集成学习双雄:Boosting和Bagging简介
在机器学习的世界里,集成学习(Ensemble Learning)是一种强大的技术,它通过组合多个模型来提高预测性能。
集成学习通过组合多个基学习器的预测结果,获得比单一模型更优秀的性能。其核心思想是"三个臭皮匠顶个诸葛亮",主要分为两大流派:Boosting(提升)和Bagging(装袋)。
本文将重点解析这两种方法的原理,并通过实战演示它们的应用。
1. Boosting:从错误中学习
Boosting的核心思想是串行训练:每个新模型都专注于修正前序模型的错误。
它的工作流程类似于"错题本学习法":
- 训练第一个基学习器
- 给预测错误的样本增加权重
- 基于新权重训练下一个学习器
- 重复步骤2-3,最终加权组合所有预测结果
最常见的Boosting算法是AdaBoost和Gradient Boosting。
下面我们使用Gradient Boosting来演示。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# 生成一个简单的二分类数据集
X, y = make_moons(n_samples=300, noise=0.25, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 使用 Gradient Boosting
gbc = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
gbc.fit(X_train, y_train)
# 预测并计算准确率
y_pred = gbc.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"梯度 Boosting 准确率: {accuracy:.2f}")
# 输出结果:
'''
梯度 Boosting 准确率: 0.92
'''
准确率还可以,接下来封装一个函数,把分类的结果绘制出来。
# 绘制决策边界
def plot_decision_boundary(model, X, y):
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors="k", marker="o")
plt.title("决策边界")
plt.show()
plot_decision_boundary(gbc, X, y)
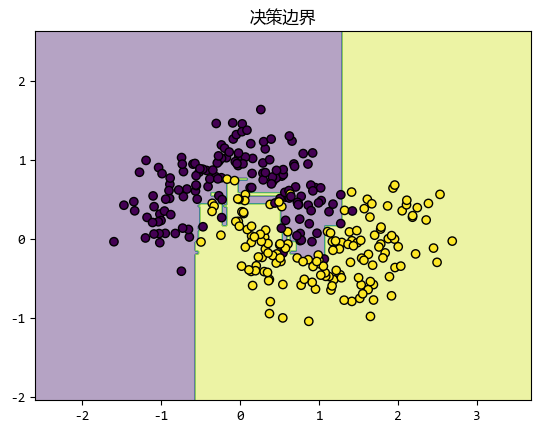
在这个例子中,我们生成了一个简单的二分类数据集,并用 Gradient Boosting 进行训练。
可以看到,模型能够很好地拟合数据,并且决策边界也很清晰。
2. Bagging:民主投票机制
Bagging的核心是并行训练+随机化。
通过随机抽样生成多个不同的数据子集,然后在每个子集上训练一个模型,最后把所有模型的预测结果汇总起来,得到最终的预测。
具体来说:
- 随机抽样:从原始数据集中随机抽取多个子集(有放回抽样)。
- 训练模型:在每个子集上训练一个模型(通常是决策树)。
- 汇总结果:对于分类任务,通过投票决定最终结果;对于回归任务,取平均值。
随机森林(Random Forest)是 Bagging 的一个经典应用,它在训练决策树时还会随机选择特征子集,进一步增加模型的多样性。
下面我们用scikit-learn的RandomForestClassifier来实现一个随机森林模型。
from sklearn.ensemble import RandomForestClassifier
# 使用 Random Forest
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# 预测并计算准确率
y_pred_rf = rf.predict(X_test)
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f"随机森林 Bagging 准确率: {accuracy_rf:.2f}")
# 输出结果:
'''
随机森林 Bagging 准确率: 0.92
'''
准确率也不错,使用上一节的函数也可以绘制出决策边界。
# 绘制决策边界
plot_decision_boundary(rf, X, y)
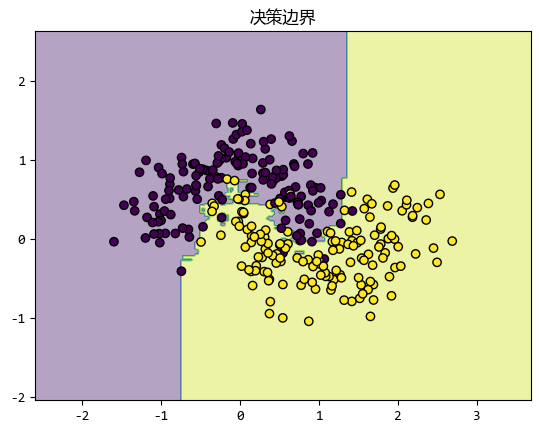
在这个例子中,我们同样使用了之前生成的二分类数据集。
随机森林通过多个决策树的组合,能够更好地处理复杂的数据分布,并且具有很强的抗过拟合能力。
3. 偏差-方差图:理解模型性能的关键
在集成学习中,偏差-方差图是一个非常有用的工具,它可以帮助我们理解模型的性能。
- 偏差(
Bias):模型对数据规律的拟合能力。偏差越高,模型越简单,可能欠拟合;偏差越低,模型越复杂,可能过拟合。 - 方差(
Variance):模型对数据噪声的敏感程度。方差越高,模型对训练数据的波动越敏感,容易过拟合;方差越低,模型对数据波动不敏感,可能欠拟合。
对于Boosting和Bagging:
Boosting:通常会降低偏差,但可能会增加方差。因为 Boosting 不断调整模型以拟合数据,容易对噪声过于敏感。Bagging:通常会降低方差,但对偏差的影响较小。因为 Bagging 通过随机抽样和投票,能够减少模型对数据波动的敏感性。
通过偏差-方差图,我们可以更好地选择合适的集成学习方法。
如果数据噪声较大,Boosting可能会过拟合;而如果数据分布复杂,Bagging可能会欠拟合。
4. 总结
Boosting和Bagging是两种非常强大的集成学习方法。
这两种集成学习方法的 对比和选择建议 如下表:
| 特性 | Boosting | Bagging |
|---|---|---|
| 训练方式 | 串行 | 并行 |
| 样本使用 | 加权调整 | 自助采样 |
| 主要优势 | 降低偏差 | 降低方差 |
| 过拟合风险 | 较高 | 较低 |
| 典型应用场景 | 复杂关系建模 | 高噪声数据处理 |
Boosting通过弱学习器的接力赛,逐步改进模型;Bagging通过随机抽样和投票,降低模型的方差。
通过scikit-learn,我们可以很容易地应用这两种方法。
集成学习双雄:Boosting和Bagging简介的更多相关文章
- 集成学习二: Boosting
目录 集成学习二: Boosting 引言 Adaboost Adaboost 算法 前向分步算法 前向分步算法 Boosting Tree 回归树 提升回归树 Gradient Boosting 参 ...
