基于AST实现国际化文本提取
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:霜序
前言
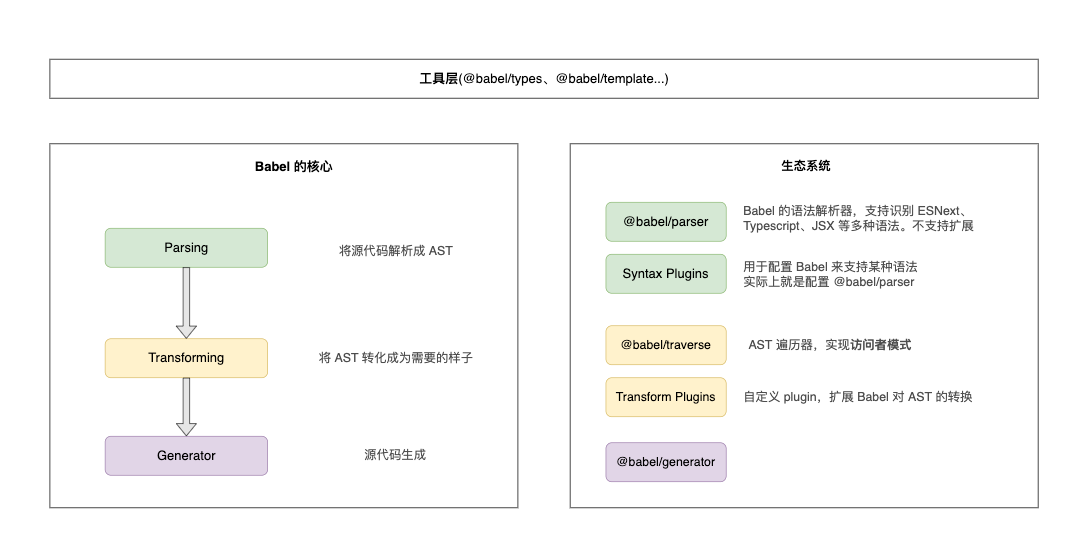
在阅读本文之前,需要读者有一些 babel 的基础知识,babel 的架构图如下:
确定中文范围
先需要明确项目中可能存在中文的情况有哪些?
const a = '霜序';
const b = `霜序`;
const c = `${isBoolean} ? "霜序" : "FBB"`;
const obj = { a: '霜序' };
// enum Status {
// Todo = "未完成",
// Complete = "完成"
// }
// enum Status {
// "未完成",
// "完成"
// }
const dom = <div>霜序</div>;
const dom1 = <Customer name="霜序" />;
虽然有很多情况下会出现中文,在代码中存在的时候大部分是string或者模版字符串,在react中的时候一个是dom的子节点还是一种是props上的属性包含中文。
// const a = '霜序';
{
"type": "StringLiteral",
"start": 10,
"end": 14,
"extra": {
"rawValue": "霜序",
"raw": "'霜序'"
},
"value": "霜序"
}
StringLiteral
对应的AST节点为StringLiteral,需要去遍历所有的StringLiteral节点,将当前的节点替换为我们需要的I18N.key这种节点。
// const b = `${finalRoles}(质量项目:${projects})`
{
"type": "TemplateLiteral",
"start": 10,
"end": 43,
"expressions": [
{
"type": "Identifier",
"start": 13,
"end": 23,
"name": "finalRoles"
},
{
"type": "Identifier",
"start": 32,
"end": 40,
"name": "projects"
}
],
"quasis": [
{
"type": "TemplateElement",
"start": 11,
"end": 11,
"value": {
"raw": "",
"cooked": ""
}
},
{
"type": "TemplateElement",
"start": 24,
"end": 30,
"value": {
"raw": "(质量项目:",
"cooked": "(质量项目:"
}
},
{
"type": "TemplateElement",
"start": 41,
"end": 42,
"value": {
"raw": ")",
"cooked": ")"
}
}
]
}
TemplateLiteral
相对于字符串情况会复杂一些,TemplateLiteral中会出现变量的情况,能够看到在TemplateLiteral节点中存在expressions和quasis两个字段分别表示变量和字符串
其实可以发现对于字符串来说全部都在TemplateElement节点上,那么是否可以直接遍历所有的TemplateElement节点,和StringLiteral一样。
直接遍历TemplateElement的时候,处理之后的效果如下:
const b = `${finalRoles}(质量项目:${projects})`;
const b = `${finalRoles}${I18N.K}${projects})`;
// I18N.K = "(质量项目:"
那么这种只提取中文不管变量的情况,会导致翻译不到的问题,上下文很缺失。
最后我们会处理成{val1}(质量项目:{val2})的情况,将对应val1和val2传入
I18N.get(I18N.K, {
val1: finalRoles,
val2: projects,
});
JSXText
