MySQL 08 详解read view:事务到底是隔离的还是不隔离的?
场景引入
我们知道,在可重复读的隔离级别下,一个事务A启动的时候会创建一个read view,之后在这个事务A执行期间,即使其他事务修改数据,事务A看到的仍然和启动时相同。
考虑一个问题,假如该事务A想要对一行做更新,而此时这行的行锁被其他事务B持有,那么事务A会被锁住而等待行锁。当事务A获取到行锁想要查询或更新时,它读到的值是启动时看到的旧值还是被事务B更新后的新值呢?
我们以一个有两行数据(id,k)=(1,1),(2,2)的表为例。假设现在有三个事务A,B,C,其语句时间顺序如下:

首先,需要注意事务启动时机:begin/start transaction并不会直接启动事务,而是执行到它们之后的第一个操作InnoDB表的语句,才会真正启动事务。如果想要马上启动一个事务,可以使用start transaction with consistent snapshot,就像事务A和事务B那样。而对于事务C没有显式使用语句,表示更新语句本身就是一个事务,会在语句完成时自动提交。
上面这个例子就是我们要考虑的问题的一个场景,事务B先启动了事务,而想要更新的行先被事务C更新,之后事务B自己更新并查询;事务A在事务B之后查询同一行。那么事务A和事务B查询结果是多少呢?
答案是:事务A得到的结果是k=1,事务B得到的结果是k=3。
如果答案和你想的不一样,那么可以继续往下读,相信最后能解答疑惑。
快照在MVCC里如何工作
在可重复读的隔离级别下,事务在启动时就会有一个快照,这个快照是基于整个库的。
接下来首先来看快照如何实现:
InnoDB里每个事务都有一个唯一的事务ID称为transaction id,该ID在事务开始时向InnoDB的事务系统申请,按照申请顺序严格递增。
