数据库自增 ID 用完了会怎么样?
前言
数据库中的自增 ID 用完了该怎么办?
这个问题可以分为有主键 & 无主键两种情况回答。
有主键
如果你的表有主键,并且把主键设置为自增。
在 MySQL 中,一般会把主键设置成 int 型。而 MySQL 中 int 型占用 4 个字节,作为有符号位的话范围就是 [-2^31, 2^31-1],也就是[-2147483648,2147483647];无符号位的话最大值就是 2^32-1,也就是 4294967295。
下面以有符号位创建一张表:
CREATE TABLE IF NOT EXISTS `t`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`url` VARCHAR(64) NOT NULL,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入一个 id 为最大值 2147483647 的值,如下图所示:
INSERT INTO t (id, url) VALUES (2147483647, 'https://www.cnblogs.com/niuben/')
如果此时继续下面的插入语句:
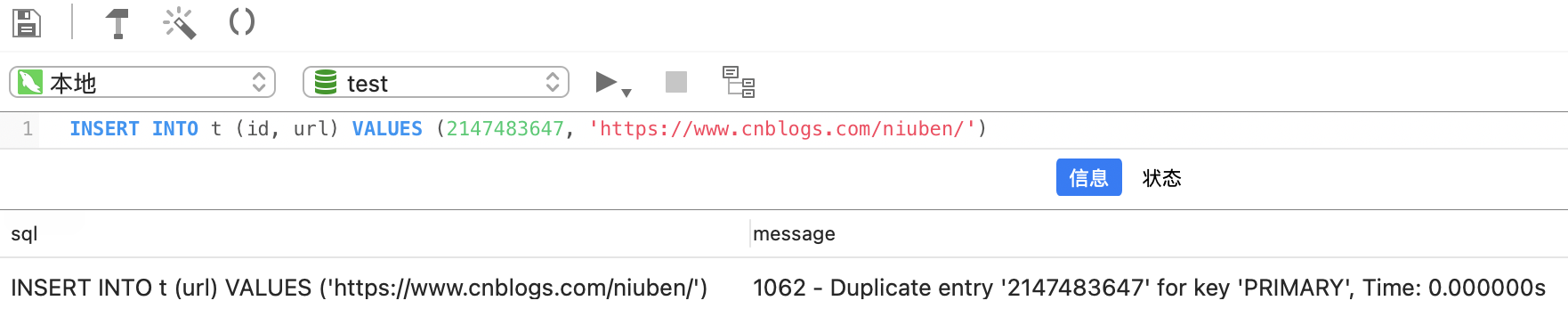
INSERT INTO t (url) VALUES ('https://www.cnblogs.com/niuben/')
结果就会造成主键冲突:
解决方案
mysql int 4 个字节,最大数据量能存储 21 亿。你可能会觉得这么大的容量,应该不至于用完。但是互联网时代,每天都产生大量的数据,这是很有可能达到的。
所以,我们的解决方案是:把主键类型改为 bigint,也就是 8 个字节。这样能存储的最大数据量就是 2^64-1, 这下自增主键不会不够用了。
单表 21 亿的数据量显然不现实,一般来说数据量达到 500 万就该分表了。
没主键
另一种情况就是建表时没设置主键。这种情况,InnoDB 会自动帮你创建一个不可见的、长度为 6 字节的 row_id,默认是无符号的,所以最大长度是 2^48-1。
实际上 InnoDB 维护了一个全局的 dictsys.row_id,所以未定义主键的表都共享该 row_id,并不是单表独享。每次插入一条数据,都把全局 row_id 当成主键 id,然后全局 row_id 加 1。
这种情况的数据库自增 ID 用完会发生什么呢?
结论:当 row_id 达到最大值后会从 0 重新开始算;前面插入的数据就会被后插入的数据覆盖,且不会报错。
总结
数据库自增主键用完后分两种情况:
- 有主键,报主键冲突
- 无主键,InnDB 会自动生成一个全局的row_id。它到达最大值后会从 0 开始算,遇到 row_id 一样时,新数据覆盖旧数据。所以,我们还是尽量给表设置主键。
数据库自增 ID 用完了会怎么样?的更多相关文章
- 面试官:数据库自增ID用完了会怎么样?
看到这个问题,我想起当初玩魔兽世界的时候,25H难度的脑残吼的血量已经超过了21亿,所以那时候副本的BOSS都设计成了转阶段.回血的模式,因为魔兽的血量是int型,不能超过2^32大小. 估计暴雪的设 ...
- mysql 数据库自增id 的总结
有一个表StuInfo,里面只有两列 StuID,StuName其中StuID是int型,主键,自增列.现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,Stu ...
