(数据科学学习手札61)xpath进阶用法
一、简介
xpath作为对网页、对xml文件进行定位的工具,速度快,语法简洁明了,在网络爬虫解析内容的过程中起到很大的作用,除了xpath的基础用法之外(可参考我之前写的(数据科学学习手札50)基于Python的网络数据采集-selenium篇),xpath中还存在着非常之多的进阶用法,本文将对笔者日常使用中积累的xpath进阶用法进行总结并举例说明:
二、xpath进阶用法
本文以http://quotes.toscrape.com/示例页面,首先抓取网页源码并利用etree解析:
import requests
from lxml import etree html = requests.get('http://quotes.toscrape.com/')
tree = etree.HTML(html.text)
2.1 获取某一节点的上一级节点
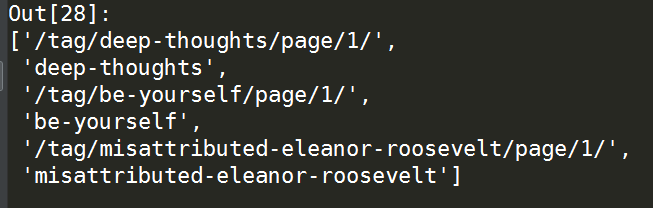
在xpath中/..表示向上一级,这里我们用xpath按照下图中的路径提取a标签里的内容:
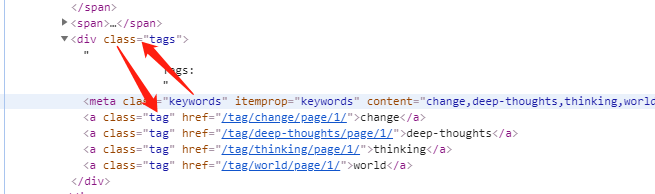
'''提取页面中符合下列位置规则的所有keyword'''
tree.xpath("//meta[@class='keywords']/../a[@class='tag']/text()")
或者利用parent来向上一级跳转,效果是一样的:
'''提取页面中符合下列位置规则的所有keyword'''
tree.xpath("//meta[@class='keywords']/parent::*/a[@class='tag']/text()")

2.2 定位指定属性以某个特定字符开头的标签
在xpath中有函数starts-with(属性名称,开始字符),可用于定位指定属性以某个特定字符开头的标签,如下例,实现与2.1中相同功能:
'''提取href属性以/tag开头的a标签内容'''
tree.xpath("//a[starts-with(@href,'/tag')]/text()")
2.3 定位指定属性值包含特定字符片段的标签
在xpath中函数contains(属性名称,包含字符)可用于定位指定属性值包含特定字符片段的标签内容,比如我们想要找到所有text()内容中带有know的名人名言,就可以像下面这样做:
'''提取text()内容包含know的span标签对应的text()内容'''
tree.xpath("//span[contains(text(),'know')]/text()")

2.4 匹配具有某属性的所有标签
比如说我们想获取页面中所有的href超链接,就可以用下面的方式:
'''获取整个页面内所有href属性'''
tree.xpath("//@href")
2.5 同时定位多个内容
比如说我们想在一行代码里同时取得两种不同的规则下匹配的内容,可以在xpath语句中将不同的多个xpath语句用|连接起来,最终返回的结果在同一个列表里,所以使用这种语法时需要考虑取得的内容是否适合放在一起:
'''同时取得多个定位规则下的内容'''
tree.xpath("//span[contains(text(),'know')]/text() | //span[contains(text(),'world')]/text()")

2.6 选取指定节点下所有子元素
有时候我们想要快捷的获取某一节点下一级所有标签的某一属性内容,可以使用child来表示下一级节点:
'''选取class为quote的div节点下所有span子节点的text()内容'''
tree.xpath("//div[@class='quote']/child::span/text()")

