史上最全JVM面试题和答案
JVM概要介绍
JVM是Java Virtual Machine(Java虚拟机)的缩写。
虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。
Java虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。
Java虚拟机屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行,如下图所示:

简单来说JVM是用来解析和运行Java程序的。
JVM内存模型
首先我们来了解一下JVM的内存模型的怎么样的:

1.堆:存放对象实例,几乎所有的对象实例都在这里分配内存
- 堆得内存由-Xms指定,默认是物理内存的1/64;最大的内存由-Xmx指定,默认是物理内存的1/4。
- 默认空余的堆内存小于40%时,就会增大,直到-Xmx设置的内存。具体的比例可以由-XX:MinHeapFreeRatio指定
- 空余的内存大于70%时,就会减少内存,直到-Xms设置的大小。具体由-XX:MaxHeapFreeRatio指定。
2.虚拟机栈
虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息本地方法栈:本地方法栈则是为虚拟机使用到的Native方法服务。
3.方法区:存储已被虚拟机加载的类元数据信息(元空间)
1)有时候也成为永久代,在该区内很少发生垃圾回收,但是并不代表不发生GC,在这里进行的GC主要是对方法区里的常量池和对类型的卸载
2)方法区主要用来存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据。
该区域是被线程共享的。
3)方法区里有一个运行时常量池,用于存放静态编译产生的字面量和符号引用。该常量池具有动态性,也就是说常量并不一定是编译时确定,运行时生成的常量也会存在这个常量池中。
4.程序计数器:当前线程所执行的字节码的行号指示器
总结:

JVM垃圾回收算法

1.标记-清除: 这是垃圾收集算法中最基础的,根据名字就可以知道,它的思想就是标记哪些要被回收的对象,然后统一回收。这种方法很简单,但是会有两个主要问题:1.效率不高,标记和清除的效率都很低;2.会产生大量不连续的内存碎片,导致以后程序在分配较大的对象时,由于没有充足的连续内存而提前触发一次GC动作。
2.复制算法: 为了解决效率问题,复制算法将可用内存按容量划分为相等的两部分,然后每次只使用其中的一块,当一块内存用完时,就将还存活的对象复制到第二块内存上,然后一次性清楚完第一块内存,再将第二块上的对象复制到第一块。但是这种方式,内存的代价太高,每次基本上都要浪费一般的内存。 于是将该算法进行了改进,内存区域不再是按照1:1去划分,而是将内存划分为8:1:1三部分,较大那份内存交Eden区,其余是两块较小的内存区叫Survior区。每次都会优先使用Eden区,若Eden区满,就将对象复制到第二块内存区上,然后清除Eden区,如果此时存活的对象太多,以至于Survivor不够时,会将这些对象通过分配担保机制复制到老年代中。(java堆又分为新生代和老年代)
3. 标记-整理 该算法主要是为了解决标记-清除,产生大量内存碎片的问题;当对象存活率较高时,也解决了复制算法的效率问题。它的不同之处就是在清除对象的时候现将可回收对象移动到一端,然后清除掉端边界以外的对象,这样就不会产生内存碎片了。
4.分代收集 现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分为新生代和老年代。在新生代中,由于对象生存期短,每次回收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高,没有额外的空间进行分配担保,所以可以使用标记-整理 或者 标记-清除。
JVM垃圾收集器有哪些?以及优劣势比较?

1.串行Serial收集器
串行收集器是最简单的,它设计为在单核的环境下工作(32位或者windows),你几乎不会使用到它。它在工作的时候会暂停整个应用的运行,因此在所有服务器环境下都不可能被使用。
使用方法:-XX:+UseSerialGC
2.并行Parallel收集器
这是JVM默认的收集器,跟它名字显示的一样,它最大的优点是使用多个线程来扫描和压缩堆。缺点是在minor和full GC的时候都会暂停应用的运行。并行收集器最适合用在可以容忍程序停滞的环境使用,它占用较低的CPU因而能提高应用的吞吐(throughput)。
使用方法:-XX:+UseParallelGC
3.CMS收集器
CMS是Concurrent-Mark-Sweep的缩写,并发的标记与清除。
这个算法使用多个线程并发地(concurrent)扫描堆,标记不使用的对象,然后清除它们回收内存。在两种情况下会使应用暂停(Stop the World, STW):
1. 当初次开始标记根对象时initial mark。
2. 当在并行收集时应用又改变了堆的状态时,需要它从头再确认一次标记了正确的对象final remark。
这个收集器最大的问题是在年轻代与老年代收集时会出现的一种竞争情况(race condition),称为提升失败promotion failure。对象从年轻代复制到老年代称为提升promotion,但有时侯老年代需要清理出足够空间来放这些对象,这需要一定的时间,它收集的速度可能赶不上不断产生的要提升的年轻代对象的速度,这时就需要做STW的收集。STW正是CMS想避免的问题。为了避免这个问题,需要增加老年代的空间大小或者增加更多的线程来做老年代的收集以赶上从年轻代复制对象的速度。
除了上文所说的内容之外,CMS最大的问题就是内存空间碎片化的问题。CMS只有在触发FullGC的情况下才会对堆空间进行compact。如果线上应用长时间运行,碎片化会非常严重,会很容易造成promotion failed。为了解决这个问题线上很多应用通过定期重启或者手工触发FullGC来触发碎片整理。
对比并行收集器它的一个坏处是需要占用比较多的CPU。对于大多数长期运行的服务器应用来说,这通常是值得的,因为它不会导致应用长时间的停滞。但是它不是JVM的默认的收集器。
4.G1收集器
如果你的堆内存大于4G的话,那么G1会是要考虑使用的收集器。它是为了更好支持大于4G堆内存引入的。
G1之前的JVM内存模型

