基于人类反馈的强化学习 RLHF
1.强化学习和语言模型的联系
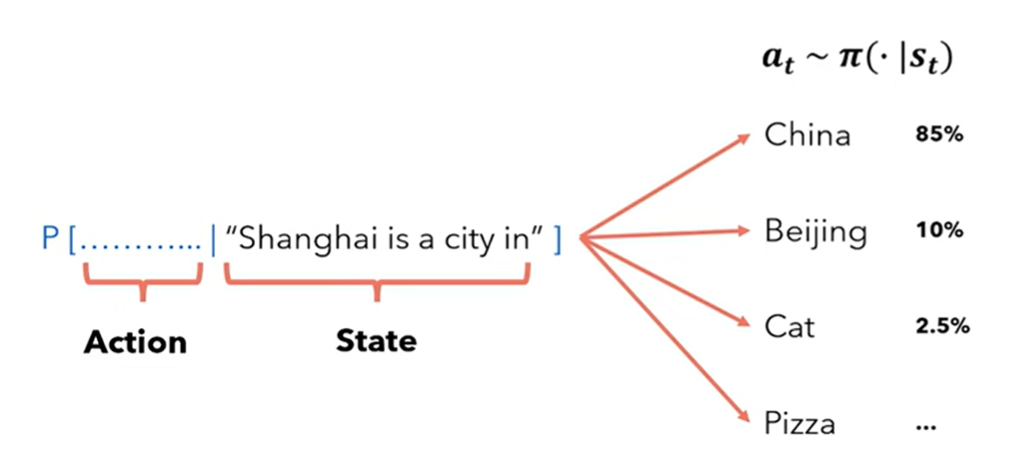
agent: 语言模型本身
state: prompt(input tokens)
action: 选择哪个token作为下一个token(贪婪,top k,top p)
reward model:当生成‘好的回复’语言模型应当被奖励,当生成‘差的回复’语言模型不会受到任何奖励
policy:语言模型本身,因为它对动作空间给出当前状态的概率进行建模:\({a_t} \sim \pi(·|S_t)\)

2. 语言模型的奖励模型
人类不擅长达成一致,但是我们很擅长比较
2.1 数据集

2.2 奖励模型架构
2.3 奖励模型损失
为了借助强化学习优化我们的语言模型表现,我们需要一个打分模型,对语言模型生成的每个回复给予一个数值。
现在我们有一个定义了基于一个query(prompt)下更喜欢的answer的数据集,我们可以搭建一个神经网络,使之可以对每一个response生成一个数字分数。

\]
good answer : \(r(x,y_w)\)
bad answer : \(r(x,y_l)\)
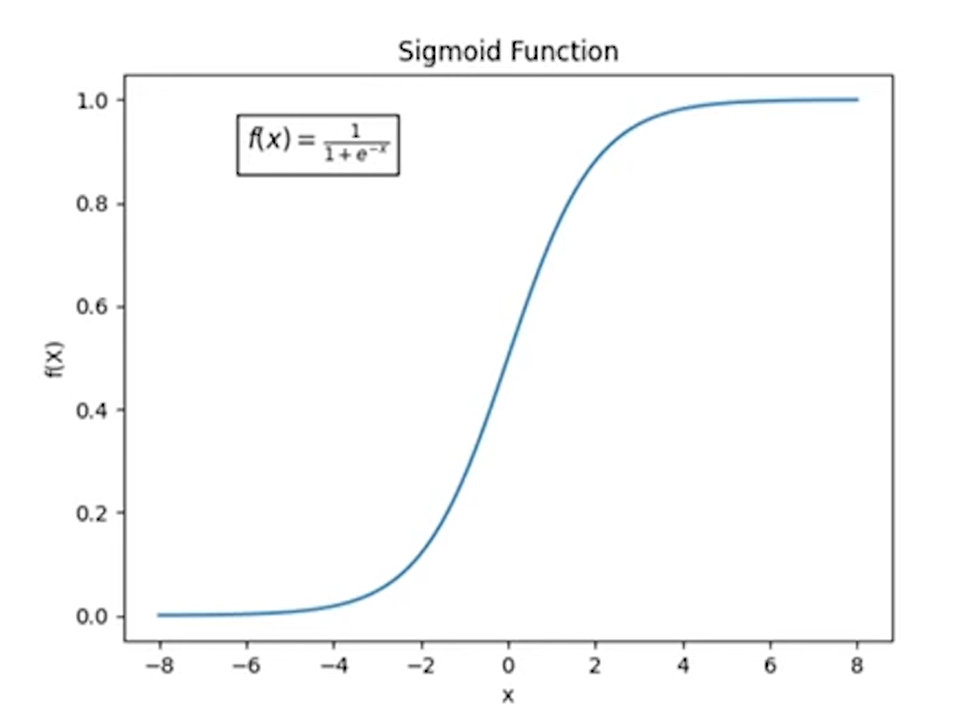
如果 \(r(x,y_w)\) > \(r(x,y_l)\) -> sigmoid会返回一个value > 0.5 -> loss会很小
·如果顺序正确,loss会很小
如果 \(r(x,y_w)\) < \(r(x,y_l)\) -> sigmoid会返回一个value < 0.5 -> loss会很大
·如果顺序错误,loss会很大
Note:
sigmoid函数:
2.4 具体实现
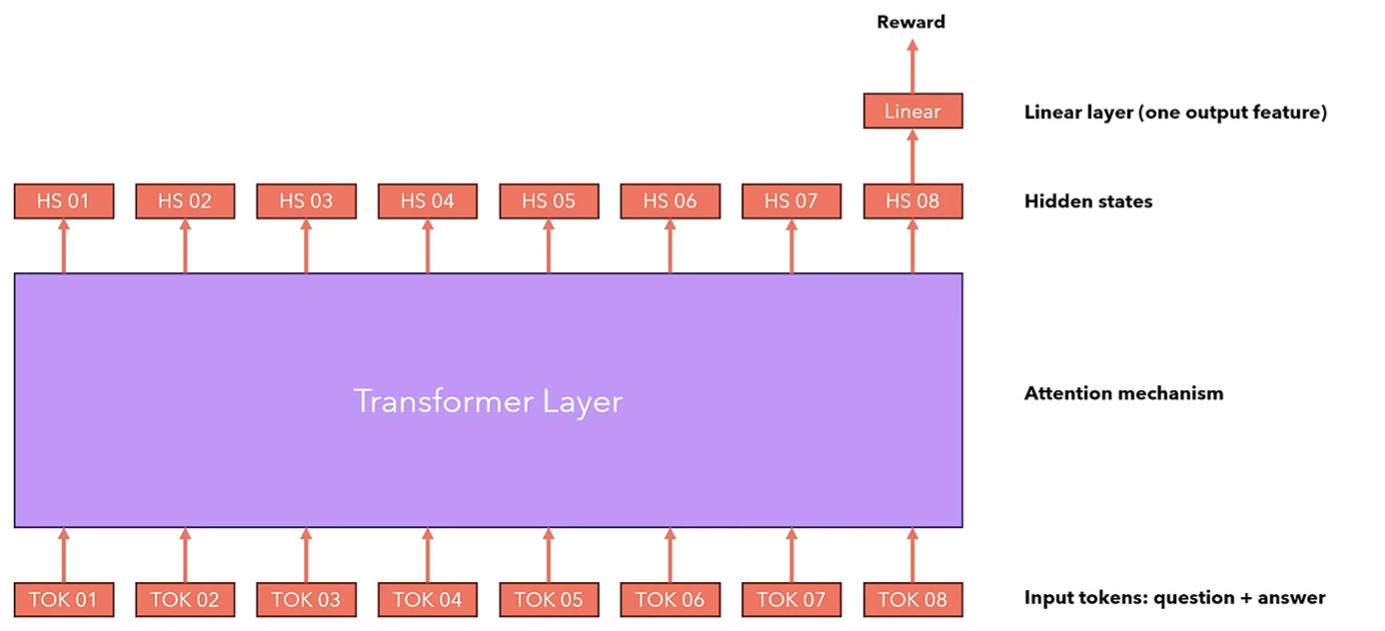
在HuggingFace, 我们可以通过使用RewardTrainer和AutoModelForSequenceClassification训练一个custom reward模型,即拥有一个特殊先行层在顶部的语言模型。
我们只需要要求语言模型输出最后一个token的隐藏层,然后输入进线性层计算奖励,然后根据之前所说的Loss训练模型。
def compute_loss(
self,
model: Union[PreTrainedModel, nn.Module],
inputs: dict[str, Union[torch.Tensor, Any]],
return_outputs=False,
num_items_in_batch=None,