当不指定标签名称而使用*代替时,代表匹配所有子节点:
'''选取class为quote的div节点下所有子节点的text()内容'''
tree.xpath("//div[@class='quote']/child::*/text()")
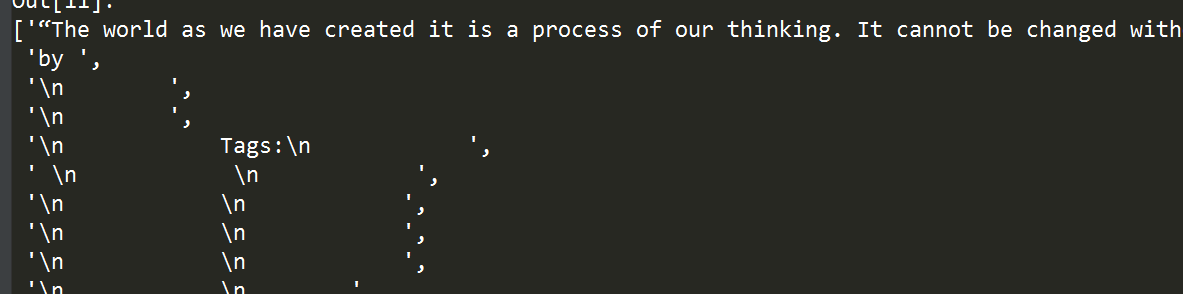
2.7 选取某一节点所有的属性值
有时候我们想要获取满足条件的节点下所有的属性值:
'''选取class为quote的div标签下所有的属性值'''
tree.xpath("//div[@class='quote']/attribute::*")
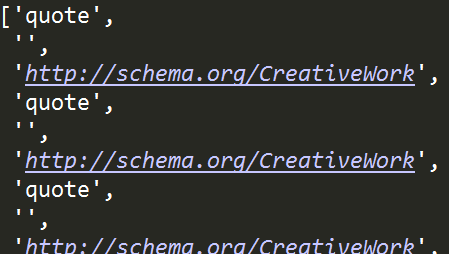
也可以指定要提取的具体属性值,如这里我们只提取href,只需要将*替换成href即可:
'''选取class为tag的a标签下所有的href属性值'''
tree.xpath("//a[@class='tag']/attribute::href")
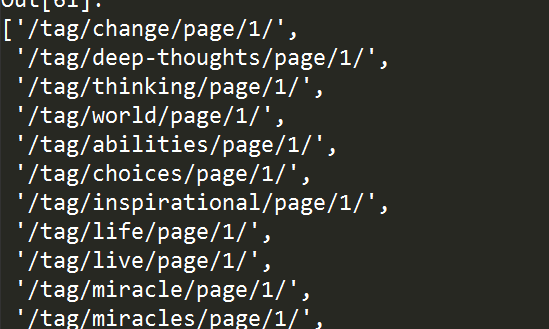
2.8 定位某一节点的祖先节点
比如我们想要获取class为keywords的meta标签之上所有标签的class属性内容,可以像下面这样:
tree.xpath("//meta[@class='keywords']/ancestor::*/@class")
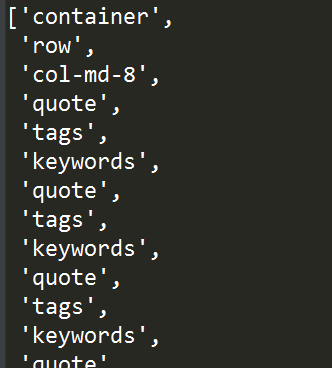
若想同时包含所有祖先节点及自己本身,则可使用ancestor-or-self:
tree.xpath("//meta[@class='keywords']/ancestor-or-self::*/text()")
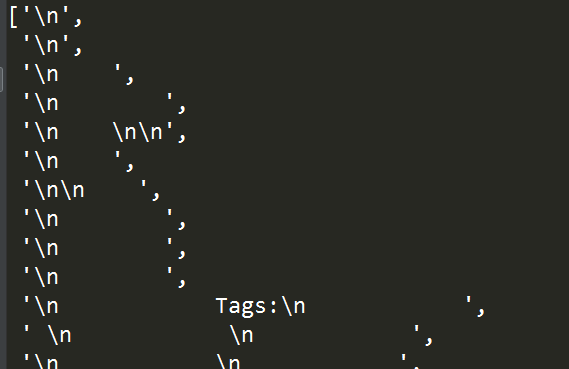
2.9 定位某一节点的后代节点
类似2.8,只不过这里我们来定位某一节点之下的所有后代节点,使用descendant:
'''获取class为tags的标签下所有后代节点中a标签的href信息'''
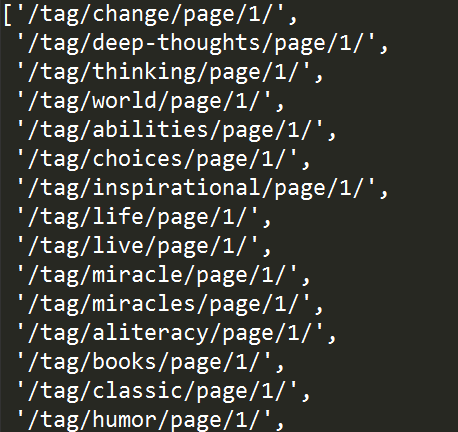
tree.xpath("//div[@class='tags']/descendant::a/@href")
2.10 条件与或非
在xpath中使用逻辑运算来定位的方法如下:
与:
'''定位class为text且itemprop为text的span标签'''
tree.xpath("//span[@class='text' and @itemprop='text']/text()")

或:
tree.xpath("//div[@class='quote' or @class='tags']/@class")
非:
'''提取所有span标签class属性不为text的class属性值'''
tree.xpath("//span[not(@class='text')]/@class")
2.11 选取指定标签结束之后的所有指定标签
在xpath中我们可以使用following来定位以某个标签在文档中的位置为起点的所有指定标签:
'''提取所有class为keywords的meta标签结束标签之后出现的标签a的text()内容'''
tree.xpath("//meta[@class='keywords']/following::a/text()")

