HTTP/HTTPS原理详解
简介
HTTP(Hypertext Transfer Protocal,超文本传输协议)是WWW(World Wide Web,万维网)数据传输的基础,规定如何传输超文本。HTTP协议存在多个版本:HTTP/0.9、HTTP/1.0、HTTP/1.1和HTTP/2。
HTTP基于Client/Server架构,遵循request->response模型,客户端(比如浏览器、curl命令行)向服务端发送一个HTTP request请求,服务端处理后回复客户端一个HTTP response响应。
HTTP是应用层协议,一般依赖一个可靠的传输层协议(如TCP),也可以基于不可靠的传输层协议(比如HTTPU协议基于UDP协议)。
HTTP资源由URLs(Uniform Resource Locator,统一资源定位符)确定,使用URI(Uniform Resource Identifier)中的http、https的scheme。
HTTP session(会话):客户端与服务器之间的一系列请求/响应称为会话,会话能够把同一用户发出的不同请求关联起来。不同用户的会话应当是相互独立的。会话一旦建立就应当一直存在,直到用户空闲时间超过了某一个时间界限,才释放该会话资源。
HTTP请求方法
HTTP不同的版本定义了不同的方法,0.9版本定义了GET方法,1.0版本定义了GET、POST和HEAD方法,1.1版本定义了OPTIONS、PUT、DELETE、TRACE和CONNECT方法,RFC-5789规定了PATCH方法。
- GET:用于客户端从服务器获取数据,且不应该改变服务器的状态。
- HEAD:类似与GET方法,不同之处在与客户端仅关心响应的头部的元信息,服务器不会返回response body,这样可以提高传输效率。
- POST:客户端要求更新服务器上某个URI对应的资源。
- PUT:类似POST请求,如果URI对应的是一个已经存在的资源,该资源会被更新;如果资源不存在,则创建新的资源。另外,PUT操作是幂等的,POST操作不是幂等的。
- DELETE:删除指定的资源。
- TRACE:这个方法可以打印出服务端的接受内容,这样客户端可以判断出发送出去的数据是否被中间服务器篡改过。
- OPTIONS:查询某个URL支持的HTTP方法。
- PATCH:对服务器的指定资源做部分修改。