而每行数据有多个版本,每次有事务更新数据,都会生成一个新的数据版本,并且把事务的transaction id赋值给这个数据版本,记为row trx_id。同时,旧的数据版本依然会被保留,且可以在新数据版本中通过一定方法获取到旧数据版本。下图表示了一个记录被多个事务更新的过程:
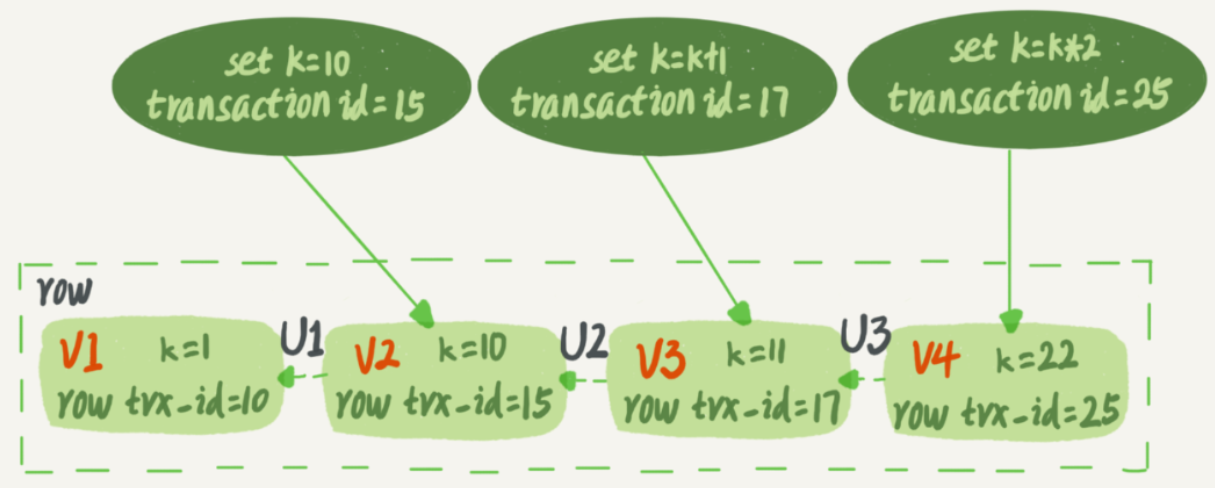
图中,下方的矩形就代表了不同的数据版本。而\(U_i\)实际就代表了undo log。只要获取了最新的数据版本和undo log,就能回滚出历史数据版本。
为了达到可重复读的定义,实际上是在一个事务启动的时候,允许其看见它自己创建的以及在它启动前已经生成的数据版本,而不允许看见在它启动时还未生成的数据版本。
在实现上,InnoDB为每个事务构造一个数组,用来保存在这个事务启动瞬间,当前正在活跃的事务ID。这里,活跃指的是启动但未提交的事务。同时,还会记录数组里面事务ID的最小值,以及当前系统里已经创建过的事务ID的最大值+1。
数组+最小值+(最大值+1)+当前事务ID,实际上就组成了当前事务的一致性视图read view。
而数据版本是否可见,就是基于read view和数据版本的row trx_id。read view的数组和字段会把row trx_id分为几种情况:
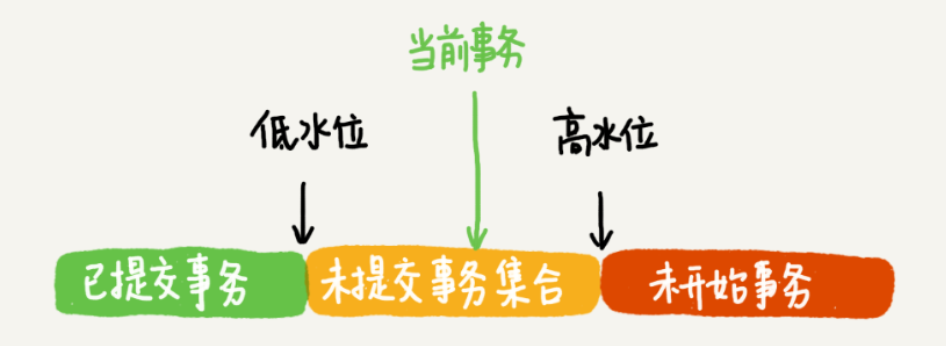
对于当前启动的事务,一个数据版本的row trx_id,有如下可能:
落在绿色部分,表示该版本在当前事务启动前已提交或是自己创建的,可见;
落在红色部分,表示该版本不是由所有已创建出来的事务启动的,不可见;
落在黄色部分
若row trx_id在数组中,表示是活跃事务生成的,还未提交,不可见;
若row trx_id不在数组中,表示是已经提交的事务生成的,可见。
所以,由于所有数据都有多个版本,每个创建的事务都有对应的快照。
接下来分析“场景引入”里事务A的查询结果为什么是k=1:
