Hadoop完全分布式搭建全过程
本次操作共4台虚拟机(node211,node212,node213,node214),node211为NameNode,其余3台为DataNode,SecondaryNamenode为node212
一、角色资源对应分配
NN DN SNN
node211: *
node212: * *
node213: *
node214: *
二、基础设施配置(node211-node214)
网络:IP --》/etc/sysconfig/network-scripts/ifcfg-eth0
hosts --》/etc/hosts
hostname --》/etc/sysconfig/network

|

ssh配置(node211):
cd ~/.ssh
--如果此目录不存在:ssh localhost,然后再exit退出 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
--生成的密钥对:id_rsa和id_rsa.pub。默认存储在"/home/hadoop/.ssh"文件夹下 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
--把id_rsa.pub追加到授权的key里面去
node211:发送node211公钥到其他主机对应目录
cd ~/.ssh
scp ./id_dsa.pub root@node212:`pwd`/node211.pub
scp ./id_dsa.pub root@node213:`pwd`/node211.pub
scp ./id_dsa.pub root@node214:`pwd`/node211.pub
node212-node214:
cd ~/.ssh
cat node211.pub >> authorized_keys
jdk配置(node211-node214):
rpm -i jdk-7u67-linux-x64.rpm export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
三、应用搭建
文件解压部署(node211):
tar xf hadoop-2.6.5.tar.gz --解压Hadoop
mkdir -p /opt/manzi --创建文件夹
mv ~/hadoop/ /opt/manzi/ --文件拷贝
vi /etc/profile --配置Hadoop环境变量
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/manzi/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
四、应用配置(node211)
文件目录
cd $HADOOP_HOME/etc/hadoop --hadoop配置文件目录
vi hadoop-env.sh
export JAVA_HOME=/usr/java/default --修改jdk环境变量为静态路径(原写法${JAVA_HOME取不到值})
vi core-site.xml --NameNode配置文件
<!--决定NameNode在哪里启动-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node211:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/manzi/hadoop/local</value>
</property>
vi hdfs-site.xml --hdfs配置文件
//副本数量为2个
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node212:50090</value>
</property>
vi slaves --DataNode配置文件
node212
node213
node214
将配置完毕的Hadoop拷贝到其他主机
cd /opt --将Hadoop拷贝到其他主机
scp -r ./manzi/ node212:`pwd`
scp -r ./manzi/ node213:`pwd`
scp -r ./manzi/ node214:`pwd`
scp /etc/profile node212:/etc --拷贝profile文件到其他主机
scp /etc/profile node213:/etc
scp /etc/profile node214:/etc
五、启动程序
到此为止,Hadoop配置完毕,启动程序
1、NameNode格式化(node211)
hdfs namenode -format
启动成功后 ,NameNode配置文件对应目录会有相应name文件夹及生成新的fsimage及edits文件
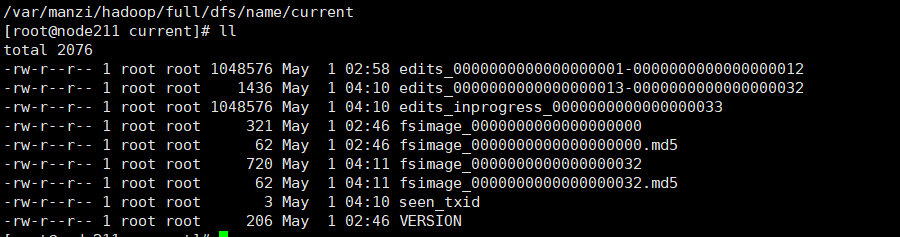
|
2、启动程序hdfs(node211)
start-dfs.sh
运行到此步骤,web页面能查看到文件系统及节点情况,启动日志也可以看出是否启动成功

|

六、测试
在user文件夹下添加root用户文件夹
hdfs dfs -mkdir -p /user/root
添加数据测试,此处为方便查看block数量,设置block大小为1M
hdfs dfs -D dfs.blocksize=1048576 -put file.txt /user/root
web页面查看数据