- 新生代:伊甸园区(eden space) + 2个幸存区
- 老年代
- 持久代(perm space):JDK1.8之前
- 元空间(metaspace):JDK1.8之后取代持久代
G1收集器的内存模型
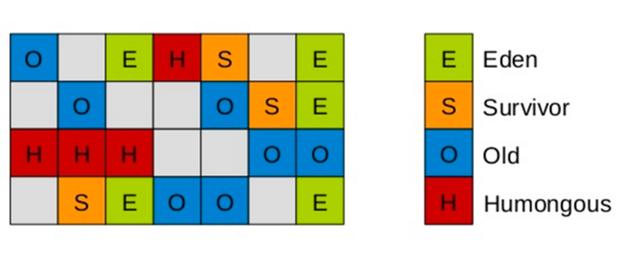
1)G1堆内存结构
堆内存会被切分成为很多个固定大小区域(Region),每个是连续范围的虚拟内存。
堆内存中一个区域(Region)的大小可以通过-XX:G1HeapRegionSize参数指定,大小区间最小1M、最大32M,总之是2的幂次方。
默认把堆内存按照2048份均分。
2)G1堆内存分配
每个Region被标记了E、S、O和H,这些区域在逻辑上被映射为Eden,Survivor和老年代。
存活的对象从一个区域转移(即复制或移动)到另一个区域。区域被设计为并行收集垃圾,可能会暂停所有应用线程。
如上图所示,区域可以分配到Eden,survivor和老年代。此外,还有第四种类型,被称为巨型区域(Humongous Region)。Humongous区域是为了那些存储超过50%标准region大小的对象而设计的,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
G1回收流程
在执行垃圾收集时,G1以类似于CMS收集器的方式运行。
G1收集器的阶段分以下几个步骤:
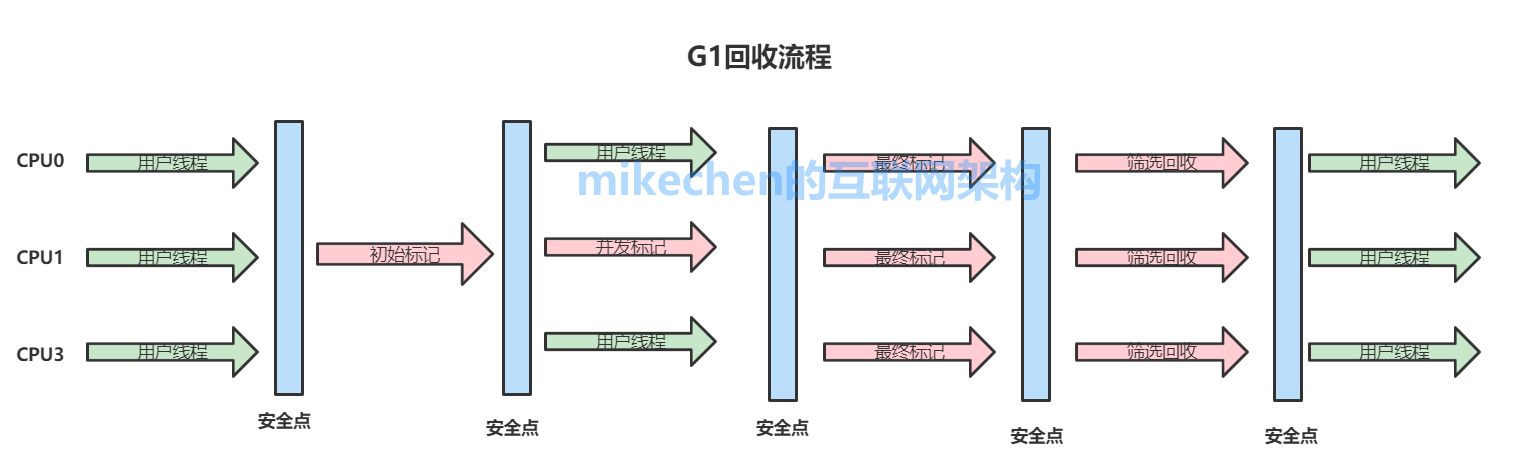
1)G1执行的第一阶段:初始标记(Initial Marking )
这个阶段是STW(Stop the World )的,所有应用线程会被暂停,标记出从GC Root开始直接可达的对象。
2)G1执行的第二阶段:并发标记
从GC Roots开始对堆中对象进行可达性分析,找出存活对象,耗时较长。当并发标记完成后,开始最终标记(Final Marking )阶段
3)最终标记(标记那些在并发标记阶段发生变化的对象,将被回收)
4)筛选回收(首先对各个Regin的回收价值和成本进行排序,根据用户所期待的GC停顿时间指定回收计划,回收一部分Region)
最后,G1中提供了两种模式垃圾回收模式,Young GC和Mixed GC,两种都是Stop The World(STW)的。
JVM配置参数
1)堆栈配置相关
例子:
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
- -XX:MaxPermSize=16m -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxTenuringThreshold=0
-Xmx 3550m: 最大堆大小为3550m。
-Xms 3550m: 设置初始堆大小为3550m。
-Xmn 2g: 设置年轻代大小为2g。
-Xss 128k: 每个线程的堆栈大小为128k。
-XX:MaxPermSize: 设置持久代大小为16m
-XX:NewRatio=4: 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。
-XX:SurvivorRatio=4: 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxTenuringThreshold=0: 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。
2)垃圾收集器相关
-XX:+UseParallelGC
-XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5
-XX:+UseCMSCompactAtFullCollection:
-XX:+UseParallelGC: 选择垃圾收集器为并行收集器。
-XX:ParallelGCThreads=20: 配置并行收集器的线程数
-XX:+UseConcMarkSweepGC: 设置年老代为并发收集。
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection: 打开对年老代的压缩。可能会影响性能,但是可以消除碎片
3)辅助信息相关
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。
JVM调优工具

- Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用。对垃圾回收算法有很详细的跟踪。
- JProfiler:商业软件,功能强大。
- VisualVM:JDK自带,功能强大,与JProfiler类似。
- MAT:MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具。
JDK本身提供了很丰富的性能监控工具,除了集成式的visualVM和jConsole外,还有jstat,jstack,jps,jmap,jhat小工具,这些都是性能调优的常用工具。
JVM性能调优步骤

1.监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化。
举一个例子: 系统崩溃前的一些现象:
- 每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
- FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
- 年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值,这个时候就需要分析JVM内存快照dump。
2.生成堆的dump文件
通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
3.分析dump文件
打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux,几种工具打开该文件:
- Visual VM
- IBM HeapAnalyzer
- JDK 自带的Hprof工具
- Mat(Eclipse专门的静态内存分析工具)推荐使用
备注:文件太大,建议使用Eclipse专门的静态内存分析工具Mat打开分析。
4.分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化,如果GC时间超过1-3秒,或者频繁GC,则必须优化。
注:如果满足下面的指标,则一般不需要进行GC:
- Minor GC执行时间不到50ms;
- Minor GC执行不频繁,约10秒一次;
- Full GC执行时间不到1s;
- Full GC执行频率不算频繁,不低于10分钟1次;
5.调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择。
6.不断的分析和调整
通过不断的试验和试错,分析并找到最合适的参数,如果找到了最合适的参数,则将这些参数应用到所有服务器。
史上最全JVM面试题和答案的更多相关文章
- 史上最全Redis面试题及答案。
花了大量时间整理了这套Redis面试题 首发50题,绝无仅有,从入门到精通 从基础,高级知识点,再到集群,运维,方案- 弄明白了这些题可以说可以成为面霸了 面试官都得折服,Redis学得怎么样,都来检 ...
- 史上最全前端面试题(含答案)-B篇
面试有几点需要注意面试题目: 根据你的等级和职位变化,入门级到专家级:范围↑.深度↑.方向↑.题目类型: 技术视野.项目细节.理论知识型题,算法题,开放性题,案例题.进行追问: 可以确保问到你开始不懂 ...
- 史上最全前端面试题(含答案)-A篇
HTML+CSS1.对WEB标准以及W3C的理解与认识标签闭合.标签小写.不乱嵌套.提高搜索机器人搜索几率.使用外 链css和js脚本.结构行为表现的分离.文件下载与页面速度更快.内容能被更多的用户所 ...
- 史上最全Redis面试题(含答案):哨兵+复制+事务+集群+持久化等
Redis主要有哪些功能? 哨兵(Sentinel)和复制(Replication) Redis服务器毫无征兆的罢工是个麻烦事,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制. S ...
- 史上最全前端面试题(含答案) - Web开发面试题
HTML+CSS 1.对WEB标准以及W3C的理解与认识 标签闭合.标签小写.不乱嵌套.提高搜索机器人搜索几率.使用外 链css和js脚本.结构行为表现的分离.文件下载与页面速度更快.内容能被更多的用 ...
- 史上最全Java面试题整理(附参考答案)