2.12 选取指定标签开始之前的所有指定标签
与following的功能截然相反,在xpath中使用preceding可以定位指定标签之前的所有标签:
'''选取body标签之前的所有标签的text()内容'''
tree.xpath("//body/preceding::*/text()")

2.13 选取指定标签结束之后的所有同级指定标签
在following的基础上,若想定位所有指定标签之后且与指定标签同一级别的标签,可使用following-sibling:
'''提取所有class为keywords的meta标签结束标签之后出现的同级别标签a的text()内容'''
tree.xpath("//meta[@class='keywords']/following-sibling::a/text()")

2.14 选取指定标签开始之前的所有同级指定标签
类似following-sibling,使用preceding-sibling可以实现相反的效果:
'''选取body标签之前的所有同级标签的text()内容'''
tree.xpath("//body/preceding-sibling::*/text()")

2.15 对提取内容中的空格进行规范化处理
在xpath中我们可以使用normalize-space对目标内容中的多余空格进行清洗,其作用是删除文本内容之前和之后的所有\s类的内容,并将文本中夹杂的两个及以上空格转化为单个空格,下面比较使用normalize-space前后对提取结果的影响:
'''清洗前'''
tree.xpath("//p[@class='text-muted']/text()")

'''清洗后'''
tree.xpath("normalize-space(//p[@class='text-muted']/text())")

使用normalize-space之后得到的结果更加的规整,可以提高爬取数据的效率。
2.16 在xpath中使用正则表达式
有时候一些任务情况比较特殊,在xpath中可能没有对应的函数直接可以使用,这时可以在xpath语句中穿插正则表达式,比如我们想要提取class为tag且href属性符合.*?-.*?page.*?规则的a标签中的href与text()内容,就可以在传入规范的正则命名空间,并利用match来匹配自定义的正则语句,如下:
tree.xpath(r"//a[@class='tag' and ns:match(@href, '.*?-.*?page.*?')]/text() | //a[@class='tag' and ns:match(@href, '.*?-.*?page.*?')]/@href",
namespaces={"ns": "http://exslt.org/regular-expressions"})
以上就是本文的全部内容,实际上xpath中还有更多方便使用的功能,本文仅根据笔者的日常使用积累做了片面的总结,如有笔误之处望斧正!
(数据科学学习手札61)xpath进阶用法的更多相关文章
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
随机推荐
- camunda流程部署的一些简单操作
act_re_deployment:(流程部署对象表)存放流程部署的显示名和部署时间 act_re_procdef:(流程定义表)存放流程定义的属性信息 act_ge_bytearray:(资源文件表 ...
- Android毕业四年升P8,年收入超100w,他是如何做到的?
很多人从事Android开发工作多年,走过的弯和坎,不计其数,经历的心酸难与外人道也.相信大家感触最深的还是:选择大于努力.选择正确的方向,才能够走的更远,更踏实. 今天我来分享一下自己心得体会,并没 ...
- python基础【第五篇】
python第三节 1.整型及布尔值 1.1 进制转换 十进制 ----二进制 二进制 ----十进制 8421方法与普通计算 python中十进制转二进制示例:bin(51)>>> ...
- log4j 和 log4j2 在springboot中的性能对比
文章链接: https://pengcheng.site/2019/11/17/log4j-he-log4j2-zai-springboot-zhong-de-xing-neng-dui-bi/ 前言 ...
- element ui step组件在另一侧加时间轴显示
这是我开发的时候遇到的一个问题:项目需要在步骤条(竖直方向)的另一侧加时间显示,但是我在element ui 的step组件中一直没找着设置方法,所以就自己想了个办法加进来,效果如下: 代码如下,先上 ...
- 请问如何实现字符串UTF8->BIG5,BIG5->UTF8。保证送分。-Java/JavaSE
请问如何实现字符串UTF8-> BIG5,BIG5-> UTF8. ------回答--------- ------其他回答(100分)--------- public String BI ...
- 在Feign中添加自定义配置
首先先创建一个FeignConfig类,代码如下: package com.xing.config; import org.springframework.context.annotation.Bea ...
- 【模板篇】NTT和三模数NTT
之前写过FFT的笔记. 我们知道FFT是在复数域上进行的变换. 而且经过数学家的证明, DFT是复数域上唯一满足循环卷积性质的变换. 而我们在OI中, 经常遇到对xxxx取模的题目, 这就启发我们可不 ...
- Codeforces 1169E DP
题意:给你一个长度为n的序列,有q次询问,每次询问给出两个位置x和y(x < y),问是否可从x到达y?可达的定义是:如果存在一个序列(假设长度为k),其中p1 = x, pk = y,并且这个 ...
- css负边距之详解(子绝父相)
来源 | http://segmentfault.com 原文 | The Definitive Guide to Using Negative Margins 自从1998年CSS2作为推荐以 ...