则标记为Decommissioned完成;对检查到的进行Decommission的节点进行计数,满5个就结束;
如果进行Decommission的DN数不足5个,则会扫描掉所有DN;
Heartbeat(心跳)
HDFS的NN服务通过接收DN的Heartbeat消息获取DN的运行状态。Heartbeat是一则很简短的RPC消息,由DN向NN主动发出,包含该DN的容量、传输请求数、磁盘卷状态等信息,默认发送间隔3秒。
DN发送的Heartbeat消息会被更新在NN的heartbeats结构中;NN通过一个线程定期检查该结构(默认5分钟一次),找到心跳超时的节点(默认10分30秒超时,2*检查周期5分钟+10*心跳周期3秒),判断其死亡;在这种配置下,一个节点从无心跳到最终断定死亡,最长可能经过15.5分钟时间。
Hadoop学习笔记之五:HDFS功能逻辑(1)的更多相关文章
- Hadoop学习笔记: HDFS
注:该文内容部分来源于ChinaHadoop.cn上的hadoop视频教程. 一. HDFS概述 HDFS即Hadoop Distributed File System, 源于Google发表于200 ...
- Hadoop学习笔记(2)-HDFS的基本操作(Shell命令)
在这里我给大家继续分享一些关于HDFS分布式文件的经验哈,其中包括一些hdfs的基本的shell命令的操作,再加上hdfs java程序设计.在前面我已经写了关于如何去搭建hadoop这样一个大数据平 ...
- hadoop学习笔记贰 --HDFS及YARN的启动
1.初始化HDFS :hadoop namenode -format 看到如下字样,说明初始化成功. 启动HDFS,start-dfs.sh 终于启动成功了,原来是core-site.xml 中配置 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
随机推荐
- mysql之event
mysql之event http://blog.csdn.net/lxgwm2008/article/details/9088521 Mysql事件调度器(Event Scheduler)类似于定时器 ...
- 20170929 微信小程序项目开发
1. 微信小程序环境搭建 请参考官网,哈哈! 2. 微信小程序基础学习 文件结构: 3. 微信小程序实战 4. 目前的逻辑,是从微信小程序的界面和服务器的Web API 进行交互, 有个注意事项就是W ...
- 20170811 使用Bootstrap框架写个页面
采用Bootstrap-table 做的页面. 1. 增加Query 查询功能,涉及Ajax 来加载页面数据吧! <meta charset="UTF-8"> < ...
- UniConnectDialog使用
对话框中文显示 设计视图 设置参数 取值结果 获取根据参数设置的值关键代码 UniConnection1.ConnectDialog := UniConnectDialog1; UniConnecti ...
- pymysql下报错:numpy.float64 object has no attribute 'translate' 可能是pandas版本的问题
pymysql下报错:numpy.float64 object has no attribute 'translate'.定位到db.merge函数中,dataframe中浮点型元素的类型为numpy ...
- vue-devtools : vue的调试工具及log显示工具 vconsole
使用 devtools 有很多好处,比如它可以让你能够实时编辑数据属性并立即看到其反映出来的变化.另一个主要的好处是能够为 Vuex 提供时间旅行式的调试体验. 注意:请留意如果页面使用了一个生产环境 ...
- Go包管理工具Vendor使用
一.Go包管理工具Vendor 一.使用步骤 1.首先,从go get -u github.com/kardianos/govendor下载govendor工具到本地. 2.govendor使用时,必 ...
- FreeMaker常用表达式
1,日期转换 ${data.startDate?string("yyyy-MM-dd HH:mm")} 2,非空检查 当数据为null时,1中日期转换在界面上不会显示异常,但在日志 ...
- 软RAID管理命令mdadm详解
软RAID管理命令mdadm详解 mdadm是linux下用于创建和管理软件RAID的命令,是一个模式化命令.但由于现在服务器一般都带有RAID阵列卡,并且RAID阵列卡也很廉价,且由于软件RAID的 ...
- tcpdump 选项及过滤规则
tcpdump tcp -i eth1 -t -s 0 -c 100 and dst port ! 22 and src net 192.168.1.0/24 -w ./target.cap (1)t ...