对应的AST节点为JSXText,去遍历JSXElement节点,在遍历对应的children中的JSXText处理中文文本
{
"type": "JSXElement",
"start": 12,
"end": 25,
"children": [
{
"type": "JSXText",
"start": 17,
"end": 19,
"extra": {
"rawValue": "霜序",
"raw": "霜序"
},
"value": "霜序"
}
]
}
JSXAttribute
对应的AST节点为JSXAttribute,中文存在的节点还是StringLiteral,但是在处理的时候还是特殊处理JSXAttribute中的StringLiteral,因为对于这种JSX中的数据来说我们需要包裹{},不是直接做文本替换的
{
"type": "JSXOpeningElement",
"start": 13,
"end": 35,
"name": {
"type": "JSXIdentifier",
"start": 14,
"end": 22,
"name": "Customer"
},
"attributes": [
{
"type": "JSXAttribute",
"start": 23,
"end": 32,
"name": {
"type": "JSXIdentifier",
"start": 23,
"end": 27,
"name": "name"
},
"value": {
"type": "StringLiteral",
"start": 28,
"end": 32,
"extra": {
"rawValue": "霜序",
"raw": "\"霜序\""
},
"value": "霜序"
}
}
],
"selfClosing": true
}
使用 Babel 处理
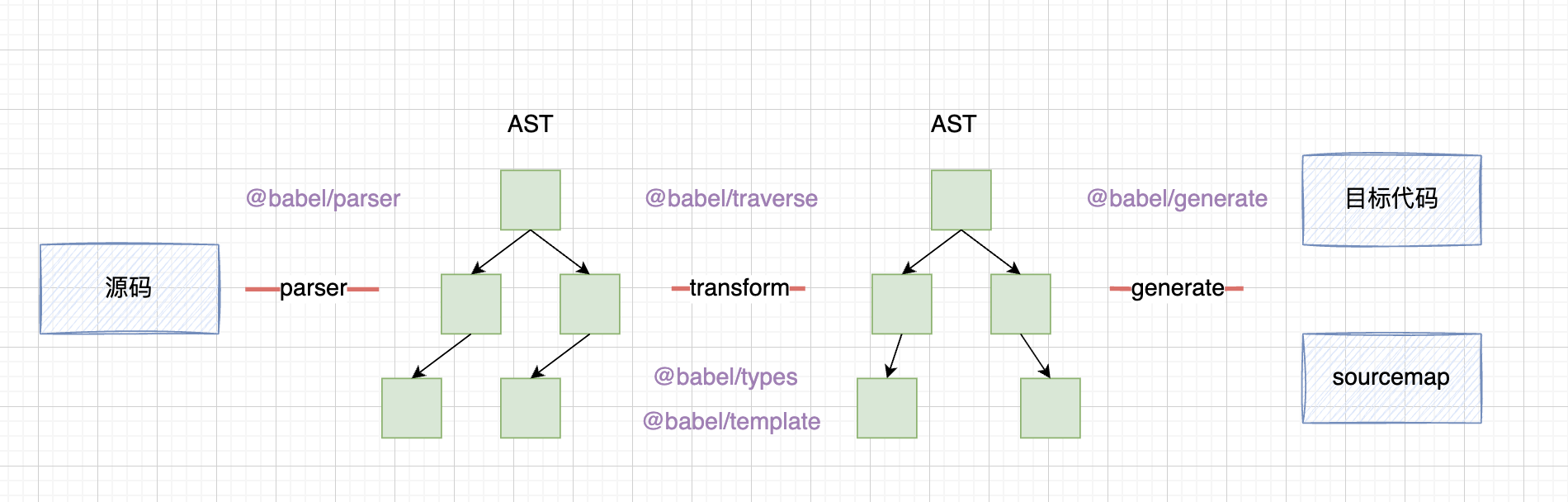
使用 @babel/parser 将源代码转译为 AST
const plugins: ParserOptions['plugins'] = ['decorators-legacy', 'typescript'];
if (fileName.endsWith('text') || fileName.endsWith('text')) {
plugins.push('text');
}
const ast = parse(sourceCode, {
sourceType: 'module',
plugins,
});
@babel/traverse 特殊处理上述的节点,转化 AST
babelTraverse(ast, {
StringLiteral(path) {
const { node } = path;
const { value } = node;
if (
!value.match(DOUBLE_BYTE_REGEX) ||
(path.parentPath.node.type === 'CallExpression' &&
path.parentPath.toString().includes('console'))
) {
return;
}
path.replaceWithMultiple(template.ast(`I18N.${key}`));
},
TemplateLiteral(path) {
const { node } = path;
const { start, end } = node;
if (!start || !end) return;
let templateContent = sourceCode.slice(start + 1, end - 1);
if (
!templateContent.match(DOUBLE_BYTE_REGEX) ||
(path.parentPath.node.type === 'CallExpression' &&
path.parentPath.toString().includes('console')) ||
path.parentPath.node.type === 'TaggedTemplateExpression'
) {
return;
}
if (!node.expressions.length) {