- 集成学习之Boosting —— Gradient Boosting原理
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 集成学习之Boosting -- Gradient Boosting原理 集成学习之Bo ...
- 集成学习之Boosting —— XGBoost
集成学习之Boosting -- AdaBoost 集成学习之Boosting -- Gradient Boosting 集成学习之Boosting -- XGBoost Gradient Boost ...
- 集成学习之Boosting —— AdaBoost实现
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 AdaBoost的一般算法流程 输入: 训练数据集 \(T = \left \{(x_1 ...
- 集成学习之Boosting —— AdaBoost原理
集成学习大致可分为两大类:Bagging和Boosting.Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行.Boosting则使用弱分类器,其个体学习器之间存在强依赖关系, ...
- 大白话5分钟带你走进人工智能-第30节集成学习之Boosting方式和Adaboost
目录 1.前述: 2.Bosting方式介绍: 3.Adaboost例子: 4.adaboost整体流程: 5.待解决问题: 6.解决第一个问题:如何获得不同的g(x): 6.1 我们看下权重与函数的 ...
- 集成学习之Boosting —— Gradient Boosting实现
Gradient Boosting的一般算法流程 初始化: \(f_0(x) = \mathop{\arg\min}\limits_\gamma \sum\limits_{i=1}^N L(y_i, ...
- 机器学习——集成学习之Boosting
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 AdaBoost GB ...
- 集成学习---bagging and boosting
作为集成学习的二个方法,其实bagging和boosting的实现比较容易理解,但是理论证明比较费力.下面首先介绍这两种方法. 所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升 ...
- 机器学习:集成学习(Ada Boosting 和 Gradient Boosting)
一.集成学习的思路 共 3 种思路: Bagging:独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果: Boosting(增强集成学习):集成多个模型,每个 ...
随机推荐
- C# List应用 Lambda 表达式
参考链接 : https://blog.csdn.net/wori/article/details/113144580 首先 => 翻译为{ } 然后没有然后 主要基于我工作中常用的几种情况,写 ...
- PCI-5565PIO主要应用场景
PCI-5565PIO主要应用场景包括军事领域.工业自动化和控制系统.仿真与培训以及数据采集与分发.在军事领域,PCI-5565PIO可用于航空航天系统的飞行控制计算机.导航系统和传感器系统之间的 ...
- Linux - 服务器磁盘 Raid & 分区 & 挂载
一.流计算服务器 有一台流处理服务器(系统盘:2*600G.数据盘:6*600G)分区挂载如下: 设备名 分区 大小 挂载点 文件系统类型 磁盘用途 分区类别 /dev/sda /dev/sda1 3 ...
- 大数据之路Week08_day02 (Flume的使用举例(从控制台输入数据,从本地打数据到HDFS,从java代码中进行捕获打入到HDFS,flume监控http source))
在使用之前,提供一个大致思想,使用Flume的过程是确定scource类型,channel类型和sink类型,编写conf文件并开启服务,在数据捕获端进行传入数据流入到目的地. 实例一.从控制台打入数 ...
- 在Linux系统下启动eclipse时遇到Eclipse 无法正常启动
Eclipse: 无法打开显示: 出现此问题原因: 这通常表示 Eclipse 试图在没有合适显示环境的情况下启动,可能是在没有图形界面的环境(例如远程服务器或没有正确配置的 X11 转发)中运行. ...
- Windows Api如何创建一个快捷方式并且在开始菜单搜索到自己的应用
原文链接:http://cshelloworld.com/home/detail/1804473083243925504 当我们点击win10系统搜索框的时候,输入名称 ,win10会帮助我们匹配到对 ...
- npm 如何更新项目最新依赖包
NPM 是什么? Node 软件包管理器(NPM)提供了各种功能来帮助你安装和维护项目的依赖关系. 由于错误修复.新功能和其他更新,依赖关系可能会随着时间的推移而变得过时.你的项目依赖越多,就越难跟上 ...
- phpstorm、goland常用快捷键
1) 文件操作相关的快捷键 快捷键 作用 Ctrl + E 打开最近浏览过的文件 Ctrl + N 快速打开某个 struct 结构体所在的文件 Ctrl + Shift + N 快速打开文件 Shi ...
- 使用 bc4 解决 git 合并冲突问题
博客地址:https://www.cnblogs.com/zylyehuo/ STEP1:安装 beyond compare 安装地址: https://www.scootersoftware.com ...
- JDK各个版本发布时间和版本名称
版权 版本 名称 发行日期 JDK 1.0 Oak(橡树) 1996-01-23 JDK 1.1 1997-02-19 JDK 1.1.4 Sparkler(宝石) 1997-09-12 JDK ...