) -> Union[torch.Tensor, tuple[torch.Tensor, dict[str, torch.Tensor]]]:
rewards_chosen = model(
input_ids=inputs["input_ids_chosen"],
attention_mask=inputs["attention_mask_chosen"],
return_dict=True,
)["logits"]
rewards_rejected = model(
input_ids=inputs["input_ids_rejected"],
attention_mask=inputs["attention_mask_rejected"],
return_dict=True,
)["logits"]
# calculate loss, optionally modulate with margin
if "margin" in inputs:
loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected - inputs["margin"]).mean()
else:
loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean()
if self.args.center_rewards_coefficient is not None:
loss += self.args.center_rewards_coefficient * torch.mean((rewards_chosen + rewards_rejected) ** 2)
if return_outputs:
return loss, {
"rewards_chosen": rewards_chosen,
"rewards_rejected": rewards_rejected,
}
return loss
3. 策略 Policy
3.1 强化学习中的轨迹
我们之前说过,强化学习的目标是选择一个policy,当agent根据这个策略行动可以最大化返回的期望值。
\]
策略的期望值,就是所有可能轨迹(trajectories)期望值之和:
\]
轨迹是从初始state开始的一系列(action, state):
\]
我们把下一个状态视作随机的并进行建模:
\]
因此我们可以用下面的公式定义轨迹·:
\]
我们通常倾向于使用折扣奖励(因为我们喜欢及时奖励而不是长远奖励):
\]
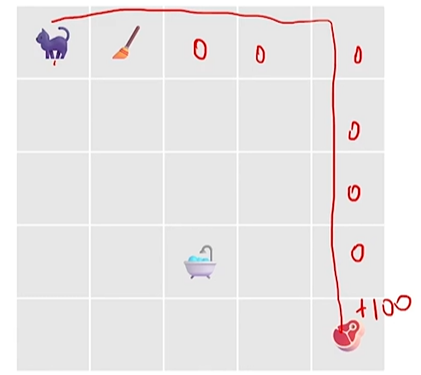
Note: \(0<\gamma < 1\)
如下如所示,计算的时候应该是 \(R(\tau) = \gamma^{1} * (-1) + 0 +...+ \gamma^{8} * (100)
