python多线程学习三
本文希望达到的目标:
1、服务器端与线程池 (实例demo)
2、并发插入db与线程池(实例demo)
3、线程池使用说明
4、线程池源码解析
一、基于socket的服务器与线程池连接。
1、在i7内核,windows机器下,处理300笔客户端发的请求(客户端开启3个进程,每个进程串行发送数据100笔),为模拟服务器处理过程,服务器在返回数据前,服务器休眠0.5s(如果没有的话,线程池和单进程是一样的效果),使用基于线程池(同时存在10个线程)构建的服务器端,耗时为50s,随时创建随时销毁的服务器端,耗时为140s。
这个对比不能说明很多问题,因为不够真实,一方面客户端的并发量没上去;另一方面服务器端的应答时间比较随意,如果服务器端不sleep 0.5s,导致的结果是两种写法的耗用时间会是差不多的,因为创建单个线程的时间不是很长。但是结果差距的明显,说明了线程池在场景下还是有一定的性能优势的(开启10个进程,每个进程发送数据100笔,基于线程池的服务器也能在50s内处理完成)。
import thread import time, threading
import socket host =''
port =8888
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind((host,port))
s.listen(3) class MyThread(threading.Thread):
def __init__(self,func,args,name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args def run(self):
self.func(*self.args) def handle_request(conn_socket):
recv_data = conn_socket.recv(1024)
reply = 'HTTP/1.1 200 OK \r\n\r\n'
reply += 'hello world'
time.sleep(0.5)
conn_socket.send(reply)
conn_socket.close() def main():
while True:
conn_socket, addr = s.accept()
t = MyThread(handle_request,(conn_socket,))
t.start()
t.join() if __name__ == '__main__':
main()
还有网上重写的线程池,如果需要使用线程池做真正的项目,个人不建议参考网上这些不规范的脚本:
#!/usr/bin/env python
#coding=gbk import socket
from Queue import Queue
from threading import Thread
import threading """
重写threadpool,自定义和实现线程池,实现web服务端多线程处理
"""
host =''
port =
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind((host,port))
s.listen() class ThreadPoolManger():
def __init__(self,thread_num):
self.work_queue =Queue()
self.thread_num = thread_num
self._init_threading_pool(self.thread_num) def _init_threading_pool(self,thread_num):
for i in range(thread_num):
thread= ThreadManger(self.work_queue)
thread.start() def add_job(self,func,*args):
self.work_queue.put((func,args)) class ThreadManger(Thread):
def __init__(self,work_queue):
Thread.__init__(self)
self.work_queue = work_queue
self.daemon =True def run(self):
while True:
target,args = self.work_queue.get()
target(*args)
self.work_queue.task_done() def handle_request(conn_socket):
recv_data = conn_socket.recv()
reply = 'HTTP/1.1 200 OK \r\n\r\n'
reply += 'hello world'
print 'thread %s is running ' % threading.current_thread().name
conn_socket.send(reply)
conn_socket.close() thread_pool = ThreadPoolManger()
while True:
conn_socket,addr =s.accept()
thread_pool.add_job(handle_request,*(conn_socket,)) s.close()
二、向DB插入数据1w条
不考虑插入数据时的一些技巧(比如拼接sql批量插入;或者先写文件,再把调用mysql命令把文件导入db),单纯的基于多线程和线程池的差异对比,结果是同时开启10个线程插入1w笔数据耗时为32s,而使用线程池(size=10)耗时为9s,两者DB的连接
都是每个线程有自己的句柄,内部实现是一致的,这个结果充分的说明了线程池的优势。
#!/usr/bin/env python
#coding=GBK
from mytool.mysql import MySql
import threading
import time class MyThread(threading.Thread):
def __init__(self,func,args,name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args def run(self):
self.func(*self.args) def make_t_tcpay_list(Flistid,Ftde_id,n):
Fnum =0.5
Fabankid =
Fuid =
