【新人赛】阿里云恶意程序检测 -- 实践记录11.3 - n-gram模型调参
主要工作
本周主要是跑了下n-gram模型,并调了下参数。大概看了几篇论文,有几个处理方法不错,准备下周代码实现一下。
xgboost参数设置为:
param = {'max_depth': 6, 'eta': 0.1, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.5, 'colsample_bytree': 0.85}
n-gram模型,CountVectorizer
为了训练速度考虑,采用两折校验,对ngram_range参数,start=end,即只用某元:
| ngram | train-mean | val-mean |
|---|---|---|
| 1 | 0.113553 | 0.376238 |
| 2 | 0.086720 | 0.331593 |
| 3 | 0.085156 | 0.338862 |
| 4 | 0.102556 | 0.347408 |
| 5 | 0.090270 | 0.366249 |
import matplotlib.pyplot as plt
import numpy as np
train_mean = [0.113553, 0.086720, 0.085156, 0.102556, 0.090270]
val_mean = [0.376238, 0.331593, 0.338862, 0.347408, 0.366249]
# 绘制对比柱状图
plt.bar(x=range(1, 6), height=train_mean, label="train mean", alpha=0.8, width=bar_width)
plt.legend()
plt.xlabel("ngram_range(start=end)")
plt.ylabel("mean")
plt.title('result')
plt.show()
plt.bar(x=np.arange(1, 6), height=val_mean, label="val mean", alpha=0.8, width=bar_width)
plt.legend()
plt.xlabel("ngram_range(start=end)")
plt.ylabel("mean")
plt.title('result')
plt.show()
绘图可得:
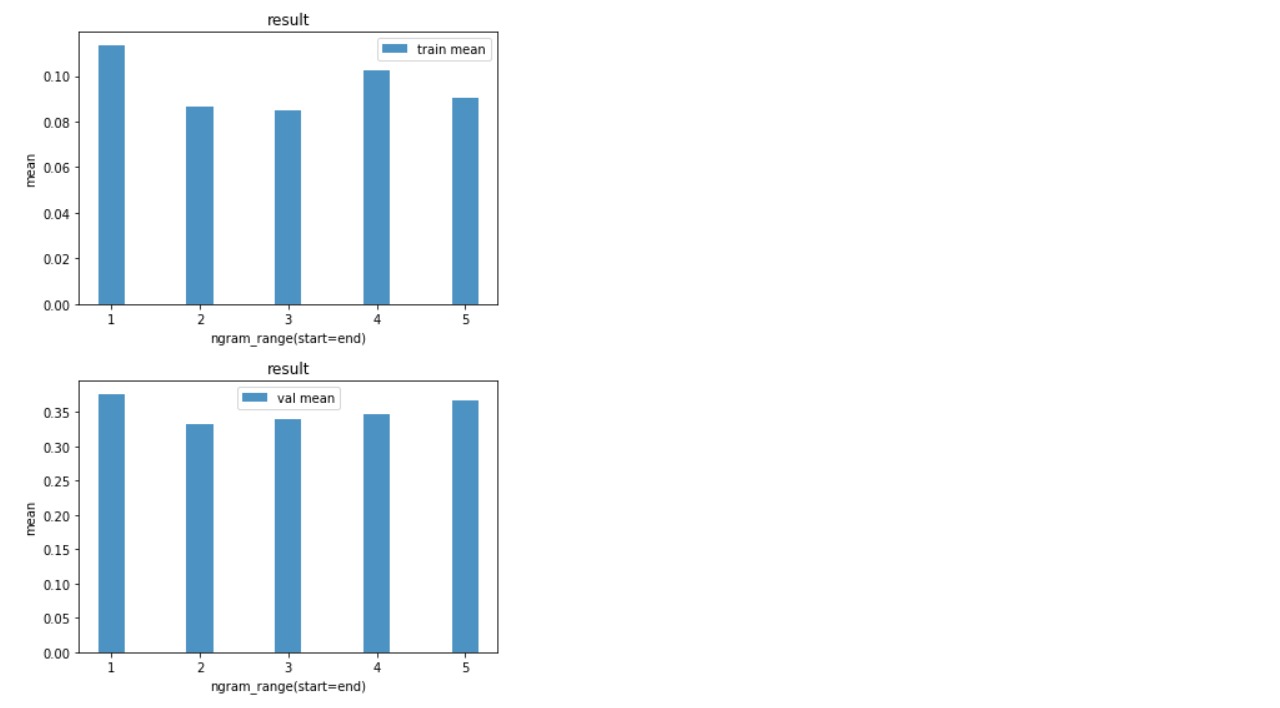
可以看到,二元、三元关系的拟合效果比较好。
所以在api序列中,依赖关系主要以短链为主,长链为辅,同时单个api也有一些价值。
而后,同样是2折校验,对start != end的情形做了一下训练。
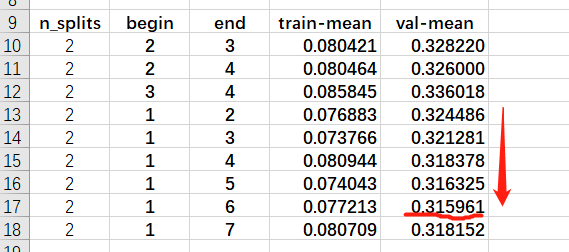
可以看到,start=1得到的结果比start=2得到的效果要好一些,
