Python爬虫与数据图表的实现
要求:
1. 参考教材实例20,编写Python爬虫程序,获取江西省所有高校的大学排名数据记录,并打印输出。
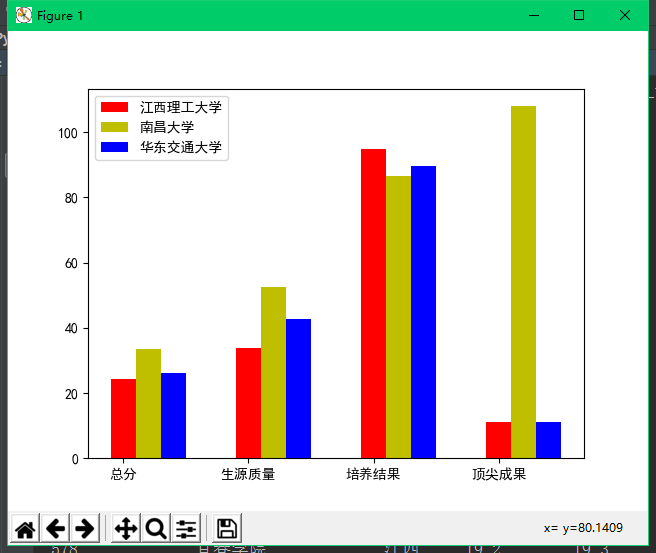
2. 使用numpy和matplotlib等库分析数据,并绘制南昌大学、华东交通大学、江西理工大学三个高校的总分排名、生源质量(新生高考成绩得分)、培养结果(毕业生就业率)、顶尖成果(高被引论文·篇)等四个指标构成的多指标柱形图。
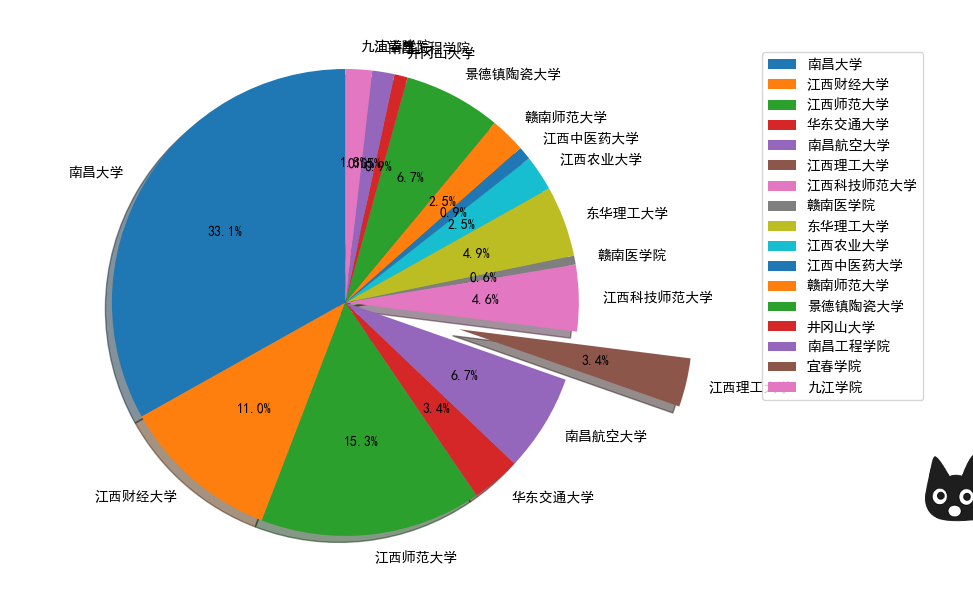
3. 对江西各高校的顶尖成果(高被引论文数量)进行分析,使用matplotlib绘制各高校顶尖成果数构成的饼状图,并突出江西理工大学所在的饼状块。
实例代码:
import requests
from bs4 import BeautifulSoup
import numpy as np
import matplotlib.pyplot as plt allUniv = []
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return "" def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
return len(allUniv) def printUnivList(num):
print("{0:^4}\t{1:^20}\t{2:^5}\t{3:^8}\t{4:^8}\t{5:^8}\t{6:^8}".format("排名", "学校名称", "省市", "总分", "生源质量", "培养结果", "顶尖成果"))
for i in range(num):
u = allUniv[i]
if u[2] == "江西":
print("{0:^4}\t{1:^20}\t{2:^5}\t{3:^8}\t{4:^8}\t{5:^8}\t{6:^8}".format(u[0], u[1], u[2], u[3], str(u[4]), str(u[5]), str(u[9]))) def drawBarChart(num):
jxlg = []
ncdx = []
hdjd = []
for i in range(num):
u = allUniv[i]
if u[1] == "江西理工大学":
jxlg.append(float(u[3]))
jxlg.append(float(u[4]))
jxlg.append(float(str(u[5]).replace('%', '')))
jxlg.append(float(u[9]))
if u[1] == "南昌大学":
ncdx.append(float(u[3]))
ncdx.append(float(u[4]))
ncdx.append(float(str(u[5]).replace('%', '')))
ncdx.append(float(u[9]))
if u[1] == "华东交通大学":
hdjd.append(float(u[3]))
hdjd.append(float(u[4]))
hdjd.append(float(str(u[5]).replace('%', '')))
hdjd.append(float(u[9]))
name_list = ['总分', '生源质量', '培养结果', "顶尖成果"]
x = list(range(len(name_list)))