wbdb_mysql = MySql("10.125.56.154", "root", "", "wd_db")
for i in range(n):
sql ="**" //自定义完成
wbdb_mysql.connect()
wbdb_mysql.execute_insert_command(sql)
Flistid = Flistid +
Ftde_id = Ftde_id + if __name__ == "__main__": start = time.time()
Threads=[]
Flistid =
Ftde_id = 1 for i in range():
print i
Flistid = Flistid+
Ftde_id = Ftde_id +
t = MyThread(make_t_tcpay_list, (Flistid,Ftde_id,))
Threads.append(t) for i in range():
Threads[i].start() for i in range():
Threads[i].join() end = time.time()
print end - start
下面是线程池:
#!/usr/bin/env python
#coding=GBK
from mytool.mysql import MySql
import threadpool
import time def make_t_tcpay_list(n,Flistid,Ftde_id):
Fnum =0.5
Fabankid =
Fuid =
wbdb_mysql = MySql("10.125.56.154", "root", "root1234", "wd_db")
wbdb_mysql.connect() for i in range(int(n)):
sql ="" //自定义完成
wbdb_mysql.execute_insert_command(sql)
Flistid =int(Flistid) +
Ftde_id =Ftde_id + if __name__ == "__main__": start = time.time()
lst_vars_1 = ['','',]
lst_vars_2 = ['','',]
lst_vars_3 = ['','', ]
lst_vars_4 = ['','', ]
lst_vars_5 = ['','', ]
lst_vars_6 = ['','', ]
lst_vars_7 = ['', '', ]
lst_vars_8 = ['', '', ]
lst_vars_9 = ['', '', ]
lst_vars_10 = ['', '', ] func_var = [(lst_vars_1, None), (lst_vars_2, None), (lst_vars_3, None), (lst_vars_4, None), (lst_vars_5, None), (lst_vars_6, None), (lst_vars_7, None), (lst_vars_8, None), (lst_vars_9, None), (lst_vars_10, None)] pool = threadpool.ThreadPool()
requests = threadpool.makeRequests(make_t_tcpay_list, func_var)
for req in requests:
pool.putRequest(req)
pool.wait()
end = time.time()
print end - start
三、线程池使用说明
线程池基本原理: 我们把任务放进队列中去,然后开N个线程,每个线程都去队列中取一个任务,执行完了之后告诉系统说我执行完了,然后接着去队列中取下一个任务,直至队列中所有任务取空,退出线程。
通过上面2个demo,对单线程,多线程,线程池实际处理的差异性有了一定的了解。但是实际因为Cpython的GIL全局排他锁的存在,导致任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁。多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
对于IO密集型的任务,多线程还是起到很大效率提升(之前的两个demo都属于IO密集型),因为进行耗时的IO操作的时候,会能释放GIL,从而其他线程就可以获取GIL,提供了任务的并发处理能力。比如,计算时间占20%, IO等待时间80%,假设任务完成需要5s,可以想象成完成任务过程:CPU占用1秒,等待时间4秒,CPU在线程等待时,可以切换另外一个线程进程,这个线程的CPU运行完了,还能允许再激活3个线程,这个是第一个线程等待时间结束了,CPU切换回去,第一个线程任务就处理完成了,完成5个任务,只需要10s。这里还有一个公式: 线程数= N*(x+y)/x;N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,这样能让CPU的利用率最大化。 由于有GIL的影响,python只能使用到1个核,所以这里设置N=1
而对于计算密集型的任务,先看一个简单的demo,计算100次(1+2+...+10000),单进程耗时0.44s,而多进程和线程池耗时呢?比单进程还差,耗时1.2s。
单进程:
import time, threading def change_it(n):
for j in range(n):
sum =
for i in range():
sum = sum + i if __name__ == "__main__":
start = time.time()
change_it()
end = time.time()
print end - start
耗时: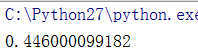
线程池(多进程):
#coding=GBK
from mytool.mysql import MySql
import threadpool
import time def change_it(n):
for j in range(n):
sum =
for i in range():
sum = sum + i if __name__ == "__main__": start = time.time() func_var = [,,,,,,,,,] pool = threadpool.ThreadPool()
requests = threadpool.makeRequests(change_it, func_var)
for req in requests:
pool.putRequest(req)
pool.wait()
end = time.time()
print end - start
耗时:
看到python在多线程的情况下居然比单线程整整慢了61%。对于由于一个CPU密集型的任务,使用多线程编程,会因为CPU一直处于运行状态,而线程又要等待获取GIL锁,从而进行线程处于循环等待状态,导致性能反而下降。
四、线程池源码解析
1、核心类:ThreadPool
类成员变量:
class ThreadPool:
def __init__(self, num_workers, q_size=):
self.requestsQueue = Queue.Queue(q_size)
self.resultsQueue = Queue.Queue()
self.workers = []
self.workRequests = {}
self.createWorkers(num_workers)
用户自定义的类似,不同的地方多了一个结果队列,把创建的运行线程全都放入了workers 内,且把所有的任务对象化workRequests
关键函数:
def createWorkers(self, num_workers):
"""Add num_workers worker threads to the pool.""" for i in range(num_workers):
self.workers.append(WorkerThread(self.requestsQueue,
self.resultsQueue))
def putRequest(self, request, block=True, timeout=):
"""Put work request into work queue and save its id for later.""" assert isinstance(request, WorkRequest)
self.requestsQueue.put(request, block, timeout)
self.workRequests[request.requestID] = request
2、工作线程类 :WorkerThread
成员变量:
class WorkerThread(threading.Thread):
def __init__(self, requestsQueue, resultsQueue, **kwds):
threading.Thread.__init__(self, **kwds)
self.setDaemon()
self.workRequestQueue = requestsQueue
self.resultQueue = resultsQueue
self._dismissed = threading.Event()
self.start()
关键函数:
def run(self):
while not self._dismissed.isSet():
# thread blocks here, if queue empty
request = self.workRequestQueue.get()
if self._dismissed.isSet():
# if told to exit, return the work request we just picked up
self.workRequestQueue.put(request)
break # and exit
try:
self.resultQueue.put(
(request, request.callable(*request.args, **request.kwds))
)
except:
request.exception = True
self.resultQueue.put((request, sys.exc_info()))
3、生成任务对象
def makeRequests(callable, args_list, callback=None, exc_callback=None):
requests = []
for item in args_list:
if isinstance(item, tuple):
requests.append(
WorkRequest(callable, item[], item[], callback=callback,
exc_callback=exc_callback)
)
else:
requests.append(
WorkRequest(callable, [item], None, callback=callback,
exc_callback=exc_callback)
)
return requests
其中任务对象类定义为:
class WorkRequest:
if requestID is None:
self.requestID = id(self)
else:
try:
hash(requestID)
except TypeError:
raise TypeError("requestID must be hashable.")
self.requestID = requestID
self.exception = False
self.callback = callback
self.exc_callback = exc_callback
self.callable = callable
self.args = args or []
self.kwds = kwds or {}
python多线程学习三的更多相关文章
- Python基础学习三
Python基础学习三 1.列表与元组 len()函数:可以获取列表的元素个数. append()函数:用于在列表的最后添加元素. sort()函数:用于排序元素 insert()函数:用于在指定位置 ...
- python 多线程学习小记
python对于thread的管理中有两个函数:join和setDaemon setDaemon:如果在程序中将子线程设置为守护线程,则该子线程会在主线程结束时自动退出,设置方式为thread.set ...
- python多线程学习(一)
python多线程.多进程 初探 原先刚学Java的时候,多线程也学了几天,后来一直没用到.然后接触python的多线程的时候,貌似看到一句"python多线程很鸡肋",于是乎直接 ...
- python多线程学习记录
1.多线程的创建 import threading t = t.theading.Thread(target, args--) t.SetDeamon(True)//设置为守护进程 t.start() ...