path.replaceWithMultiple(template.ast(`I18N.${key}`));
path.skip();
return;
}
const expressions = node.expressions.map((expression) => {
const { start, end } = expression;
if (!start || !end) return;
return sourceCode.slice(start, end);
});
const kvPair = expressions.map((expression, index) => {
templateContent = templateContent.replace(
`\${${expression}}`,
`{val${index + 1}}`,
);
return `val${index + 1}: ${expression}`;
});
path.replaceWithMultiple(
template.ast(`I18N.get(I18N.${key},{${kvPair.join(',\n')}})`),
);
},
JSXElement(path) {
const children = path.node.children;
const newChild = children.map((child) => {
if (babelTypes.isJSXText(child)) {
const { value } = child;
if (value.match(DOUBLE_BYTE_REGEX)) {
const newExpression = babelTypes.jsxExpressionContainer(
babelTypes.identifier(`I18N.${key}`),
);
return newExpression;
}
}
return child;
});
path.node.children = newChild;
},
JSXAttribute(path) {
const { node } = path;
if (
babelTypes.isStringLiteral(node.value) &&
node.value.value.match(DOUBLE_BYTE_REGEX)
) {
const expression = babelTypes.jsxExpressionContainer(
babelTypes.memberExpression(
babelTypes.identifier('I18N'),
babelTypes.identifier(`${key}`),
),
);
node.value = expression;
}
},
});
对于TemplateLiteral来说需要处理expression,通过截取的方式获取到对应的模版字符串 templateContent,如果不存在expressions,直接类似StringLiteral处理;存在expressions的情况下,遍历expressions通过${val(index)}替换掉templateContent中的expression,最后使用I18N.get的方式获取对应的值
const name = `${a}霜序`;
// const name = I18N.get(I18N.test.A, { val1: a });
const name1 = `${a ? '霜' : '序'}霜序`;
// const name1 = I18N.get(I18N.test.B, { val1: a ? I18N.test.C : I18N.test.D });
对于TemplateLiteral节点来说,如果是嵌套的情况,会出现问题。
const name1 = `${a ? `霜` : `序`}霜序`;
// const name1 = I18N.get(I18N.test.B, { val1: a ? `霜` : `序` });
为何对于
TemplateLiteral中嵌套的StringLiteral会处理,而TemplateLiteral就不处理呢?