方法的安全性
按照标准,HEAD、GET、OPTIONS和TRACE方法仅用于查询信息,应该是安全的,不会修改服务器的状态。
POST、PUT、DELETE和PATCH方法是不安全的,他们的目的是修改服务器上的资源,一般网络爬虫不会使用这些方法访问服务器。
当然,标准只是建议,方法对应的操作完全由服务端的开发者决定,在收到GET请求时改变服务器的状态也是可以的,但是这种不标准的行为会带来大量问题(比如网络爬虫频繁访问服务器时,可能会将系统状态修改到不可知的状态)。
幂等操作与非幂等操作
GET、HEAD、OPTIONS、TRACE、PUT、DELETE操作是幂等的,即一次操作和多次操作的效果相同。
POST方法不需要是幂等的,对一个发布博客的URL进行两次一样的POST请求,会产生两个不同的博客。
一张图总结
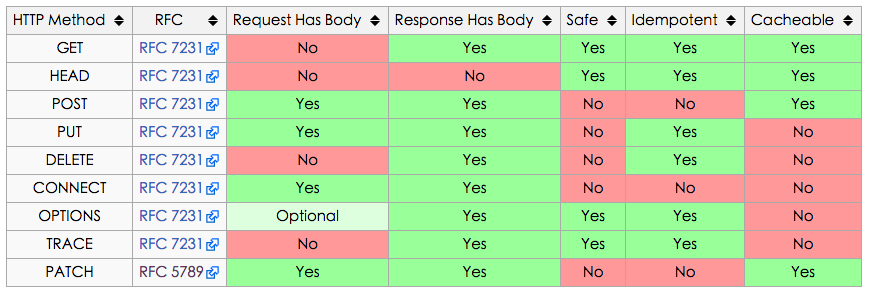
注:图片来自维基百科。
安全性
TRACE这个方法(在微软的IIS中叫做TRACK)可以被用在cross site tracing攻击中,所以一般服务器默认关闭了这个方法,包括TRACK。
上面提到的安全,都是从服务器的状态是否被改变的角度来说。从被传输的数据是否安全来看,HTTP协议是一个不安全的协议,它的报文是明文传输的。HTTPS是一个比HTTP协议安全的超文本传输协议,早期基于SSL协议,后来演进到TLS协议,涉及到敏感数据传输时应该采用HTTPS协议。
HTTPS
HTTPS的作用主要有三个:
- 验证服务器或客户端的身份合法
- 报文加密
- 验证数据完整性
采用HTTPS可以有效抵御中间人攻击、报文监听攻击和报文篡改攻击。不过,针对报文监听这种攻击的抵御不是绝对的,HTTPS是基于TLS的HTTP,可以将HTTP请求的URL path、request header、request body等内容加密,由于转发需要提供IP及端口信息,所以监听者还是能够监听到目的IP(甚至域名)、目的端口、源IP、源端口、报文大小、通信时间等信息的。
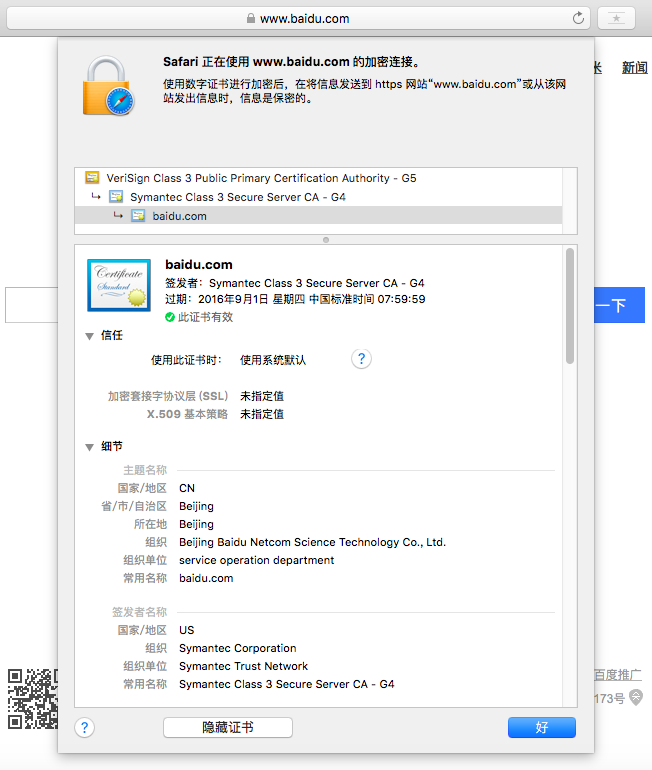
使用浏览器访问采用HTTPS协议的网站时,一般在地址栏左侧都有标示表明HTTPS证书信息,比如使用Safari访问百度时,可以看到百度使用了赛门铁克颁发的证书:
持久链接