这里先做几个假设。假设事务A开始前,系统里只有一个活跃事务ID为99,事务A,B,C的ID为100,101,102且当前系统只有四个事务;在三个事务启动前,(1,1)这一行的数据的row trx_id为90。
根据该假设,事务A的read view中的数组为[99,100],事务B的read view中的数组为[99,100,101],事务C的read view中的数组为[99,100,101,102]。
我们分析事务A相关的操作:
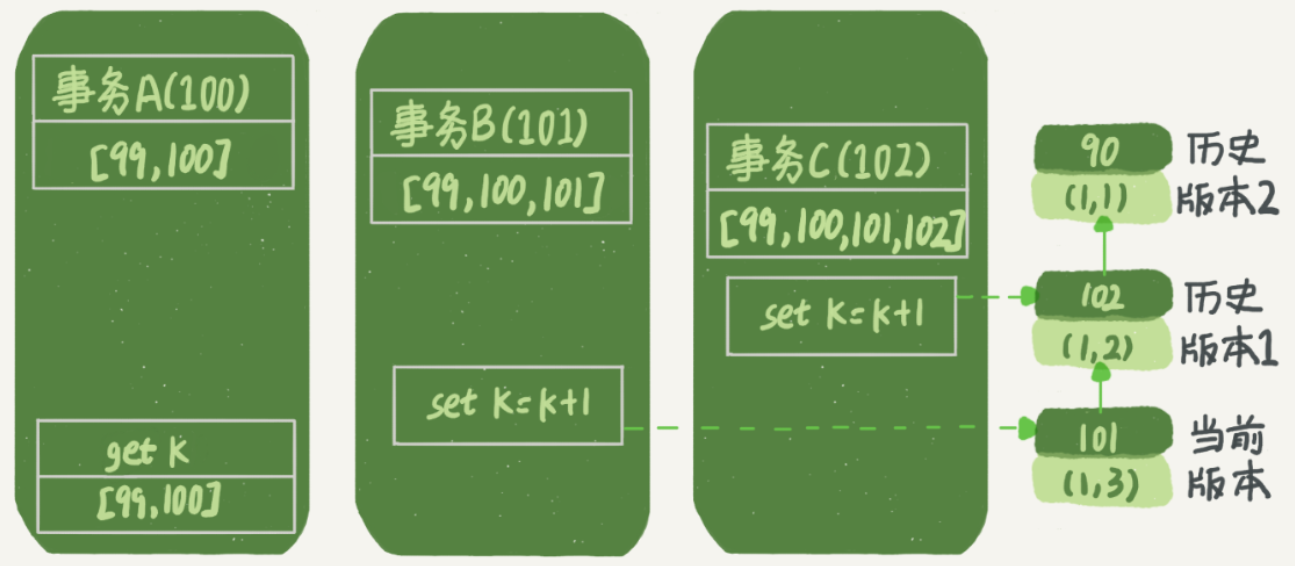
可以发现,尽管在事务A做查询时,数据已经改为了(1,3),但由于该版本的row trx_id=101,不存在于事务A的read view数组中,因此该版本对事务A不可见。事务A查询语句的流程应该是:
找到(1,3),发现不可见;
找到上一个版本(1,2),发现不可见;
继续向前,找到(1,1),是一个可见的数据版本。
通过以上分析,相信你已经理解为什么事务A的查询结果是k=1了。但若每次分析都像这样,未免有些麻烦,因此我们给出总结:一个数据版本,对于一个事务视图来说,除了自己的更新总是可见,有三种情况:
版本未提交,不可见;
版本已提交,但是是在read view创建后提交的,不可见;
版本已提交,而且是在read view创建前提交的,可见。
以上总结对比前面与row trx_id比较分析的方法,其实就是去掉了数字的对比,只用时间先后顺序判断。
更新逻辑
分析事务B相关的操作:
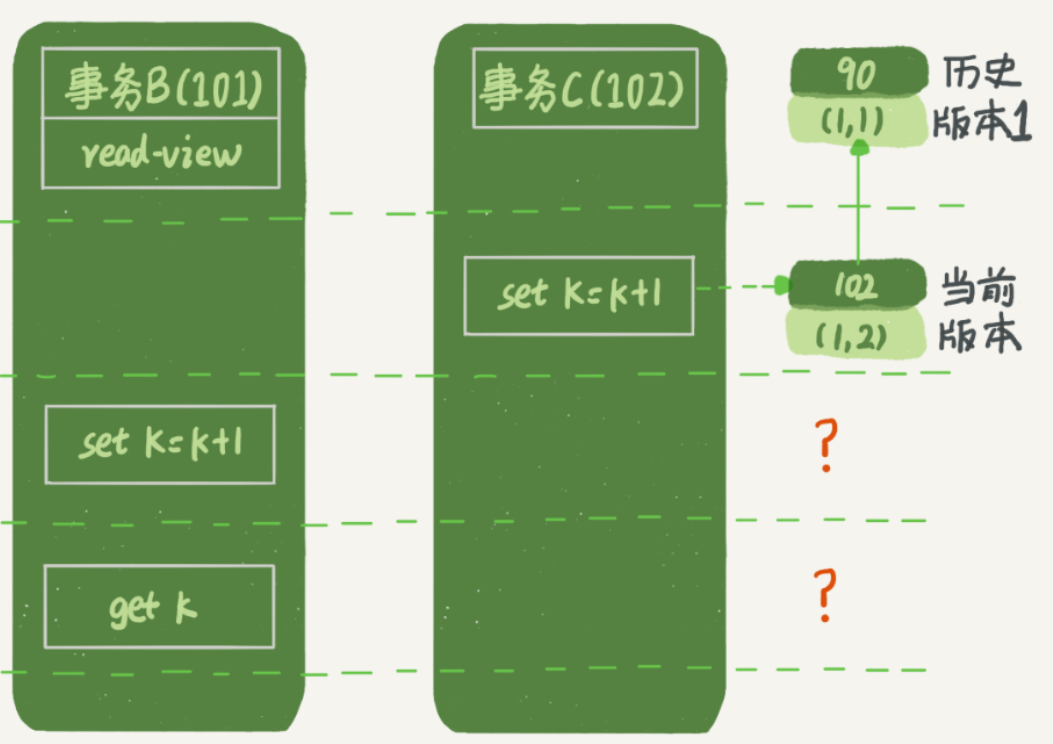
可以发现,如果我们像分析事务A那样去分析事务B,会认为事务B看不到(1,2)这个数据版本。
这个问题出在混淆了“快照读”和“当前读”。当前读指的是读最新版本的数据。由于更新数据都是先读后写,它用到的是当前读而不再是快照读。