\)
3.2 语言模型下的轨迹
当我们处理的是一个语言模型时,我们希望能微调语言模型使之以获取最大reward的路径选择下一个token:
\]
轨迹是从一系列prompts(state) 和他们下一个token(action)
\]

目标:策略的期望最大
也就是:训练一个policy神经网络\(\pi\),在所有状态S下,给出相应的Action,得到的Return期望最大
也就是:训练一个policy神经网络\(\pi\),在所有的Trajectory中,得到的Return期望最大
3.3 使用策略梯度优化训练一个policy网络
\]
当我们提到深度神经网络,我们的目标是迭代地改变神经网络的参数来最小化损失函数的值,这是典型随机梯度下降的用法,但是在我们的案例中,我们希望最大化这函数,因此我们使用随机梯度上升:
\]
策略的梯度叫做 policy gradient, 优化这种策略的算法叫做policy gradient algorithms.
现在的问题就是,如何计算梯度,我们需要考虑所有可能的轨迹,这在计算上是不可行的,因为这是一种computationally intractable问题,除非我们有一个很小的state space。
a. 梯度表达式:
\]
\(R(\tau)\):一条轨迹 的总回报。
\(\tau \sim \pi_\theta\):轨迹是从策略\(\pi_\theta\)中采样得到的。
b. 期望扩展为积分(连续就是积分,离散就是求和):
= \nabla_\theta \int_\tau P(\tau|\theta) R(\tau) d \tau
\]
c. 将梯度移到积分内部(换序积分定理(也称为微分与积分的交换定理)):
\]
d. 引入对数导数技巧(log-derivative trick):
\]
代入后,得到:
\]
e. 返回期望形式:
\]
f. 分解轨迹的概率:
\]
Note:环境的动态模型(状态转移概率)与策略参数无关,所以对 \(\theta\) 求导只作用在策略上。
如下所示,等式两边同时加上log:
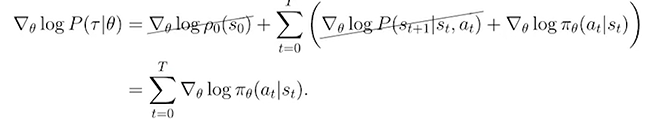
g. 最终公式(策略梯度):
\]
\(R(\tau)\):轨迹的总回报。
\(\log \pi_\theta(a_t|s_t)\):每个时间步策略的对数概率。
对于这个期望值,我们可以通过对收集到的一组轨迹(也就是一系列行动的记录)进行采样平均来近似这个期望值。
换句话说,我们通过观察和记录多个回合的行动,然后计算这些记录的平均值,来估计这个期望值。
\]
RECAP:截至目前,我们学会了什么?