同时当start=1, end从2至6,拟合效果都有提升,当end=7之后又会变差。
所以n-gram模型,二元、三元的拟合效果比较好,加上一元,四元,五元,六元之后,效果都有提升,这几元都很有用。
此外,将2折改为5折,计算开销增大,但结果会更好一些。
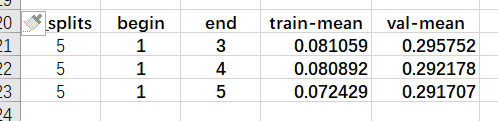
将5折得到的这几个结果,提交到线上,测试结果如下:
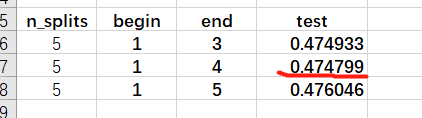
10折提交,结果如下:

在同学的基础上优化:
使用参数ngram_range=(1, 3),xgboost中subsample=0.8,

【新人赛】阿里云恶意程序检测 -- 实践记录11.3 - n-gram模型调参的更多相关文章
- 【新人赛】阿里云恶意程序检测 -- 实践记录11.10 - XGBoost学习 / 代码阅读、调参经验总结
XGBoost学习: 集成学习将多个弱学习器结合起来,优势互补,可以达到强学习器的效果.要想得到最好的集成效果,这些弱学习器应当"好而不同". 根据个体学习器的生成方法,集成学习方 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录 11.24 - word2vec模型 + xgboost
使用word2vec训练词向量 使用word2vec无监督学习训练词向量,输入的是训练数据和测试数据,输出的是每个词的词向量,总共三百个词左右. 求和:然后再将每行数据中的每个词的词向量加和,得到每行 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录10.13 - Google Colab连接 / 数据简单查看 / 模型训练
1. 比赛介绍 比赛地址:阿里云恶意程序检测新人赛 这个比赛和已结束的第三届阿里云安全算法挑战赛赛题类似,是一个开放的长期赛. 2. 前期准备 因为训练数据量比较大,本地CPU跑不起来,所以决定用Go ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录10.20 - 数据预处理 / 训练数据分析 / TF-IDF模型调参
Colab连接与数据预处理 Colab连接方法见上一篇博客 数据预处理: import pandas as pd import pickle import numpy as np # 训练数据和测试数 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录10.27 - TF-IDF模型调参 / 数据可视化
TF-IDF模型调参 1. 调TfidfVectorizer的参数 ngram_range, min_df, max_df: 上一篇博客调了ngram_range这个参数,得出了ngram_range ...