total_width, n = 0.8, 4
width = total_width / n
fig, ax = plt.subplots()
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.bar(x, jxlg, width=width, label='江西理工大学', tick_label=name_list, fc='r')
for i in range(len(x)):
x[i] = x[i] + width
plt.bar(x, ncdx, width=width, label='南昌大学', fc='y')
for i in range(len(x)):
x[i] = x[i] + width
plt.bar(x, hdjd, width=width, label='华东交通大学', fc='b')
# plt.xticks(np.arange(len(name_list)))
plt.legend()
plt.show() def drawBar(num):
djcg = []
name = []
explode = []
for i in range(num):
u = allUniv[i]
if u[2] == "江西":
djcg.append(u[9])
name.append(u[1])
if u[1] == "江西理工大学":
explode.append(0.5)
else:
explode.append(0)
plt.rcParams['font.sans-serif'] = 'SimHei'
fig1, ax1 = plt.subplots()
ax1.pie(djcg, explode=explode, labels=name, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal')
plt.legend()
plt.show() def main():
url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html"
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
num = fillUnivList(soup)
printUnivList(num)
drawBarChart(num)
drawBar(num) if __name__ == '__main__':
main()
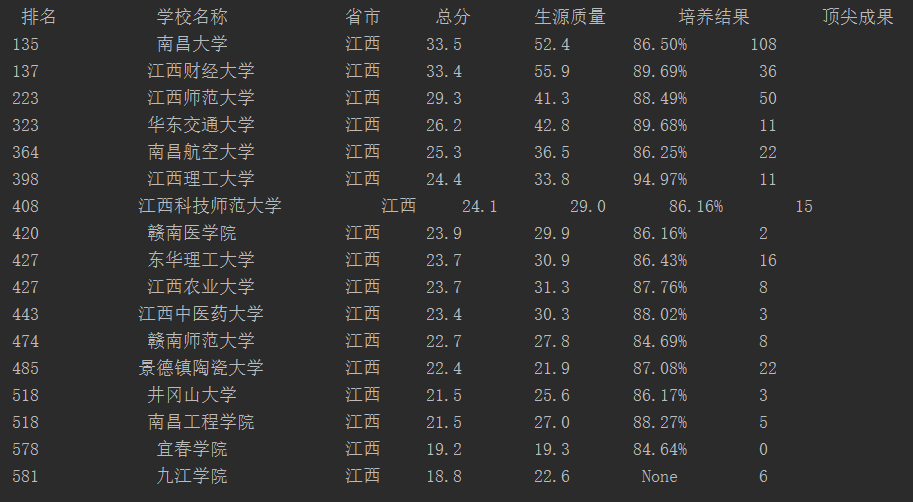
江西省高校排名结果如下:
三校部分数据对比如下:
江西各高校的顶尖成果(高被引论文数量)对比分析如下:
Python爬虫与数据图表的实现的更多相关文章
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 从python爬虫以及数据可视化的角度来为大家呈现“227事件”后,肖战粉丝的数据图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
- python 爬虫与数据可视化--matplotlib模块应用
一.数据分析的目的(利用大数据量数据分析,帮助人们做出战略决策) 二.什么是matplotlib? matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB ...