目标:通过梯度方法优化策略的参数 ,以最大化预期奖励。
算法步骤:
a. 创建策略网络:
使用一个神经网络定义策略\(\pi_\theta\),输入为当前状态\(s_t\),输出为在动作空间上的概率分布\(\pi_\theta(a_t|s_t)\)。
b. 采样轨迹:
使用策略\(\pi_\theta\)来与环境交互,生成轨迹(包括状态\(s_t\)、动作\(a_t\)、奖励\(R(\tau)\))。通常每条轨迹可以运行固定步数(如 100 步)或直到达到终止条件。
c. 计算梯度:
根据公式:
\]
d. 更新策略参数:
使用随机梯度上升更新参数:
\]
e. 循环迭代:
返回第 b 步,继续采样新的轨迹并重复以上步骤,直到收敛。
4. 为语言模型生成轨迹
还记得我们为reward model建立的偏好数据集吗?我们使用这些问题询问模型以生成回答。然后我们计算生成回答的reward,并根据估计的策略梯度训练模型。

如何计算语言模型的策略log probabilities

计算每个轨迹的reward
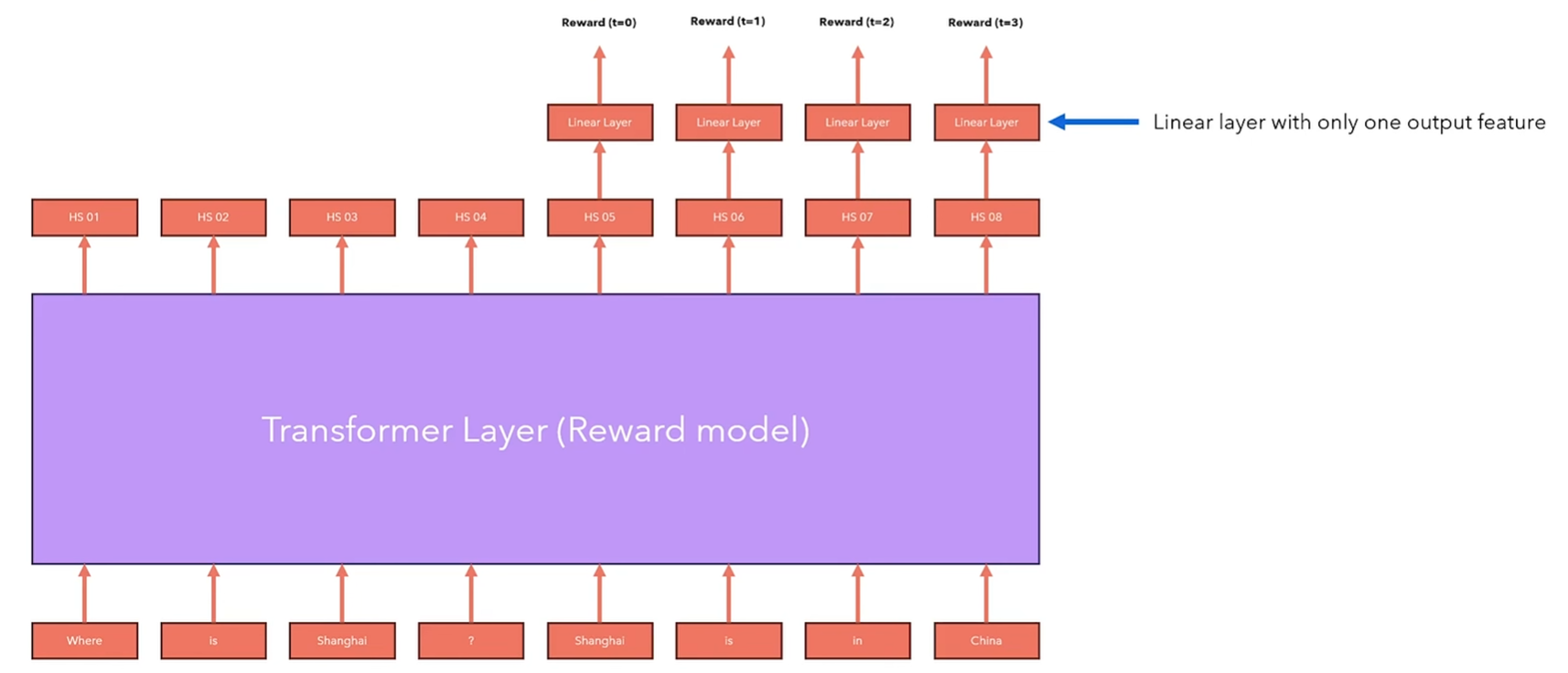
4.1 策略梯度优化GPO存在的问题
问题:
梯度估计是无偏的(unbiased)(意思是他可以收敛到真实的梯度),但是它具有很高的方差(varience)
解决:
方法一 : 采用 "rewards to go"(剩余奖励)来替代整条轨迹上的累积奖励
\(R(τ)\)
核心思想:you can't alter the past
a. 原始梯度公式
最初的梯度公式:
\]
- 问题:公式将整个轨迹的累积奖励 $ R(\tau)$与所有时间步的梯度相乘。