知道了这个规则后,就比较好理解答案了,事务B在更新时能拿到数据(1,2),从而更新后生成了一个新的数据版本(1,3),且该版本的row trx_id为事务B的ID 101。那么之后事务B在查询时,能查到由自己更新的数据版本,得到结果为k=3。
当前读除了在update语句上会生效,如果使用select … lock in share mode / for update,也是当前读。因此,如果对事务A的查询语句加锁,它也能查询出k=3。
假设事务C不是马上提交的,而是变成了下面这样:

此时,就需要考虑上一篇文章介绍的“两阶段锁协议”。由于事务C’ 没有提交,其在id=1这一行上加的写锁并不会释放。而事务B是当前读,必须加锁读最新版本,因此会被锁住,直到事务C’ 释放这个行锁。
从可重复读到读已提交
到这里,我们可以归纳事务的可重复读的能力是如何实现的:核心是read view,而事务更新数据的时候,只能用当前读,如果读取行的行锁被其他事务占用,就需要进入锁等待。
可重复读和读已提交的区别:
读已提交隔离级别下,每个语句执行前都会生成一个read view。
可重复读隔离级别下,只在事务开始时创建read view。
最后我们再来分析一下在读已提交的隔离级别下,一开始的场景中事务A和事务B的读取结果。画出状态图:
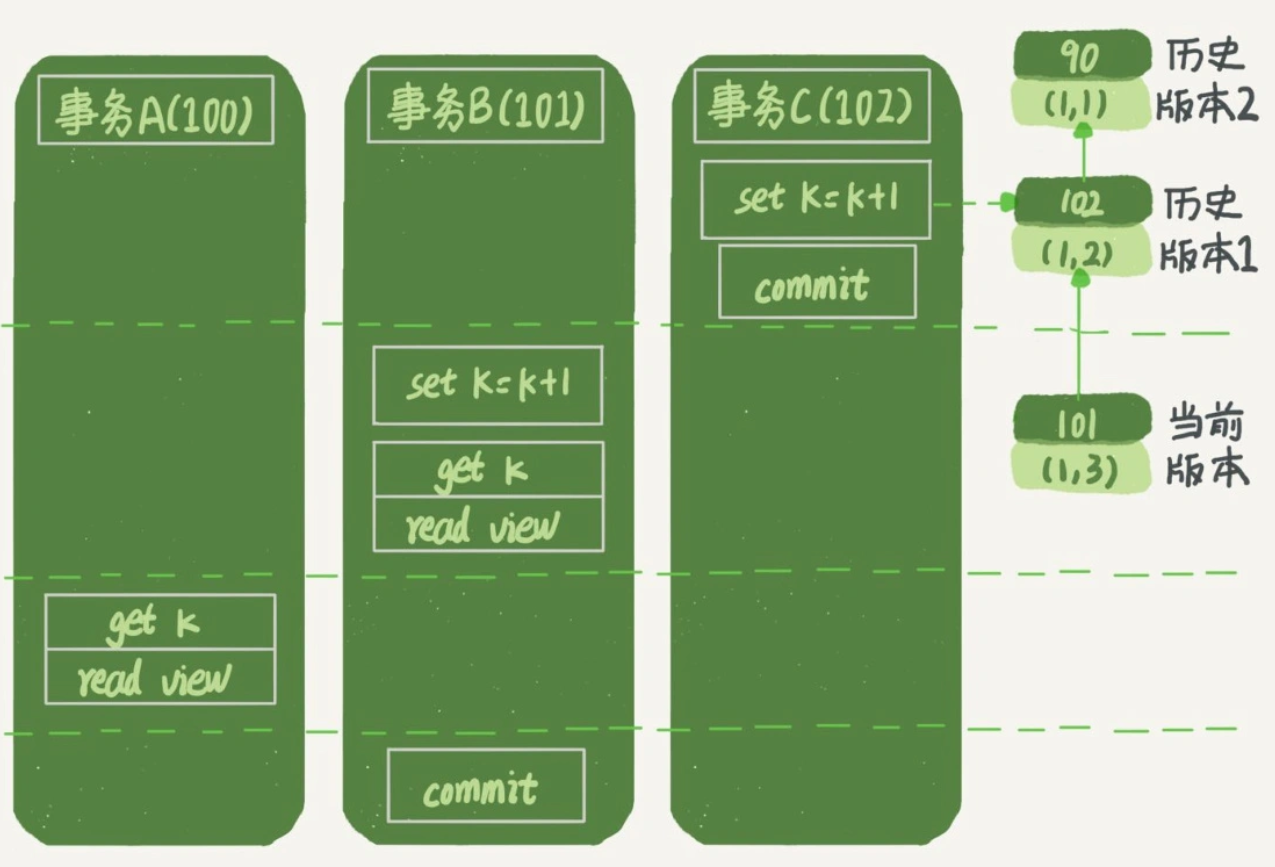
对于事务B,答案依然是k=3。
对于事务A,其创建read view时已经能看到(1,2)的版本,但由于事务B还未提交,事务A并不能看到(1,3)的版本,因此事务A查询结果为k=2。
MySQL 08 详解read view:事务到底是隔离的还是不隔离的?的更多相关文章
- MySQL状态变量详解
MySQL状态变量详解 mysql的状态变量(status variables)记录的mysql服务器的运行状态信息.查看语法如下: SHOW [GLOBAL | SESSION] STATUS; S ...
