转:Lucene之计算相似度模型VSM(Vector Space Model) : tf-idf与交叉熵关系,cos余弦相似度
原文:http://blog.csdn.net/zhangbinfly/article/details/7734118
最近想学习下Lucene ,以前运行的Demo就感觉很神奇,什么原理呢,尤其是查找相似度最高的、最优的结果。索性就直接跳到这个问题看,很多资料都提到了VSM(Vector Space Model)即向量空间模型,根据这个模型可以对搜索的结果进行最优化的筛选,目前还不知道如何证明,只能凭借想象应该是这个样子的。
1、看一下TF/IDF
我们先来看下一个叫TF/IDF的概念,一般它用来作为一个搜索关键字在文档或整个查询词组的权重的计算方式。前几天看了吴军老师的数学之美系列文章,这个TF/IDF可以追溯到信息论中的相对熵的概念。在有些文献中它被称为成“交叉熵”。在英语中是 Kullback-Leibler Divergence,是以它的两个提出者库尔贝克和莱伯勒的名字命名的。相对熵用来衡量两个正函数是否相似,对于两个完全相同的函数,它们的相对熵等于零。在自然语言处理中可以用相对熵来衡量两个常用词(在语法上和语义上)是否同义,或者两篇文章的内容是否相近等等。利用相对熵,我们可以到处信息检索中最重要的一个概念:词频率-逆向文档频率(TF/IDF)。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
• Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
• Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
容易理解吗?词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本
文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,
就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明
此词(Term)太普通,不足以区分这些文档,因而重要性越低。
道理明白了,我们来看看公式:
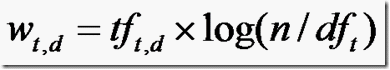
W(t,d):the weight of term t in document d
tf(t,d):frequency of term t in document d
n :total number of documents
df(t):the number of documents that contain term t
一些简单的模型(Term Count Model)忽略了文档的总数这个变量,那样权重的计算就是 (In a simpler Term Count Model the term specific weights do not include the global parameter. Instead the weights are just the counts of term occurrences: .)
(In a simpler Term Count Model the term specific weights do not include the global parameter. Instead the weights are just the counts of term occurrences: .)
2、进入VSM
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在
文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
我们只要比较下图中的α,θ的余弦值的大小,余弦值越大,相似度越高。公式如下:

下面列出计算方法:
设d1=(x1,y1),q=(x2,y2)
我们根据余弦定理,cos(α)=cos(A-B)
=cos(A)cos(B)+sin(A)sin(B)
=(x1/sqr(x1*x1+y1*y1))(x2/sqr(x1*x1+y1*y1))+(y1/sqr(x1*x1+y1*y1))(y2/sqr(x1*x1+y1*y1))
合并同类项,即向量d1与向量q的内积/向量模,也即上面的公式sim(dj,q)。
举个例子,查询语句有11个Term,共有三篇文档搜索出来。其中各自的权重(Term weight),如下表格。
t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11
D1 0 0 0.477 0 0.477 0.176 0 0 0 0.176 0
D2 0 0.176 0 0.477 0 0 0 0 0.954 0 0.176
D3 0 0.176 0 0 0 0.176 0 0 0 0.176 0.176
Q 0 0 0 0 0 0.176 0 0 0.477 0 0.176
于是计算,三篇文档同查询语句的相关性打分分别为: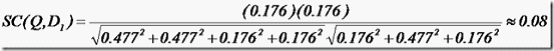
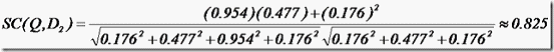
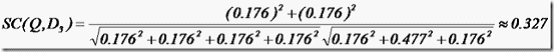
于是文档二相关性最高,先返回,其次是文档一,最后是文档三。
参考:
1)tf/idf:http://en.wikipedia.org/wiki/Tf-idf
2)vsm:http://en.wikipedia.org/wiki/Vector_space_model wikipedia维基百科
3)如何确定查询相关性:http://www.google.com.hk/ggblog/googlechinablog/2006/06/blog-post_3066.html
4)网络资料:http://forfuture1978.javaeye.com
转:Lucene之计算相似度模型VSM(Vector Space Model) : tf-idf与交叉熵关系,cos余弦相似度的更多相关文章
- 向量空间模型(Vector Space Model)
搜索结果排序是搜索引擎最核心的构成部分,很大程度上决定了搜索引擎的质量好坏.虽然搜索引擎在实际结果排序时考虑了上百个相关因子,但最重要的因素还是用户查询与网页内容的相关性.(ps:百度最臭名朝著的“竞 ...