- 结果:由于 \(R(\tau)\)包含了从 \(t=0\)到\(T\)的所有奖励,梯度的方差非常高,尤其是在奖励稀疏或延迟时。
b. 改进:按时间步分解奖励
将公式重写为:
\]
- 每个动作梯度乘以整条轨迹的奖励总和。
- 发现的问题:对于一个具体时间步 ( t ),轨迹中之前的奖励(即 ( t'<t ) 的奖励)对当前动作无关紧要,却仍然被考虑进了公式(因为过去已经无法改变)。
c. 引入 “rewards to go”
为了减少方差,使用 "rewards to go" \(\sum_{t'=t}^{T} r(s_{i,t'}, a_{i,t'})\) 来替换原始的轨迹总奖励\(R(\tau)\)。改写后的公式为:
\]
- 解释:
- 对于每个时间步 $ t$,只计算从当前时间步到轨迹结束的累积奖励。
- 忽略过去的奖励,因为它们在期望中会相互抵消,不影响最终梯度的无偏性。
d. 减少方差的原因
- 原始公式中,过去的奖励\(t' < t\)对当前动作梯度没有直接影响,但由于被包含进公式中,会引入额外的噪声(方差)。
- 改用 "rewards to go" 后,公式更准确地反映了当前动作对未来奖励的直接影响,从而降低了梯度估计的方差。
方法二:引入基准函数(Baseline)来进一步减少梯度估计方差。
- 目标:通过引入基准函数\(b\),减少梯度估计的方差,改善优化过程的稳定性。
- 常用基准:状态价值函数 \(V^\pi(s)\),也可以使用其他函数,具体取决于任务和模型的设计。
- 优势:减小了无关噪声的影响,让策略更专注于改进未来表现。
a. 梯度公式中的基准函数
基础的梯度公式为:
\]
通过引入一个基准函数 (b)(Baseline),公式变为:
\]
b. 为什么引入基准函数?