在HTTP/0.9和HTTP/1.0中,链接在一次请求、响应后被关闭,这种特性称为无连接,考虑到网络状况越来越复杂(比如一个网页需要请求多次加载图片、视频、CSS等),在HTTP/1.1中引入了长链接(keep alive)的概念,同一个会话的不同HTTP请求可以共用一个TCP链接,不再需要每次HTTP请求之前都走一遍TCP的三次握手过程,有效的提高了传输效率。
请求报文
HTTP请求报文的格式如下: request line
request header fields
<blank line>
request body [optional]
request line和header fields每一行都要以<CR><LF>(carriage return——回车和line feed——换行)结束,并且blank line只允许有<CR><LF>不允许有其他空白字符。在HTTP1.1以前,header fields可以为空,HTTP1.1中,header field必须包含Host字段。
响应报文
HTTP响应报文格式如下: status line
response header fields
<blank line>
response body [optional]
status line和header fields及blank line的格式要求如请求报文的格式。
响应状态码包含在第一行,比如HTTP/1.0 200 OK,第一个字段是HTTP版本,然后是状态码及错误解释信息。错误解释信息是可以定制的,甚至状态码也可以自定义。客户端收到响应后,先依据status line判断响应状态,其次是response header,在判断status line时,如果不是一个标准状态码,会按照首位数字判断响应类别:
1字头:消息
2字头:成功
3字头:重定向
4字头:请求错误
5、6字头:服务器错误
HTTP会话状态
HTTP是一个无状态协议,在同一个会话的不同请求之间,服务端无需记录每个用户的不同请求之间的信息。为了维持请求之间的状态,可以采用cookie或session的技术,注意这里的session和HTTP会话中的session含义不同。
cookie
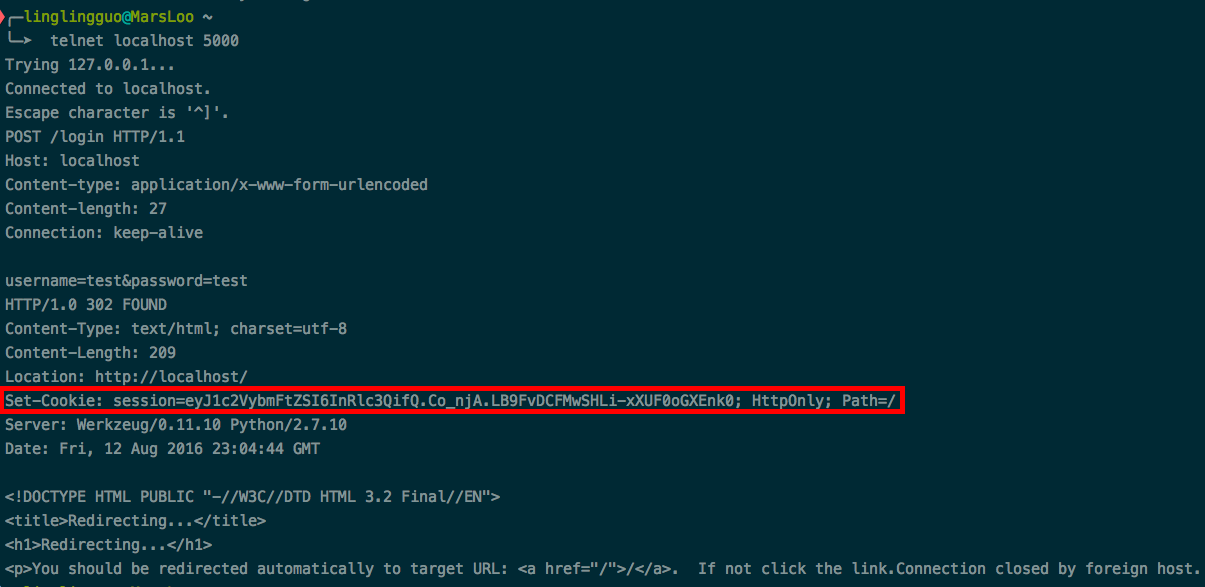