下列面试题都是在网上收集的,本人抱着学习的态度找了下参考答案,有不足的地方还请指正,更多精彩内容可以关注我的微信公众号:Java团长 1.面向对象的特征有哪些方面? 抽象:将同类对象的共同特征提取出来 ...
- 史上最全Java面试题(带全部答案)
今天要谈的主题是关于求职,求职是在每个技术人员的生涯中都要经历多次.对于我们大部分人而言,在进入自己心仪的公司之前少不了准备工作,有一份全面细致面试题将帮助我们减少许多麻烦.在跳槽季来临之前,特地做这 ...
- 史上最全Java面试题全集
2013年年底的时候,我看到了网上流传的一个叫做<Java面试题大全>的东西,认真的阅读了以后发现里面的很多题目是重复且没有价值的题目,还有不少的参考答案也是错误的,于是我花了半个月时间对 ...
- 史上最全java面试题
基本概念 操作系统中 heap 和 stack 的区别 什么是基于注解的切面实现 什么是 对象/关系 映射集成模块 什么是 Java 的反射机制 什么是 ACID BS与CS的联系与区别 Cookie ...
- 46道史上最全Redis面试题,面试官能问的都被我找到了(含答案)
Redis高性能缓存数据库 1.什么是 Redis?简述它的优缺点? Redis 的全称是:Remote Dictionary.Server,本质上是一个 Key-Value 类型的内存数据库,很像m ...
随机推荐
- ASP.Net Core使用Jenkins配合pm2自动化部署项目
一. 新建一个自由风格的软件项目 二. General配置(参数化构建) 1. 用来选择部署的服务器(我这里只添加了一个,如果需要添加多个,一行一个就可以了) 2. 选择不同的环境变量 三.源码管理 ...
- QT6.8 编译 MSVC2022-64位MySQL驱动
QT6.8没有编译MySql驱动,也没有.pro的项目文件,只能自己想办法编译,网上找了很多方法,终于找到了可以成功编译的方法,下面将我的编译过程详细记录如下: [声明:本文为原创,未经允许,不得转载 ...
- Chrome控制台中network底部概要参数
概要参数 1.requests => 资源请求总数: 2.transferred => 网络加载资源大小: 3.resources => 页面所有资源总大小(包含网络资源.浏览器缓存 ...
- Go Vue3 CMS管理后台(前后端分离模式)
本后台使用前后端分离模式开发,前端UI为Vue3+Ant Design Vue,后端Api为Go+Gin,解耦前后端逻辑,使开发更专注 技术栈 前端:Vue3,Ant Design Vue,Axios ...
- 【Java基础】-- isAssignableFrom的用法详细解析
最近在java的源代码中总是可以看到isAssignableFrom()这个方法,到底是干嘛的?怎么用? 1. isAssignableFrom()是干什么用的? 首先我们必须知道的是,java里面一 ...
- 13TB的StarRocks大数据库迁移过程
公司有一套StarRocks的大数据库在大股东的腾讯云环境中,通过腾讯云的对等连接打通,通过dolphinscheduler调度datax离线抽取数据和SQL计算汇总,还有在大股东的特有的Flink集 ...
- 圆梦:借助云开发 CloudBase实现你的游戏开发梦想
最近我发现AI产品在不断涌现新动向,尤其是一些技术巨头推出的创新产品.例如,今天我们要探讨的是腾讯云开发的云开发 CloudBase,如果你之前没有听说过这个名字,那可能还记得腾讯云推出的另一个产品- ...
- 2024年1月Java项目开发指南18:自定义异常输出
一般情况下,报错信息一大堆,值得注意的只有三个地方: 哪个文件发生了错误 哪一行发生了错误 错误原因是什么 只要知道这三个东西就能快速的定位到错误发生的位置并且根据提示解决. 如果你也喜欢我的这种异常 ...
- 【数据库】MongoDB服务启动失败的问题。
1.确保MongoDB所在文件夹拥有所有权限 2.确保打开CMD窗口是以管理员身份运行的 3.配置文件中的路径应该为完整路径,且不包含空格和特殊字符(不建议包含) systemLog: destina ...
- 配置 HTTP/HTTPS 网络代理
使用Docker的过程中,因为网络原因,通常需要使用 HTTP/HTTPS 代理来加速镜像拉取.构建和使用.下面是常见的三种场景. 为 dockerd 设置网络代理 "docker pu ...