推荐算法之因子分解机(FM)
在这篇文章我们将介绍因式分解机模型(FM),为行文方便后文均以FM表示。FM模型结合了支持向量机与因子分解模型的优点,并且能够用了回归、二分类以及排序任务,速度快,是推荐算法中召回与排序的利器。FM算法和前面我们介绍的LFM模型模型都是基于矩阵分解的推荐算法,但在大型稀疏性数据中FM模型效果也不错。本文首先将阐述FM模型原理,然后针对MovieLens数据集将FM算法用于推荐系统中的ranking阶段,给出示例代码。最后,我们将对该算法进行一个总结。
1. FM算法
FM是一个如SVM一样通用的预测器,并且能够在数据非常稀疏的情况下估算训练出可靠的参数。同时,FM不仅能够利用一阶特征,通过分解参数也能够利用二阶乃至更高阶特征,并且速度相对其它算法更快更可靠。在本章我将介绍FM原理并详细讨论模型方程,然后简短说明如何将之用于多个预测任务。
1.1 FM模型
当d=2,即我们最高阶只关注到二阶交互特征时,FM的模型方程式定义如下:
\]
在这里,模型参数的估计空间为:
\]
并且,<·,·>表示两个大小为k的向量的点积:
\]
在V中\(v_i\)描述了第i个特征,\(k\in N_0^+\)是一个定义模型分解维度的超参数。
2-way FM(degree=2)模型能够捕获所有的一阶特征与二阶交互特征:
- \(w_0\)是一个全局偏置向量
- \(w_i\)对第i个变量(特征)进行建模
- \(w_{ij}\)对第i个变量(特征)与第j个变量(特征)之间的交互作用进行了建模。在这里,FM并非定义出\(w_{ij} \in R\) ,而是通过分解参数W对交互建模。这也是FM在稀疏情况下能进行高质量参数估计的关键点。
看到这里可能会有一个疑问,FM是如何通过分解参数对交互建模的呢?
众所周知,在当\(k\)足够大的时候,任何一个正定矩阵\(W\)都能存在一个向量\(V\)使得\(W=VV^t\)。这表明,如果选择的\(k\)足够大则FM可以表示任何交互矩阵。然而,在数据十分稀疏的情况下,\(k\)只需要取一个较小的值就行,这是因为没有足够的数据来估计复杂的交互矩阵\(W\),并且限制\(k\)的大小反而还能提高模型的泛化性能。
1.2 稀疏数据下的参数估计
在数据十分稀疏的情况下,通常没有充足的数据直接估计变量之间的交互参数\(w_{ij}\)。FM模型在这种场景下能够直接估计变量之间的交互是因为其通过分解交互参数来破坏参数\(w_{ij}\)的独立性,从而间接的达到训练参数的目的。这意味着一个交互数据也有助于估计相关交互的参数。为了让读者理解清晰,我们将通过一个栗子来阐述:
假设我们拥有电影评分系统的评分数据。系统记录了某个时间\(t \in R\)某个用户\(u \in U\)为电影\(i \in I\)评分 \(r\in {1, 2, 3, 4, 5}\).
