SQL 强化练习 (十)
这一周都被客户搞得很惨.... 项目主流程不推进, 尽搞一些无关紧要的事情, 什么界面 ui 美化, 增加什么按钮进度条, 模糊查询...各种乱七八糟的需求, 挡都挡不住呀... 真的是把我当全栈使了, 数据库, 建表; 填报页面, 数据清洗, ui 美化, 权限配置 sql ... 真的太难了.... 发现核心呢, 还是 sql 的比重特别大, 像我们现在数据分析用的 BI 工具, 就是 以 SQL为基础的. 反而, 用 Pyhton 的地方却是很少, 跟我之前的项目差别很大, 这里用Pyhton 就只是一些做数据清洗的事情, 如过滤数据中的特殊字符 (正则) , 类型转换, 顺序调整的... 核心竞争还是 sql 呀. 果然 sql 非常强大. 继续练习呀...
表关系

我平时遇到的一些复杂些的业务场景, 基本也跟着几张表, 背后的相同逻辑所演变的. 都差不多的其实.
需求 01
查询各科成绩最高分, 最低分和平均分; 显示需求如下:
课程id, 课程 name, 最高分, 最低分, 平均分, 及格率, 中等率, 优良率, 优秀率
及格 >= 60; 中等:70-80; 优良: 80-90; 优秀: >=90
分析
目测会用到 group by case when ...
首先来查询, 课程的最高, 最低, 平均分的 (聚合函数, 肯定是结合 group by)
select
a.c_id,
b.c_name,
max(a.score),
min(a.score),
avg(a.score)
from score as a
-- 课程 name 是需要关联课程表才能拿到
inner join course as b
on a.c_id = b.c_id
group by a.c_id, b.c_name
+------+--------+--------------+--------------+--------------+
| c_id | c_name | max(a.score) | min(a.score) | avg(a.score) |
+------+--------+--------------+--------------+--------------+
| 0001 | 语文 | 80 | 80 | 80.0000 |
| 0002 | 数学 | 90 | 60 | 76.6667 |
| 0003 | 英语 | 99 | 80 | 86.3333 |
+------+--------+--------------+--------------+--------------+
3 rows in set (0.01 sec)
这一部分其实还好, 就是基本的 group by 再聚合而已.
接着来算这些什么中等率, 优良率, 优秀率.. 就有些头疼了. 率, 是要用 目标人数 / 总人数 这样的方式. 立马会想到用 count 但, 这里多条件判断嘛, 必然会用 case when 来处理呀. 其实呢, 用 sum 可能会更加普遍一点. 满足条件就舌标记为1, 否则标记 0 这样的方式.
select
a.c_id,
b.c_name,
max(a.score),
min(a.score),
avg(a.score),
-- 及格率
sum(case when a.score >= 60 then 1 else 0 end) / count(a.s_id) "及格率",
-- 中等率
sum(case when a.score >= 70 and a.score < 80 then 1 else 0 end) / count(a.s_id) "中等率",
-- 优良率
sum(case when a.score >= 80 and a.score < 90 then 1 else 0 end) / count(a.s_id) "优良率",
-- 优秀率
sum(case when a.score >= 90 then 1 else 0 end) / count(a.s_id) as "优秀率"
from score as a
-- 课程 name 是需要关联课程表才能拿到
inner join course as b
on a.c_id = b.c_id
group by c_id, c_name
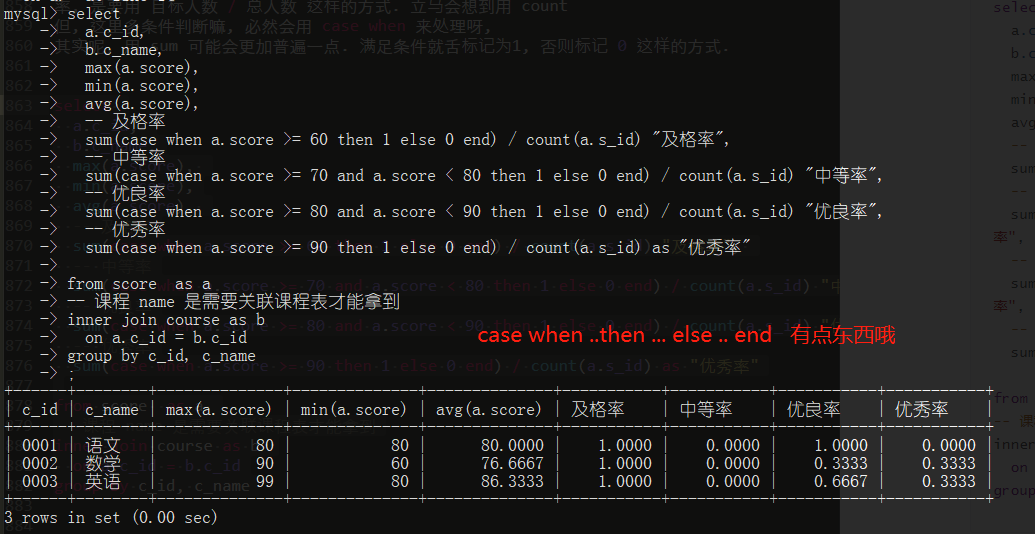
这个例子的关键点, 首先还是基于分组, 聚合 的用法, 中间过程呢, 会涉及表的拼接(inner join). 然后是 case when 可用来做条件计数 这个感觉蛮厉害的, 我其实在工作中都没用过. 类似的我都用 Python 来搞了, 没想到这 sql 原来还这么强大的哦.