- python多线程学习二
本文希望达到的目标: 多线程同步原语:互斥锁 多线程队列queue 线程池threadpool 一.多线程同步原语:互斥锁 在多线程代码中,总有一些特定的函数或者代码块不应该被多个线程同时执行,通常包 ...
- python 多线程学习
多线程(multithreaded,MT),是指从软件或者硬件上实现多个线程并发执行的技术 什么是进程? 计算机程序只不过是磁盘中可执行的二进制(或其他类型)的数据.它们只有在被读取到内存中,被操作系 ...
- python多线程学习一
本文希望达到的目标: 多线程的基本认识 多线程编程的模块和类的使用 Cpython的全局解释器锁GIL 一.多线程的基本认识 多线程编程的目的:并行处理子任务,大幅度地提升整个任务的效率. 线程就是运 ...
- Python多线程笔记(三),queue模块
尽管在Python中可以使用各种锁和同步原语的组合编写非常传统的多线程程序,但有一种首推的编程方式要优于其他所有编程方式即将多线程程序组织为多个独立人物的集合,这些任务之间通过消息队列进行通信 que ...
- JAVA多线程学习- 三:volatile关键字
Java的volatile关键字在JDK源码中经常出现,但是对它的认识只是停留在共享变量上,今天来谈谈volatile关键字. volatile,从字面上说是易变的.不稳定的,事实上,也确实如此,这个 ...
随机推荐
- myeclipse及Eclipse中.classpath、.project、.settings、.mymetadata(myeclipse特有)介绍
引言 今天在创建java项目的时候遇到了很多的错误,在解决的过程中遇到了一些根本不知道什么作用的文件,然后按照网上的一些做法可以将问题解决,但是这也说明我们在学习的时候很多基础和细节的地方是我们薄弱的 ...
- Oracle字段根据逗号分割查询数据
需求是表里的某个字段存储的值是以逗号分隔开来的,要求根据分隔的每一个值都能查出来数据,但是不能使用like查询. 数据是这样的: 查询的sql如下: select * from ( select gu ...
- linux可执行文件添加到PATH环境变量的方法
linux命令行下面执行某个命令的时候,首先保证该命令是否存在,若存在,但输入命令的时候若仍提示:command not found 这个时候就的查看PATH环境变量的设置了,当前命令是否存在于PAT ...
- JavaCC从入门到出门
一.JavaCC JavaCC是java的compiler compiler.JavaCC是LL解析器生成器,可处理的语法范围比较狭窄,但支持无限长的token超前扫描. 安装过程: 我是从githu ...
- 三维计算机视觉 — 中层次视觉 — Point Pair Feature
机器人视觉中有一项重要人物就是从场景中提取物体的位置,姿态.图像处理算法借助Deep Learning 的东风已经在图像的物体标记领域耍的飞起了.而从三维场景中提取物体还有待研究.目前已有的思路是先提 ...
- centos 7 IP不能访问nginx Failed connect to 185.239.226.111:80; No route to host解决办法
服务器环境 centos 7.4 问题描述 1.可以ping通IP ,用IP访问nginx 不能访问,在服务器上curl localhost curl 185.239.226.111可以获得 [ro ...
- C# 不安装Oracle客户端情况下,如何连接到Oracle数据库
简介: 在我们开发应用场景经常碰到需要连接Oracle数据库,这也是相当常见的一种情况.一般.Net环境连接Oracle数据库,可以通过TNS/SQL.NET 配置文件,而 TNS 必须要 Oracl ...
- nfs文件共享服务
文件共享服务端10.100.1.13: yum install -y rpcbind nfs-utils #rpcbind可以给nfs开多个端口 service rpcbind start serv ...
- python 笔记 week1-- if while for
1.添加环境变量 windows要加环境变量.linux若升级版本不一致, #!/usr/bin/env python 调用环境变量中的python #!/usr/bin/python 调用系统中默认 ...
- 下载Crypto,CyCrypto,PyCryptodome 报错问题
python下载Crypto,CyCrypto,PyCryptodome,如有site-packages中存在crypto.pycrypto,在pip之前,需要pip3 uninstall crypt ...