U = {A, B, C}
I = {TI, NH, SW, ST}
观察到数据形式为:
S = {(A, TI, 2010-1, 5), (A, NH, 2010-2, 3), (A, SW, 2010-4, 1), (B, SW, 2009-5, 4), (B, ST,2009-8,5), (C, TI, 2009-9, 1), (C, SW, 2009-12,5)}
在这里,假设我们要估计A和ST组合下的评分y,显然训练数据中不存在变量\(x_A\)和变量\(x_{ST}\)都不为零的数据\(x\),因此直接估计交互参数\(w_{A,ST}\)没有任何作用(\(w_{A,ST}=0\))。但是通过分解交互参数\(w_{A,ST}\)为\(<v_{A},v_{ST}>\)我们就可以估计出该交互参数值。这是因为用户A对别的电影的评分能够帮助估计到参数\(V_A\),而别的用户对ST的评分也能帮助估计参数\(V_{ST}\)。
1.3 公式演算
如方程(1)所示,其时间复杂度为\(O(kn^2)\),但通过重新演算可将其时间复杂度降低到线性。如下所示:
\]
该等式的时间复杂度与k,n线性相关,为\(O(kn)\)
2. FM用于ranking
在本节,我将针对MovieLens数据集(ml-100k)走完推荐系统的数据预处理、召回、排序阶段并作介绍。其中FM用于ranking阶段。
2.1 数据预处理及召回策略
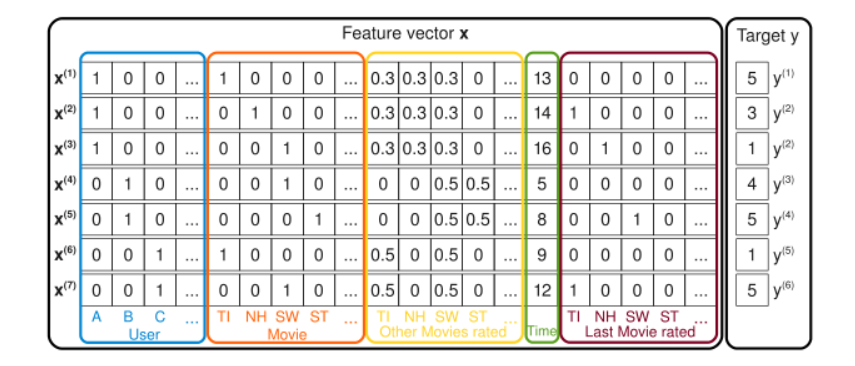
如图所示,将用户与电影使用one-hot编码,同时提取历史评分矩阵,用户职业进行one-hot编码,性别也是。召回阶段,简单粗暴的基于规则进行匹配item,具体详见github。
2.2 ranking阶段
实现FM模型,通过FM模型训练参数得到召回数据中用户对召回物品的评分并进行排序。算法实现代码如下。
# 定义FM模型
class FM_model(torch.nn.Module):
"""FM Model"""
def __init__(self, n, k):
super(FM_model, self).__init__()
self.n = n
self.k = k
self.linear = torch.nn.Linear(self.n, 1, bias=True)
self.v = torch.nn.Parameter(torch.rand(self.n, self.k))
def fm_layer(self, x):
# w_i * x_i 线性部分
linear_part = self.linear(x)
print(linear_part.shape)
# pairwise interactions part 1
inter_part1 = torch.mm(x, self.v)
# pairwise interactions part 2
inter_part2 = torch.mm(torch.pow(x, 2), torch.pow(self.v, 2))
inter_part = 0.5 * torch.sum(torch.sub(torch.pow(inter_part1, 2), inter_part2), dim=1).reshape(-1, 1)
output = linear_part + inter_part
return output
def forward(self, x):
output = self.fm_layer(x)
return output
详细代码,请前往github查看FM算法实现
3.小结
在本文中,我们介绍了FM模型。FM将SVM的通用性和因式分解模型的优势结合在一起。与SVM相比,FM能够在数据极其稀疏的情况下估计模型参数,并且时间复杂度与分解维数k和特征量n线性相关,速度较快,是推荐系统中召回与排序的利器。为了方便大家学习,作者特意针对MovieLens数据集走了一遍预处理、召回、排序的流程,希望能够帮助大家理解该算法,如果还有不明白的建议直接阅读论文,论文地址:因子分解机,召回和排序的利器,速度快效果好Factorization Machines
推荐算法之因子分解机(FM)的更多相关文章
- CTR@因子分解机(FM)
1. FM算法 FM(Factor Machine,因子分解机)算法是一种基于矩阵分解的机器学习算法,为了解决大规模稀疏数据中的特征组合问题.FM算法是推荐领域被验证效果较好的推荐算法之一,在电商.广 ...
- 因子分解机 FM
特征组合 人工方式的特征工程,通常有两个问题: 特征爆炸 大量重要的特征组合都隐藏在数据中,无法被专家识别和设计 针对上述两个问题,广度模型和深度模型提供了不同的解决思路. 广度模型包括FM/FFM等 ...
- 吃透论文——推荐算法不可不看的DeepFM模型
大家好,我们今天继续来剖析一些推荐广告领域的论文. 今天选择的这篇叫做DeepFM: A Factorization-Machine based Neural Network for CTR Pred ...