采用cookie的时候,服务器会将cookie的内容放在response headers field的set-cookie字段中,浏览器会将cookie的内容存下来,下次请求服务器时在request header fields的cookie字段中写入cookie的内容: 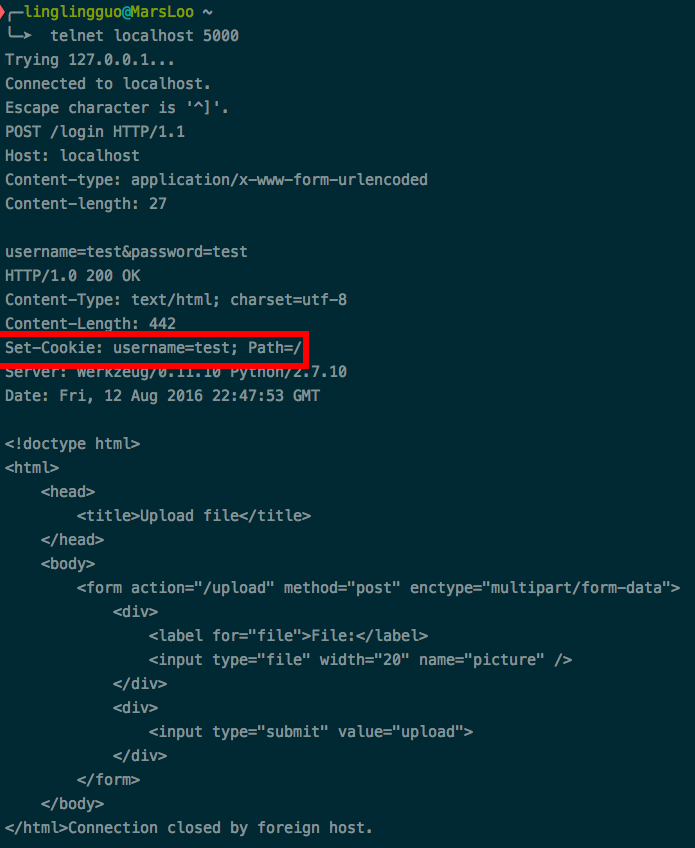
下一次调用upload接口上传文件的时候,客户端浏览器会自动填入cookie字段:
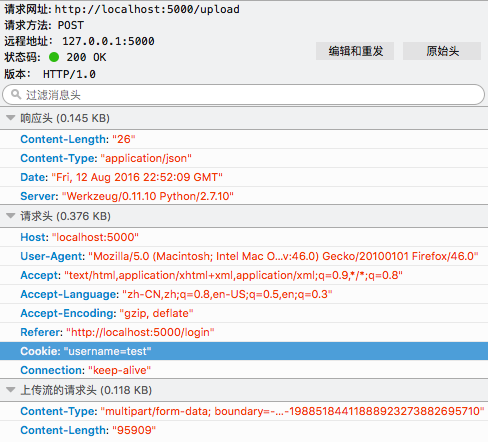
session
因为HTTP是明文传输的,所以敏感信息不方便放在客户端cookie中,而且cookie过大时,可能由于浏览器的限制导致请求无法发送,这个时候可以采用session。客户端第一次访问服务端时,服务端会为这次会话生成一个唯一的session id,然后会以该session id建立一个存储空间(内存、数据库、文件等等),向该session中记录信息,响应时只在set-cookie字段中填入session id,这样即使客户端看到了session id也无法读取里面的内容。
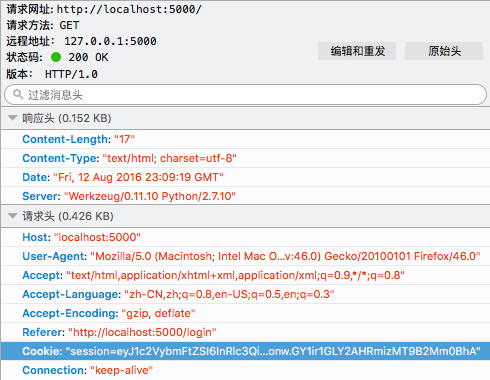
同理,客户端下一次请求时,会在request header fields中的cookie字段中填入session id的信息:
题外话
之前工作让我养成了一个习惯,学习协议的时候会看RFC,做抓包实验。如果要深入理解HTTP协议 ,建议通读相关RFC。报文抓取和分析的话,Linux下可以使用tcpdump,Window、OsX环境可以用wireshark。服务器方面我是用Flask搭了一个简单地服务端,客户端请求采用curl命令行或者浏览器,如果您会使用Fiddler的话,分析报文会更方便。
HTTP/HTTPS原理详解的更多相关文章
- [转帖]HTTPS系列干货(一):HTTPS 原理详解
HTTPS系列干货(一):HTTPS 原理详解 https://tech.upyun.com/article/192/HTTPS%E7%B3%BB%E5%88%97%E5%B9%B2%E8%B4%A7 ...
- 【转】HTTPS系列干货(一):HTTPS 原理详解
HTTPS系列干货(一):HTTPS 原理详解 前言 HTTPS(全称:HyperText Transfer Protocol over Secure Socket Layer),其实 HTTPS 并 ...