需求 02
查询学生的总成绩, 并进行排名
分析
一个基础送分题, 按 s_id 分组, 对 score 统计即可.
select
s_id as "学号",
sum(score) as "总成绩"
from score
group by s_id
+--------+-----------+
| 学号 | 总成绩 |
+--------+-----------+
| 0001 | 269 |
| 0002 | 140 |
| 0003 | 240 |
+--------+-----------+
3 rows in set (0.00 sec)
mysql>
然后排序一波即可. (把姓名也 inner join 过来顺带)
select
a.s_id as "学号",
b.s_name as "姓名",
sum(a.score) as "总成绩"
from score as a
-- 学生信息帖过来
inner join student as b
on a.s_id = b.s_id
group by a.s_id, b.s_name
order by sum(score) desc
+--------+-----------+-----------+
| 学号 | 姓名 | 总成绩 |
+--------+-----------+-----------+
| 0001 | 王二 | 269 |
| 0003 | 胡小适 | 240 |
| 0002 | 星落 | 140 |
+--------+-----------+-----------+
3 rows in set (0.00 sec)
-- 这一句感觉怪怪的, 应该用上面别名的.
order by sum(score) desc
最后修改如下:
select
a.s_id as 学号,
b.s_name as 姓名,
sum(a.score) as 总成绩
from score as a
-- 学生信息帖过来
inner join student as b
on a.s_id = b.s_id
group by a.s_id, b.s_name
order by 总成绩 desc
+--------+-----------+-----------+
| 学号 | 姓名 | 总成绩 |
+--------+-----------+-----------+
| 0001 | 王二 | 269 |
| 0003 | 胡小适 | 240 |
| 0002 | 星落 | 140 |
+--------+-----------+-----------+
3 rows in set (0.00 sec)
可以, 发现, 在 mysql 中, 可以直接用 中文 作为别名.
小结
- sum(case when ..then 1 else 0 end) 可以用来进行 条件计数哦 (配合 group by )
- 表 join 可以在中途进行, 理清楚 sql 的执行顺序即可 from > on > join > where > group by > having > select > distinct > order by
- 发现 mysql 中, 别名可以直接使用中文, 比如 之前是 xxx as "总成绩", 也可直接 xxx as 总成绩 .
SQL 强化练习 (十)的更多相关文章
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- SQL入门经典(十) 之事务
事务是什么?事务关键在与其原子性.原子性概念是指可以把一些事情当作一个执行单元来看待.从数据库角度看待.他是指应该全部执行或者全部不执行一条或多条语句的最小组合.当处理数据时候经常确保一件事发生另一件 ...
- SQL强化(一)保险业务
保险业务 : 表结构 : sql语句 : /*1. 根据投保人电话查询出投保人 姓名 身份证号 所有保单 编号 险种 缴费类型*/SELECTt2.cust_name,t2.idcard,t4.pro ...
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- SQL强化练习(面试与学习必备)
一.经典选课题A 1.1.请同时使用GUI手动与SQL指令的形式创建数据库.表并添加数据. 题目:设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教 ...
- SQL语句(十二)分组查询
(十二)分组查询 将数据表中的数据按某种条件分成组,按组显示统计信息 查询各班学生的最大年龄.最小年龄.平均年龄和人数 分组 SELECT <字段名表1> FROM <表名> ...
随机推荐
- Java中编译期异常和运行期异常的区别
在Java中,异常分为运行期异常(Runtime Exception)和编译期异常(Checked Exception),两者的核心区别在于 编译器是否强制要求处理.以下是它们的详细对比: 1. 定义 ...
- linux服务问题传文件连不上问题远程问题等
通过iptables相关命令实现防火墙的打开和关闭 1.首先可以在打开的终端使用iptables --help查看帮助使用命令: 2.查看防火墙状态:service iptables status(此 ...
- 【Pre】Exercise Log
Pre2 #Task1 测评机(Java8)不支持enhanced Switch. Switch中,将case后的:改为->后,将会取消fall through,可以删去break; #Task ...
- 【独立开发作品】SlideBrowser 一个轻量的滑动浏览器,给你不一样的交互体验
产品介绍 SlideBrowser是一个滑动浏览器,当你鼠标移动到屏幕边缘,自动出现,当失焦时自动隐藏. 使用场景 在应用全屏模式下查询资料.问 GPT 等 记录一些待办事项或者笔记 查看股市.币市信 ...
- zstd压缩算法概述与基本使用
本文仅关注zstd的使用,并不关心其算法的具体实现 并没有尝试使用zstd的所有功能模式,但是会简单介绍每种模式的应用场景,用到的时候去查api吧 step 0:why zstd? zstd是face ...
- Linux 安装配置Anaconda
下载地址 https://www.anaconda.com/download/success 选择系统版本,复制链接 wget https://repo.anaconda.com/archive/An ...
- laradock 安装扩展程序 pcntl
起因 运行workman脚步的时候,PHP 提示缺少 pcntl 扩展 Config git:(master) php start.php -d Please install pcntl extens ...
- kvm内存优化--KSM
一.KSM(Kernel SamePage Merging) 1.KSM简介 KSM允许内核在多个进程(包括虚拟机)之间共享完全相同的内存页,KSM让内核扫描检查正在运行中的程序并且比较他们的内存,若 ...
- BUUCTF---RSA3(共模攻击)
1.题目 RSA已知e1,e2,c1,c2 2.知识 共模攻击使用相同N作为加密的模数,如果监听者获知了c1,c2的密文,那么监听者便不需要d1,d2即可解出明文m 3.解题 按照思路编写代码解题 点 ...
- 【Python】解决“Tk_GetPixmap: Error from CreateDIBSection”闪退问题
解决Python使用Tkinter的Notebook切换标签时出现的"Tk_GetPixmap: Error from CreateDIBSection 操作成功完成"闪退问题 零 ...