- 推荐算法之用矩阵分解做协调过滤——LFM模型
隐语义模型(Latent factor model,以下简称LFM),是推荐系统领域上广泛使用的算法.它将矩阵分解应用于推荐算法推到了新的高度,在推荐算法历史上留下了光辉灿烂的一笔.本文将对 LFM ...
- 分解机(Factorization Machines)推荐算法原理
对于分解机(Factorization Machines,FM)推荐算法原理,本来想自己单独写一篇的.但是看到peghoty写的FM不光简单易懂,而且排版也非常好,因此转载过来,自己就不再单独写FM了 ...
- 推荐算法之---FM算法;
一,FM算法: 1,逻辑回归上面进行了交叉特征.算法复杂度优化从O(n^3)->O(k*n^2)->O(k*n). 2,本质:每个特征都有一个k维的向量,代表的是每个特征都有k个不可告人的 ...
- 推荐算法之: DeepFM及使用DeepCTR测试
算法介绍 左边deep network,右边FM,所以叫deepFM 包含两个部分: Part1: FM(Factorization machines),因子分解机部分 在传统的一阶线性回归之上,加了 ...
- Mahout推荐算法API详解
转载自:http://blog.fens.me/mahout-recommendation-api/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 【笔记3】用pandas实现矩阵数据格式的推荐算法 (基于用户的协同)
原书作者使用字典dict实现推荐算法,并且惊叹于18行代码实现了向量的余弦夹角公式. 我用pandas实现相同的公式只要3行. 特别说明:本篇笔记是针对矩阵数据,下篇笔记是针对条目数据. ''' 基于 ...
随机推荐
- Python Django配置Mysql数据库
1 在项目中找到setting文件 打开 2 在里面找到 3 将Databases里面的数据改成 DATABASES = { 'default': { #引擎设置为Mysql 'ENGINE': 'd ...
- Linux删除文件 清除缓存
相信很多测试 经常会经历开发叫你清除缓存这种事. 那我们要怎么清呢? 一.首先,确认你要清除的缓存在哪个目录下,然后切换到该目录下,比如 我现在知道我的的缓存目录是在newerp这个目录下,则如图 二 ...
- crontab里的特殊符号%导致命令不能执行
有群里的小伙伴说crontab里的任务不执行,具体是这样的 * * * * /bin/date "+%Y-%m-%d %H:%M:%S" >>/data/tmp/tes ...
- Java入门 - 面向对象 - 04.抽象类
原文地址:http://www.work100.net/training/java-abstract.html 更多教程:光束云 - 免费课程 抽象类 序号 文内章节 视频 1 概述 2 Java抽象 ...
- Java单体应用 - 开发工具 - 02.Maven
原文地址:http://www.work100.net/training/monolithic-tools-maven.html 更多教程:光束云 - 免费课程 Maven 序号 文内章节 视频 1 ...
- 【新书推荐】《ASP.NET Core微服务实战:在云环境中开发、测试和部署跨平台服务》 带你走近微服务开发
<ASP.NET Core 微服务实战>译者序:https://blog.jijiechen.com/post/aspnetcore-microservices-preface-by-tr ...
- [LOJ#3022][网络流]「CQOI2017」老 C 的方块
题目传送门 定义有特殊边相邻的格子颜色为黑,否则为白 可以看出,题目给出的限制条件的本质是如果两个小方块所在的格子 \(x\) 和 \(y\) 为两个相邻的黑格,那么 \(x\) 和 \(y\) 之间 ...
- rabbitmq 实现延迟队列的两种方式
原文地址:https://blog.csdn.net/u014308482/article/details/53036770 ps: 文章里面延迟队列=延时队列 什么是延迟队列 延迟队列存储的对象肯定 ...
- 玩转Django2.0---Django笔记建站基础三(编写URL规则)
第三章 编写URL规则 URL(Uniform Resource Locator,统一资源定位符)是对可以从互联网上得到的资源位置和访问方法简洁的表示,是互联网上标准资源的地址. 在App里由于Dja ...
- 【Nginx入门系列】第二章 外部无法访问Nginx服务器
问题 Nginx服务器已经搭建成功,并且已经启动(如下图所示),并且可以ping通nginx服务器的ip地址,但是外部机子无法访问 Nginx服务器(没法显示欢迎页面) 解决方案 一般这种情况是出现在 ...