导致原因为babel不会自动递归处理TemplateLiteral的子级嵌套模板。
上述的代码中通过遍历一些AST处理完了之后,我们需要统一引入当前I18N这个变量。那么没我们需要在当前文件的AST顶部的import语句后插入当前的importStatement
Program: {
exit(path) {
const importStatement = projectConfig.importStatement;
const result = importStatement
.replace(/^import\s+|\s+from\s+/g, ',')
.split(',')
.filter(Boolean);
// 判断当前的文件中是否存在 importStatement 语句
const existingImport = path.node.body.find((node) => {
return (
babelTypes.isImportDeclaration(node) &&
node.source.value === result[1]
);
});
if (!existingImport) {
const importDeclaration = babelTypes.importDeclaration(
[
babelTypes.importDefaultSpecifier(
babelTypes.identifier(result[0]),
),
],
babelTypes.stringLiteral(result[1]),
);
path.node.body.unshift(importDeclaration);
}
},
}
转为代码
const { code } = generate(ast, {
retainLines: true,
comments: true,
});
因为我们的场景不适合将该功能封装成plugin,但是整体和写plugin的思路差不多。在.babelrc中配置对应的plugin即可
const i18nPlugin = () => {
return {
visitor: {
StringLiteral(path) {},
TemplateLiteral(path) {},
JSXElement(path) {},
JSXAttribute(path) {},
Program: {},
},
};
};
其他处理
动态生成 key
每一个中文生成key的方式都是固定的,类似excel列名
export const getSortKey = (n: number, extractMap = {}): string => {
let label = '';
let num = n;
while (num > 0) {
num--;
label = String.fromCharCode((num % 26) + 65) + label;
num = Math.floor(num / 26);
}
const key = `${label}`;
if (_.get(extractMap, key)) {
return getSortKey(n + 1, extractMap);
}
return key;
};
每一个文件的前缀都是一定的,按着路径生成的,不会包含extractDir之前的内容
export const getFileKey = (filePath: string) => {
const extractDir = getProjectConfig().extractDir;
const basePath = path.resolve(process.cwd(), extractDir);
const relativePath = path.relative(basePath, filePath);
const names = slash(relativePath).split('/');
const fileName = _.last(names) as any;
let fileKey = fileName.split('.').slice(0, -1).join('.');
const dir = names.slice(0, -1).join('.');
if (dir) fileKey = names.slice(0, -1).concat(fileKey).join('.');
return fileKey.replace(/-/g, '_');
};
脚手架命令
目前支持命令如下:
- init: 用于初始化配置化文件
- extract: 根据配置文件提取 extractDir 的中文写入到对应的文件
- extract:check: 检查 extractDir 文件夹中的中文是否提取完全
- extract:clear: 清理 extractDir 尚未使用的国际化文案
npx i18n-extract-cli init
会初始化一份i18n.config.json
{
"localeDir": "locales",
"extractDir": "./",
"importStatement": "import I18N from @/utils/i18n",
"excludeFile": [],
"excludeDir": []
}
执行如下命令,开始提取extractDir目录下的中文文本到localeDir/zh-CN
npx i18n-extract-cli extract
执行如下命令,检查 extractDir 文件夹中的中文是否提取完全,需要注意 console 中的中文也会被检查
npx i18n-extract-cli extract:check
执行如下命令,清理 extractDir 尚未使用的国际化文案
值得注意,是按着每个文件路径作为key来判断当前文件中的 sortKey 是否使用,因此必须保证每个文件中使用的 key 为fileKey + sortKey,否则会导致当前脚本失效
npx i18n-extract-cli extract:clear
最后
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
- 大数据分布式任务调度系统——Taier
- 轻量级的 Web IDE UI 框架——Molecule
- 针对大数据领域的 SQL Parser 项目——dt-sql-parser
- 袋鼠云数栈前端团队代码评审工程实践文档——code-review-practices
- 一个速度更快、配置更灵活、使用更简单的模块打包器——ko
- 一个针对 antd 的组件测试工具库——ant-design-testing
基于AST实现国际化文本提取的更多相关文章
- 基于 Python 的自动文本提取:抽象法和生成法的比较
我们将现有的 提取方法(Extractive)(如LexRank,LSA,Luhn和Gensim现有的TextRank摘要模块)与含有51个文章摘要对的Opinosis数据集进行比较.我们还尝试使用T ...
- springmvc国际化 基于请求的国际化配置
springmvc国际化 基于请求的国际化配置 基于请求的国际化配置是指,在当前请求内,国际化配置生效,否则自动以浏览器为主. 项目结构图: 说明:properties文件中为国际化资源文件.格式相关 ...
- 基于TF-IDF的新闻标签提取
基于TF-IDF的新闻标签提取 1. 新闻标签 新闻标签是一条新闻的关键字,可以由编辑上传,或者通过机器提取.新闻标签的提取主要用于推荐系统中,所以,提取的准确性影响推荐系统的有效性.同时,对于将标签 ...
- lucene索引查看工具luke和文本提取工具Tika
luke可以方便的查看lucene的索引信息,当然也可以查看solr和es中的索引信息(基于lucene实现). 查看索引前,要注意lucene版本的问题,高版本的lucene用低版本的luke工具就 ...
- Attention-based Extraction of Structured Information from Street View Imagery:基于注意力的街景图像提取结构化信息
基于注意力的街景图像提取结构化信息 一种用于真实图像文本提取问题的TensorFlow模型. 该文件夹包含在FSNS数据集数据集上训练新的注意OCR模型所需的代码,以在法国转录街道名称. 您还可以使用 ...