|
Hadoop完全分布式搭建全过程的更多相关文章
- hadoop完全分布式搭建HA(高可用)
2018年03月25日 16:25:26 D调的Stanley 阅读数:2725 标签: hadoop HAssh免密登录hdfs HA配置hadoop完全分布式搭建zookeeper 配置 更多 个 ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- 3.hadoop完全分布式搭建
3.Hadoop完全分布式搭建 1.完全分布式搭建 配置 #cd /soft/hadoop/etc/ #mv hadoop local #cp -r local full #ln -s full ha ...
- Hadoop伪分布式搭建(一)
下面内容主要说明在Windows虚拟机上面,怎么搭建一个Hadoop伪分布式,并如何运行wordcount程序和网页查看HDFS文件系统. 1 相关软件下载和安装 APACH官网提供hadoop版本 ...
- Hadoop伪分布式搭建步骤
说明: 搭建环境是VMware10下用的是Linux CENTOS 32位,Hadoop:hadoop-2.4.1 JAVA :jdk7 32位:本文是本人在网络上收集的HADOOP系列视频所附带的 ...
- Hadoop 完全分布式搭建
搭建环境 https://www.cnblogs.com/YuanWeiBlogger/p/11456623.html 修改主机名------------------- 1./etc/hostname ...
- hadoop 伪分布式搭建
下载hadoop1.0.4版本,和jdk1.6版本或更高版本:1. 安装JDK,安装目录大家可以自定义,下面是我的安装目录: /usr/jdk1.6.0_22 配置环境变量: [root@hadoop ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
- Hadoop完全分布式搭建流程
centos7 搭建完全分布式 Hadoop 环境 SSR 前言 本次教程是以先创建 四台虚拟机 为基础,再配置好一台虚拟机的情况下,直接复制文件到另外的虚拟机中(这样做大大简化了安装流程) 且本次 ...
随机推荐
- sqlserver中xml查询
DECLARE @DOC XML =' <books> <book category="C#"> <title language="e ...
- 使用AddressSanitizer做内存分析(一)——入门篇
使用AddressSanitizer做内存分析 新建文件mem_leak.cpp,键入代码: #include <iostream> int main() { ]; p = NULL; ; ...
- java.lang.NoSuchMethodError: org.springframework.dao.IncorrectResultSizeDataAccessException
spring data jpa 运用,在dao类中写自己新增的方法,使用@query写hql语句,出现以下异常: Caused by: java.lang.NoSuchMethodError: or ...
- Creating Procedural Textures
[Creating Procedural Textures] 由程序主生贴图,然后设置给Material.首先定义需要的数据: 在Start方法中完成初始化,注意设置的是_MainTex. 实现Gen ...
- Apache Flume的介绍安装及简单案例
概述 Flume 是 一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件.Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink).为了保证 ...
- 高性能Web服务器Nginx的配置与部署研究(7)核心模块之主模块的非测试常用指令
1. error_log 含义:指定存储错误日志的文件 语法:error_log <file> [debug|info|notice|warn|error|crit] 缺省:${prefi ...
- 解剖Nginx·自动脚本篇(4)工具型脚本系列
目录 auto/have 向自动配置头文件追加可用宏定义(objs/ngx_auto_config.h) auto/nohave 向自动配置头文件追加不可用宏定义(objs/ngx_auto_conf ...
- 导入txt文件到SQL SERVER 2008
最近在学习数据库,想要试处理大量数据.大量的数据手动输入是不可能的了,所以需要导入.本人上网看了不少的教程,然后下载了txt格式的一万条彩票开奖记录数据.但是把这些数据导入到SQL Server 20 ...
- Git自动补全
一.简介 假使你使用命令行工具运行Git命令,那么每次手动输入各种命令是一件很令人厌烦的事情.为了解决这个问题,你可以启用Git的自动补全功能,完成这项工作仅需要几分钟. 二.操作步骤 1) cd ...
- Luogu 4705 玩游戏
看见这个题依稀想起了$5$月月赛时候的事情,到现在仍然它感觉非常神仙. 游戏$k$次价值的期望答案 $$ans_k = \frac{1}{nm}\sum_{i = 1}^{n}\sum_{j = 1} ...