- 解决数据库自增ID的问题
(1)设置主键自增为何不可取这样的话,数据库本身是单点,不可拆库,因为id会重复. (2)依赖数据库自增机制达到全局ID唯一使用如下语句:REPLACE INTO Tickets64 (stub) V ...
- 分布式ID系列(3)——数据库自增ID机制适合做分布式ID吗
数据库自增ID机制原理介绍 在分布式里面,数据库的自增ID机制的主要原理是:数据库自增ID和mysql数据库的replace_into()函数实现的.这里的replace数据库自增ID和mysql数据 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
- mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0
mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0 #将数据库表自增ID批量清零 SELECT CONCAT( 'ALTER TABLE ', TABLE_NAME, ' AUT ...
- MySQL 的自增 ID 用完了,怎么办?
一.简述 在 MySQL 中用很多类型的自增 ID,每个自增 ID 都设置了初始值.一般情况下初始值都是从 0 开始,然后按照一定的步长增加.在 MySQL 中只要定义了这个数的字节长度,那么就会 ...
- mybatis获取数据库自增id
http://blog.csdn.net/dyllove98/article/details/8866357 http://www.iteye.com/problems/86864 insert标签中 ...
- mysql数据库自增id重新从1排序的两种方法
mysql默认自增ID是从1开始了,但当我们如果有插入表或使用delete删除id之后ID就会不会从1开始了哦. 使用mysql时,通常表中会有一个自增的id字段,但当我们想将表中的数据清空重新添 ...
- MySQL的自增ID用完了,怎么办?
既然这块知识点不清楚,那回头就自己动手实践下. 首先,创建一个最简单的表,只包含一个自增id,并插入一条数据. create table t0(id int unsigned auto_increme ...
随机推荐
- Qt/C++动态启用地图功能/地图拖曳/键盘操作/滚轮缩放/双击放大/连续缩放等
一.前言说明 地图组件为了方便用户的操作,一般会满足各种需求场景,比如用鼠标拖曳地图,实体键盘按键上下左右移动,鼠标滚轮缩放地图大小,双击放大地图,这些常规的操作可以极大的方便用户操作,问题是,有时候 ...
- Qt/C++编写跨平台的推流工具(支持win/linux/mac/嵌入式linux/安卓等)
一.前言 跨平台的推流工具当属OBS最牛逼,功能也是最强大的,唯一的遗憾就是多路推流需要用到插件,而且CPU占用比较高,默认OBS的规则是将对应画布中的视频画面和设定的音频一起重新编码再推流,意味着肯 ...
- vue辅助函数mapState和mapGetter前面三个点到底是什么意思:对象展开运算符
import store from "./store" computed: { useName: function() { return store.state.userName ...
- [转]vue项目启动时,npm run serve 和 npm run dev 的区别
npm run serve 和 npm run dev 的区别 在我们运行一些 vue 项目的时候,输入npm run serve或者 npm run dev的其中一个时,系统会报错: PS C:\U ...
- DynamoDB-键值存储
什么是DynamoDB? DynamoDB 是一个你什么也不用管的 NoSql 数据库.记得给 AWS付账单就可以. 在2004年的时候, Amazon 发现 Oracle 数据库都不够用了.为了还能 ...
- 搭建个人AI知识库-DIFY
前提 本地目前没有显卡,只能用cpu刚. 如果不想自己搭建本地模型,完全可以掏钱使用现成的API即可. 需要了解一些docker知识 搭建本地模型 环境 os: archlinux 内存: 32g c ...
- 对rpc长连接与短连接的思考
大家好,我是思无邪,某go中厂开发工程师,也是OSPP2024的学生参与者! 如果你觉得我的文章有帮助,记得三连支持一下哦! 目前正在深入研究源码,与你们一起进步,共同攻克编程难关! 欢迎关注我的公众 ...
- flutter3-dymall仿抖音直播商城|Flutter3.27短视频+直播+聊天App实例
自研flutter3.27+dart3.6+getx实战抖音短视频+聊天+直播电商带货app商城应用. flutter_dymall一款基于最新版Flutter3.27+Dart3.x+Getx+me ...
- DBeaver出现“Public Key Retrieval is not allowed”错误的解决办法
1.问题描述 我们在使用DBeaver连接MySql的时候,可能会出现"Public Key Retrieval is not allowed"的错误提示,如下图所示: 2.解决办 ...
- lxl 讲课的记录
D1 lxl:LCT 没有前途.所以平衡树一般只需要 fhq-treap. 线段树.平衡树简单例题 P3215 注意到抵消掉合法括号串之后一定是这样的情况:))))((((即前缀最小值 \(a\).后 ...