- Solr相似度名词:VSM(Vector Space Model)向量空间模型
最近想学习下Lucene ,以前运行的Demo就感觉很神奇,什么原理呢,尤其是查找相似度最高的.最优的结果.索性就直接跳到这个问题看,很多资料都提到了VSM(Vector Space Model)即向 ...
- [IR课程笔记]向量空间模型(Vector Space Model)
VSM思想 把文档表示成R|v|上的向量,从而可以计算文档与文档之间的相似度(根据欧氏距离或者余弦夹角) 那么,如何将文档将文档表示为向量呢? 首先,需要选取基向量/dimensions,基向量须是线 ...
- 扩展:向量空间模型算法(Vector Space Model)
- 12.扩展:向量空间模型算法(Vector Space Model)
- 向量空间模型(Vector Space Model)的理解
1. 问题描述 给你若干篇文档,找出这些文档中最相似的两篇文档? 相似性,可以用距离来衡量.而在数学上,可使用余弦来计算两个向量的距离. \[cos(\vec a, \vec b)=\frac {\v ...
- 向量空间模型实现文档查询(Vector Space Model to realize document query)
xml中文档(query)的结构: <topic> <number>CIRB010TopicZH006</number> <title>科索沃難民潮&l ...
- Python简单实现基于VSM的余弦相似度计算
在知识图谱构建阶段的实体对齐和属性值决策.判断一篇文章是否是你喜欢的文章.比较两篇文章的相似性等实例中,都涉及到了向量空间模型(Vector Space Model,简称VSM)和余弦相似度计算相关知 ...
- 向量空间模型(VSM)在文档相似度计算上的简单介绍
C#实现在: http://blog.csdn.net/Felomeng/archive/2009/03/25/4023990.aspx 向量空间模型(VSM:Vector space model)是 ...
随机推荐
- Android Parcelable 源码解析
大家都知道,要想在Intent里面传递一些非基本类型的数据,有两种方式,一种实现Parcelable,另一种是实现Serializable接口. 今天先不说Serializable 接口,只说Parc ...
- 使用keytool工具产生带根CA和二级CA的用户证书
使用keytool工具产生带根CA和二级CA的用户证书 1 生成根CA 1.1 生成根CA证书 根CA实际是一张自签CA,自签CA的使用者和颁发者都是它自己.使用下面的命令生成根证书,如果没有指定 ...
- 编译Chromium出现warning C4819的解决办法
编译Chromium时出现 warning C4819: The file contains a character that cannot be represented in the current ...
- 提权基础-----mysql-udf提权
1.总结关于udf提权方法 通过弱口令,爆破,网站配置文件等方式得到mysql数据库帐号密码,---还要能外连 (1).将udf.dll代码的16进制数声明给my_udf_a变量 set @my_ud ...
- 第四十篇 Python之设计模式总结-简单工厂、工厂方法、抽象工厂、单例模式
一. 简单工厂 简单工厂模式(Simple Factory Pattern):是通过专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类. 简单工厂的用处不大,主要就是一个if... ...
- springboot在application.yml中使用了context-path属性导致静态资源法加载,如不能引入vue.js,jquery.js,css等等
在springBoot配置中加入上下文路径 server.context-path=/csdn js,img等静态文件无法加载,出现404的问题 <script type="text/ ...
- 看图写树 (Undraw the Trees UVA - 10562)
题目描述: 原题:https://vjudge.net/problem/UVA-10562 题目思路: 递归找结点 //自己的代码测试过了,一直WA,贴上紫书的代码 AC代码 #include< ...
- 深入理解 Vuejs 组件
本文主要归纳在 Vuejs 学习过程中对于 Vuejs 组件的各个相关要点.由于本人水平有限,如文中出现错误请多多包涵并指正,感谢.如果需要看更清晰的代码高亮,请跳转至我的个人站点的 深入理解 Vue ...
- some Commands OF CONSOLE
不可避免地使用console,一旦与电脑打交道:入口就是help,而很多行就直接过掉了,却不能看到需要的地方,在那里停下来,实际是需要使用more less grep等 在windows中,使用di ...
- django 连接mysql报错
原因: 问题1. 即从mysql5.7版本之后,默认采用了caching_sha2_password验证方式. 问题2. 然后在执行 python manage.py makemigrations依 ...