- 阿里云小程序云应用环境DIY,延长3倍免费期
阿里云清明节前刚刚推出了小程序云应用扶持计划一期活动 (活动链接见文章底部).假期研究了下以后,发觉不太给力.基本上就是给了2个月的免费测试环境,和平均2个月的基础版生产环境.而如果选用标准版生产环境 ...
- Android手机安全软件的恶意程序检测靠谱吗--LBE安全大师、腾讯手机管家、360手机卫士恶意软件检测方法研究
转载请注明出处,谢谢. Android系统开放,各大论坛活跃,应用程序分发渠道广泛,这也就为恶意软件的传播提供了良好的环境.好在手机上安装了安全软件,是否能有效的检测出恶意软件呢?下边针对LBE安全大 ...
- 阿里云centos安装docker-engine实践
近日在阿里云ECS服务器(centos系统)中安装docker,参考官方指南 https://docs.docker.com/engine/installation/linux/centos/ 大概 ...
- 阿里云负载均衡配置https记录
配置前端协议是443,后端是80 问题1记录: 例如访问https://www.xxx.com,在后端服务器上面获取是http还是https请求协议实际上是http: 因为我们先请求负载均衡,负载均衡 ...
随机推荐
- 发生android.view.ViewRoot$CalledFromWrongThreadException异常的解决方案
在Android平台下,进行多线程编程时,经常需要在主线程之外的一个单独的线程中进行某些处理,然后更新用户界面显示.但是,在主线线程之外的线程中直接更新页面显示的问题是 报异常:android.vie ...
- 机器学习(ML)十之CNN
CNN-二维卷积层 卷积神经网络(convolutional neural network)是含有卷积层(convolutional layer)的神经网络.卷积神经网络均使用最常见的二维卷积层.它有 ...
- Mysql索引优化简单介绍
一.关于MySQL联合索引 总结记录一下关于在MySQL中使用联合索引的注意事项. 如:索引包含表中每一行的last_name.first_name和dob列,即key(last_name, firs ...
- Xcode11: 删除默认Main.storyBoard, 自定义UIWindow的变化 UIWindow 不能在AppDelegate中处理
Xcode自动新增了一个SceneDelegate文件,查找了一下官方文档WWDC2019:Optimizing App Launch 发现,iOS13中appdelegate的职责发现了改变: iO ...
- css常用元素通用样式表
@charset "utf-8";html,body,a,h1,h2,h3,h4,h5,h6,p,a,b,i,em,s,u,dl,dt,dd,ul,ol,li,strong,spa ...
- expect知识梳理
1 expect expect软件用于实现非交互式操作,实际应用中常用于批量部署,可以帮助运维人员管理成千上万台服务器. expect实现非交互式操作主要是在程序发出交互式询问时,按条件传递程序所需的 ...
- JS高阶编程技巧--compose函数
先看代码: let fn1 = function (x) { return x + 10; }; let fn2 = function (x) { return x * 10; }; let fn3 ...
- 【HDU - 1176 】免费馅饼 (逆dp)
免费馅饼 Descriptions: 都说天上不会掉馅饼,但有一天gameboy正走在回家的小径上,忽然天上掉下大把大把的馅饼.说来gameboy的人品实在是太好了,这馅饼别处都不掉,就掉落在他身旁 ...
- python len函数(41)
在python中除了print函数之外,len函数和type函数应该算是使用最频繁的API了,操作都比较简单. 一.len函数简介 返回对象的长度(项目数)参数可以是序列(例如字符串str.元组tup ...
- Linux如何定位文件在磁盘的物理位置
我在学习研究Linux内核结构的时候,思考过一个问题:Linux如何定位文件在磁盘的物理位置每个文件都有一个inode,inode在内核代码中的数据结构如下: 1 struct ext4_inode ...