- python 爬虫与数据可视化--数据提取与存储
一.爬虫的定义.爬虫的分类(通用爬虫.聚焦爬虫).爬虫应用场景.爬虫工作原理(最后会发一个完整爬虫代码) 二.http.https的介绍.url的形式.请求方法.响应状态码 url的形式: 请求头: ...
- Python 爬虫-股票数据的Scrapy爬虫
2017-08-06 19:52:21 目标:获取上交所和深交所所有股票的名称和交易信息输出:保存到文件中 技术路线:scrapy 获取股票列表:东方财富网:http://quote.eastmone ...
- python爬虫之数据的三种解析方式
一.正则解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- Python爬虫音频数据
一:前言 本次爬取的是喜马拉雅的热门栏目下全部电台的每个频道的信息和频道中的每个音频数据的各种信息,然后把爬取的数据保存到mongodb以备后续使用.这次数据量在70万左右.音频数据包括音频下载地址, ...
随机推荐
- shell编程awk进阶
awk操作符 算术操作符: x+y, x-y, x*y, x/y, x^y, x%y -x: 转换为负数 +x: 转换为数值 字符串操作符:没有符号的操作符,字符串连接 赋值操作 ...
- VS2008生成数据库连接字串
在写WEB程序的时候~通常需要在Web.config文件的<connectionStrings>节点上写数据库的链接字符串,因为是一串字符代码我们常常需要写在固定的文本里便于下次使用,其实 ...
- Python中常用的模块
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- 将常用的T-CODE收藏进 文件夹
1:选中文件夹,右键>insert transaction>输入相应的t-code.
- 常用笔记:Linux
Linux打包压缩排除指定文件夹: 使用Linux的tar 命令打包压缩文件夹,有时候需要排除里面的某几个文件夹,加上--exclude参数: tar -zcvf blog.tar.gz --excl ...
- Git Your branch is ahead of 'origin/master' by X commits解决方法
(1)方法1:git fetch origin (2)方法2(代码还需要):git push origin (3)方法3 (代码不需要):git reset --hard origin/$branch ...
- AFNetworking 源码解析
3.0 之后,就取消了NSOperation的控制. 因为根据Apple Developer Document的文档 https://developer.apple.com/documentation ...
- 适用于 Windows 7 SP1、Windows Server 2008 R2 SP1 和 Windows Server 2008 SP2 的 .NET Framework 4.5.2 仅安全更新说明:2017 年 9 月 12 日
https://support.microsoft.com/zh-cn/help/4040960/description-of-the-security-only-update-for-the-net ...
- Linux配置eclipse实践
有几年没有在Linux下用eclipse开发了,几年前是在CentOS 7下用eclipse开发的,好像用的还是较新的版本.最近有个项目要求在centos 下卡发,装上eclipse-cdt后,建立项 ...
- 答案在哪里?action config/Interceptor/class/servlet
项目已提测,这两天我们都集中精力梳理外包团队给我司研发的这个三方支付系统的代码逻辑.今天下午爱琴海会议室,开发组里一同学分享他对支付结果回调的梳理成果. 支付结果回调的整体时序是:支付渠道方处理完用户 ...