- 无偏性:可以证明,减去一个基准函数\(b\)并不会改变梯度估计的无偏性。
- 也就是说,基准函数的引入不会对梯度的方向或期望值产生影响。
- 减少方差:引入基准函数后,公式中引入了一种对奖励的“校正”,从而有效减少了梯度估计中的方差。
c. 选择基准函数的方式
常用的基准函数是状态价值函数\(V^\pi(s)\):
\]
- 解释:
- \(V^\pi(s)\)表示从当前状态\(s_t\)出发,按照策略 \(\pi\)所能获得的期望未来奖励。
- 使用 \(V^\pi(s)\)作为基准,可以有效去掉与当前状态 \(s_t\)无关的波动。
例子:高值状态与低值状态
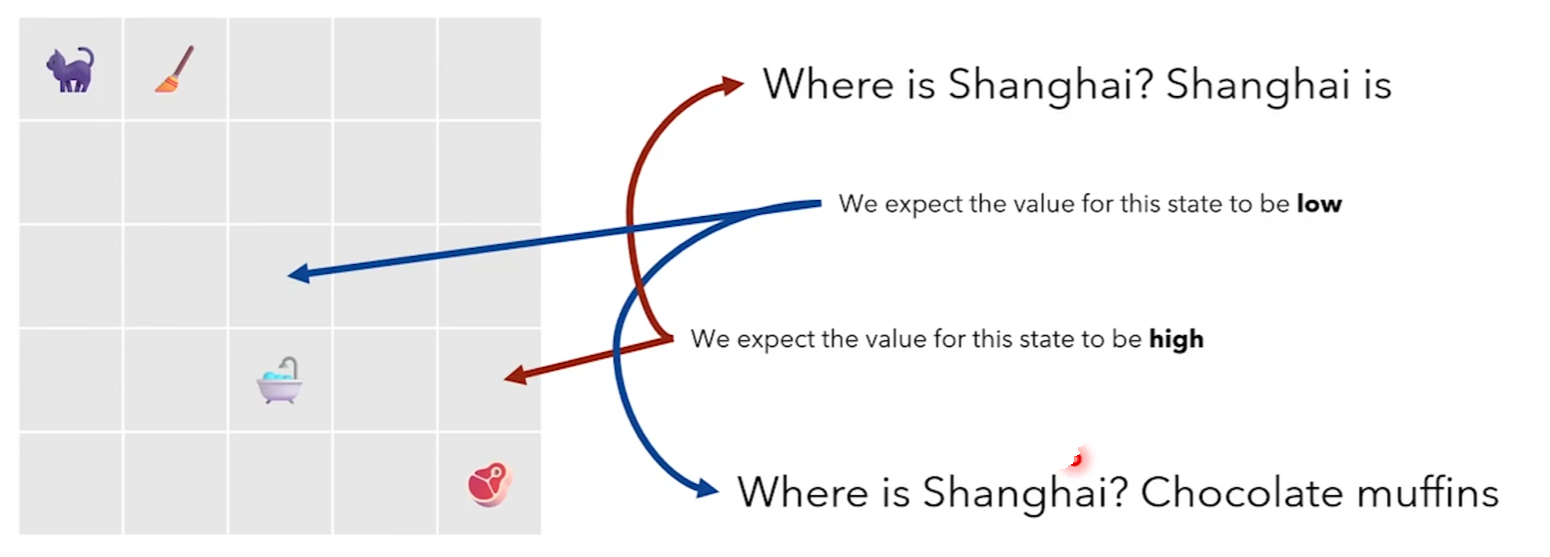
- 对于某个状态 \(s_t\),如果期望的未来奖励(价值)较低,基准值会相应较低。
- 如果某个状态的未来奖励较高(即更接近目标或有利),基准值会较高。
- 减去基准值后,梯度更新会更聚焦于当前动作的实际贡献,而不是受环境噪声或总体奖励波动的影响。
估计\(V^\pi (s)\):
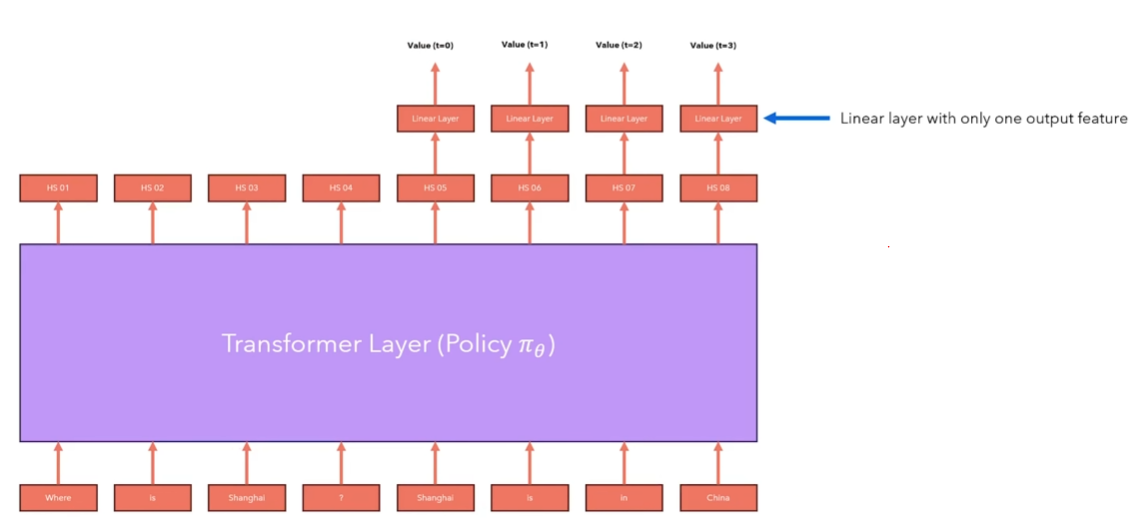
注意:语言模型已经有一个线性层(把隐藏层转化为logits值)这里添加的是另一个线性层。
d. 具体优化效果
- 引入基准函数后:
- 当 \(\sum_{t'=t}^{T} r(s_{i,t'}, a_{i,t'})\) 大于基准值 \(b\)时,表示当前动作比预期更好,梯度更新会倾向于强化该动作。
- 当 \(\sum_{t'=t}^{T} r(s_{i,t'}, a_{i,t'})\)小于基准值 \(b\)时,表示当前动作比预期更差,梯度更新会倾向于削弱该动作。
e. 引入 Q 和 V:
(未完待续)
基于人类反馈的强化学习 RLHF的更多相关文章
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- 基于C#的机器学习--惩罚与奖励-强化学习
强化学习概况 正如在前面所提到的,强化学习是指一种计算机以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使程序获得最大的奖赏,强化学习不同于连督学习,区别主要表现在强化信号上,强 ...
- 基于TORCS和Torch7实现端到端连续动作自动驾驶深度强化学习模型(A3C)的训练
基于TORCS(C++)和Torch7(lua)实现自动驾驶端到端深度强化学习模型(A3C-连续动作)的训练 先占坑,后续内容有空慢慢往里填 训练系统框架 先占坑,后续内容有空慢慢往里填 训练系统核心 ...
随机推荐
- Linux下使用sz/rz命令从服务器下载或上传文件