- HTTPS系列干货(一):HTTPS 原理详解
HTTPS(全称:HyperText Transfer Protocol over Secure Socket Layer),其实 HTTPS 并不是一个新鲜协议,Google 很早就开始启用了,初衷 ...
- 加密方法与HTTPS 原理详解
一:加密方法: 1,对称加密 AES,3DES,DES等,适合做大量数据或数据文件的加解密. 2,非对称加密 如RSA,Rabin.公钥加密,私钥解密.对大数据量进行加解密时性能较低. 二:https ...
- HTTPS 原理详解 (转)
HTTPS(全称:HyperText Transfer Protocol over Secure Socket Layer),其实 HTTPS 并不是一个新鲜协议,Google 很早就开始启用了,初衷 ...
- HTTPS原理详解
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版.即HTT ...
- SSL/TLS 原理详解
本文大部分整理自网络,相关文章请见文后参考. SSL/TLS作为一种互联网安全加密技术,原理较为复杂,枯燥而无味,我也是试图理解之后重新整理,尽量做到层次清晰.正文开始. 1. SSL/TLS概览 1 ...
- WebActivator的实现原理详解
WebActivator的实现原理详解 文章内容 上篇文章,我们分析如何动态注册HttpModule的实现,本篇我们来分析一下通过上篇代码原理实现的WebActivator类库,WebActivato ...
- Spring Aop底层原理详解
Spring Aop底层原理详解(来源于csdn:https://blog.csdn.net/baomw)
随机推荐
- var与this定义变量的区别以及疑惑
我们知道: var可以定义一个局部变量,当然如果var定义在最外层的话,就是全局的局部变量,也就算是全局变量了. 而this关键字定义的变量准确的说应该算是成员变量.即定义的是调用对象的成员变量. 另 ...
- Search In Rotated SortedArray2, 有重复数据的反转序列。例如13111.
问题描述:反转序列,但是有重复的元素,例如序列13111. 算法思路:如果元素有重复,那么left-mid,就不一定是有序的了,所以不能利用二分搜索,二分搜索必须是局部有序.针对有序序列的反转,如果有 ...
- oracle 子查询详解 in和exists的区别
sql允许多层嵌套,子查询是嵌套在其他查询中的查询.我们可以把子查询当做一张表来看到,即外层语句可以把内嵌的查询结果当做一张表使用. 子查询查询结果有三种情况 不返回查询记录.若子查询不返回记录则主查 ...
- 完全卸载gitlab
完全卸载删除gitlab 2017年5月29日 wuhao 暂无评论 4,089次浏览 完全卸载删除gitlab 1.停止gitlab 1 gitlab-ctl stop 2.卸载gitlab ...
- JavaScript中的两个“0” -0和+0
JavaScript中的两个“0”(翻译) 本文翻译自JavaScript’s two zeros JavaScript has two zeros: −0 and +0. This post e ...
- elementUI表格合并单元格
相信你肯定看了 ElementUI 官方文档了,没看的话先去看下表格各个属性的意义,方便下文阅读:传送门 但你会发现此例过于简单,死数据,但我们开发的时候往往都是后台传递过来的数据,导致我们 rows ...
- Angular路由的定义和使用
一.什么是routing(路由) Almost all non-trivial, non-demo Single Page App (SPA) require multiple pages. A se ...
- EL标签
1.EL的作用 jsp的核心语法: jsp表达式 <%=%>和 jsp脚本<% %>. 开发jsp的原则: 尽量在jsp页面中少写甚至不写java代码. 使用EL表达式替换掉 ...
- Python编码错误的解决办法SyntaxError: Non-ASCII character '\xe5' in file
[现象] 在编写Python时,当使用中文输出或注释时运行脚本,会提示错误信息: SyntaxError: Non-ASCII character '\xe5' in file ******* [原因 ...
- PostgreSQL日志配置记录
日志审计 审计是值记录用户的登陆退出以及登陆后在数据库里的行为操作,可以根据安全等级不一样设置不一样级别的审计, 此处涉及的参数文件有: logging_collector --是否开启日 ...