- Arctext.js - 基于 CSS3 & jQuery 的文本弯曲效果
Arctext.js 是基于 Lettering.js 的文本旋转插件,根据设置的旋转半径准确计算每个字母的旋转弧度并均匀分布.虽然 CSS3 也能够实现字符旋转效果,但是要让安排每个字母都沿着弯曲路 ...
- 推荐20款基于 jQuery & CSS 的文本效果插件
jQuery 和 CSS 可以说是设计和开发行业的一次革命.这一切如此简单,快捷的一站式服务.jQuery 允许你在你的网页中添加一些真正令人惊叹的东西而不用付出很大的努力,要感谢那些优秀的 jQue ...
- POI教程之第二讲:创建一个时间格式的单元格,处理不同内容格式的单元格,遍历工作簿的行和列并获取单元格内容,文本提取
第二讲 1.创建一个时间格式的单元格 Workbook wb=new HSSFWorkbook(); // 定义一个新的工作簿 Sheet sheet=wb.createSheet("第一个 ...
- MiniGUI文档参考手册 基于v1.6.10文本
MiniGUI各种功能都分布在预先定义宏对每个文档标题.特别不方便查找,这是不利于初学者学习. 有一天,我发现doxygen,因此,使用该工具可以生成一个minigui参考文献 .基于v1.6.10文 ...
- R+OCR︱借助tesseract包实现图片文本提取功能
2016年11月,Jeroen Ooms在CRAN发布了tesseract包,实现了R语言对简单图片的文本提取.分析功能. 利用开源OCR引擎进行图片处理,目前可以识别超过100种语言,R语言可以借助 ...
随机推荐
- docker没有vi不能执行yum报Device or resource busy
最近在使用docker的过程中发现一个问题,就是想用vim编辑器编辑一个文件,发现连vi都没有. 于是想到一个办法用docker cp来解决问题: 首先执行docker ps -a查看容器的id 然后 ...
- HElib
什么是HElib? HElib是一个基于C++语言的同态加密开源软件库,底层依赖于NTL数论运算库和GMP多精度运算库实现,主要开发者为IBM的Halevi,目前最新版本为1.0.2,实现了支持&qu ...
- Java中的Scanner、BufferedReader 和 StreamTokenizer
1. Scanner 的使用与分析 简介: Scanner 是 Java 中一个用于解析原始类型(如 int.double 等)和字符串的类.它通常从输入流中逐个读取数据并进行解析,支持多种分隔符的使 ...
- 提升质量:利用Coverage分析Python Web项目的测试覆盖
提升质量:利用Coverage分析Python Web项目的测试覆盖 鉴于不同框架的运行机制各有差异,当利用Coverage工具对Python Web项目的测试覆盖率进行分析时,必须采取针对性的方法来 ...
- Nmap 语法及示例
Nmap 语法及示例 基本语法 Nmap的基本语法结构如下: nmap [scan types] [options] [target] [scan types]: 标识扫描类型,如:TCP.UDP等. ...
- Netty实战:Netty优雅的创建高性能TCP服务器(附源码)
文章目录 前言 1. 前置准备 2. 消息处理器 3. 重写通道初始化类 4. 核心服务 5. 效果预览 6. 添加通道管理,给指定的客户端发送消息 7. 源码分享 前言 Springboot使用Ne ...
- @Scheduled参数及cron表达式解释
@Scheduled支持以下8个参数:1.cron:表达式,指定任务在特定时间执行:2.fixedDelay:表示上一次任务执行完成后多久再次执行,参数类型为long,单位ms:3.fixedDela ...
- 如何让N1盒子、机顶盒开机从优盘启动进入刷机流程
疑难解答加微信机器人,给它发:进群,会拉你进入八米交流群 机器人微信号:bamibot 简洁版教程访问:https://bbs.8miyun.cn 准备阶段 1.下载我的从优盘启动的工具包 2.确认你 ...
- Spark - [04] RDD编程
题记部分 一.RDD编程模型 在 Spark 中,RDD 被表示为对象,通过对象上的方法调用来对 RDD 进行转换.经过一系列的 transformations 定义 RDD 之后,就可以调用 a ...
- 记录:tinyrenderer
Bresenham's line drawing(布雷森汉姆算法) 进行games101的光栅化作业时,对其渲染原理仍不甚了解,找到tinyrenderer软光栅项目.在此记录下试错的过程. 作者在最 ...