- MySQL 数据类型 详解
MySQL 数据类型 详解 MySQL 的数值数据类型可以大致划分为两个类别,一个是整数,另一个是浮点数或小数.许多不同的子类型对这些类别中的每一个都是可用的,每个子类型支持不同大小的数据,并且 My ...
- MySQL配置文件详解
MYSQL 配置文件详解 “全局缓存”.“线程缓存”,全局缓存是所有线程共享,线程缓存是每个线程连接上数据时创建一个线程(如果没有设置线程池),假如有200连接.那就是200个线程,如果参数设定值是1 ...
- MySQL权限详解
MySQL权限级别介绍 MySQL权限级别 全局性的管理权限,作用于整个MySQL实例级别 数据库级别的权限,作用于某个指定的数据库上或者所有的数据库上 数据库对象级别的权限,作用于指定的数据库对象上 ...
- mysql存储过程详解
mysql存储过程详解 1. 存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的S ...
- mysql 存储过程详解 存储过程
mysql存储过程详解 1. 存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成 ...
- MySQL存储过程详解 mysql 存储过程
原文地址:MySQL存储过程详解 mysql 存储过程作者:王者佳暮 mysql存储过程详解 1. 存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储 ...
- Mysql Explain 详解
Mysql Explain 详解[强烈推荐] Mysql Explain 详解一.语法explain < table_name >例如: explain select * from t3 ...
- MySQL存储过程详解 mysql 存储过程(二)
mysql存储过程详解 1. 存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL ...
- MySQL 操作详解
MySQL 操作详解 一.实验简介 本节实验中学习并实践 MySQL 上创建数据库.创建表.查找信息等详细的语法及参数使用方法. 二.创建并使用数据库 1. 创建并选择数据库 使用SHOW语句找出服务 ...
随机推荐
- study Python3 【1】
用VSCode来编辑Python代码,作为IDE使用,有点头晕. https://www.runoob.com/python3/python-vscode-setup.html有介绍.还有更好的博客介 ...
- FastAPI中Pydantic异步分布式唯一性校验
title: FastAPI中Pydantic异步分布式唯一性校验 date: 2025/04/02 00:47:55 updated: 2025/04/02 00:47:55 author: cmd ...
- Codeforces Round 944 (Div. 4)
知识点模块 1. ai xor aj<=4 意味着两个数字的二进制位,只能有后两位的二进制位不同,因为如果第三位二进制位不同,就会出现异或的结果大于4 2.要有化曲为直的思想 学会把曲线上的坐标 ...
- FastMCP实践开发应用
一.概述 FastMCP是一个基于Python的高级框架,用于构建MCP(Model Context Protocol)服务器.它能够帮助开发者以最小的代码量创建MCP服务器,从而让AI助手能够更好地 ...
- MacOS v15.X安装HP旧款打印机驱动(P1606dn为例)
一.下载官方驱动 先去官网下载一下HP提供的Mac下的驱动合集(图1),可惜的只支持15.0以下版本安装. https://support.hp.com/cn-zh/drivers/hp-laserj ...
- Java--通过jdbc访问mysql数据库(mysql v8.0.11)
由于mysql的更新,原来的连接数据库方法改变了 参考:http://www.cnblogs.com/rainbow70626/p/9005852.html package demo; import ...
- 代码随想录第十七天 | Leecode 654. 最大二叉树、617. 合并二叉树、700. 二叉搜索树中的搜索、98. 验证二叉搜索树
Leecode 654. 最大二叉树 题目描述 给定一个不重复的整数数组 nums . 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值. 递归地在 ...
- MySQL 8.0 修改密码 新建用的正确方式
mysql 更新完密码,总是拒绝连接.登录失败?MySQL8.0 不能通过直接修改 mysql.user 表来更改密码.正确更改密码的方式备注: 清空root密码MySQL8.0 不能通过直接修改 m ...
- django笔记补充
安装 pip install django环境变量: C:\Program Files\Anaconda3\Scriptsdjango-admin startproject mysite 创建djan ...
- Nginx No, Traefik Yes
As we all know, Nginx is a very popular reverse proxy server. It is very stable and has a lot of fea ...