简介 Linux中rz命令和sz命令都可用于文件传输,而rz命令主要用于文件的上传,sz命令用于从Linux服务器下载文件到本地. 安装 yum安装 yum -y install lrzsz 源码安装 ...
- NumPy学习7
今天学习了: 13, NumPy字符串处理函数 14, NumPy数学函数 15, NumPy算术运算 numpy_test7.py : import numpy as np ''' 13, NumP ...
- Django项目如何配置日志文件信息
1.以dict的方式配置在settings.py中 # 日志文件简单配置 ''' LOGGING = { "version": 1, "disable_existing_ ...
- C#连接小智服务器并将音频解码播放过程记录
前言 最近小智很火,本文记录C#连接小智服务器并将音频解码播放的过程,希望能帮助到对此感兴趣的开发者. 如果没有ESP-32也想体验小智AI,那么这两个项目很适合你. 1.https://github ...
- Asp.net mvc基础(一):Razor语法
1.使用@{C#代码区域},调用@C#代码 2.使用@调用foreach,for,if等语句 2.在foreach,for,if等语句中使用汉字会报错,原因是在代码中纯文字会被认为是C#代码 如下: ...
- json导出csv
let data = [] let keys = ['name', 'town', 'village', 'address', 'update_time_label', 'manager'] let ...
- 【李宏毅机器学习笔记】生成式对抗网络GAN
[ 李宏毅机器学习]生成式对抗网络GAN 在传统的神经网络任务中,我们通常把一个网络当作一个函数f(x),给定输入x,网络就会输出一个对应的结果 y.比如图像分类任务中,输入是一张图片,输出是一个分类 ...
- 2025dsfz集训Day2:二分与三分
DAY2:二分与三分 \[Designed\ By\ FrankWkd\ -\ Luogu@Lwj54joy,uid=845400 \] 特别感谢 此次课的主讲 - Kwling 二分概述 二分法,在 ...
- .net6 中间件
参照资料: ASP.NET Core 中间件 | Microsoft Learn ASP.NET Core端点路由 作用原理 - 知乎 (zhihu.com) 一.概念 中间件是一种装配到应用管道以处 ...
- Web客户端开发
Web开发工具 从高层次来看,可以将客户端工具放入以下三大类需要解决的问题中: 安全网络 - 在代码开发期间有用的工具. 转换 - 以某种方式转换代码的工具,例如将一种中间语言转换为浏览器可以理解的 ...