解决Dify的Ollama插件添加模型时保存成功但模型为空的问题
最近组里安排了点调研Dify任务。我跟着基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程一步一步走,前面都挺顺利,但在Dify的Ollama中引入大模型这一步卡住了:按照原文,我添加了本地安装的deepseek-r1:1.5b,点击“保存”,提示“保存成功”但模型列表却是空的。
我摸索了半天,改了一通配置终于搞定,其中关键的一步配置在CXXN上看到了一些蛛丝马迹,但CXXN搞的付费订阅非常恶心,我从其他渠道弄明白以后,总结了一下自己做的操作,共享出来。
问题的根因
- Dify默认配置对插件安装过程的超时限制较短,且依赖下载可能因网络问题失败
- 确保 Ollama 插件有足够时间完成安装,并通过国内镜像源加速依赖下载
解决方法
假定你已经在Windows环境完成了Docker安装、Dify镜像的下载和启动、Ollama的本地安装,要在Dify里的Ollama插件添加大模型:
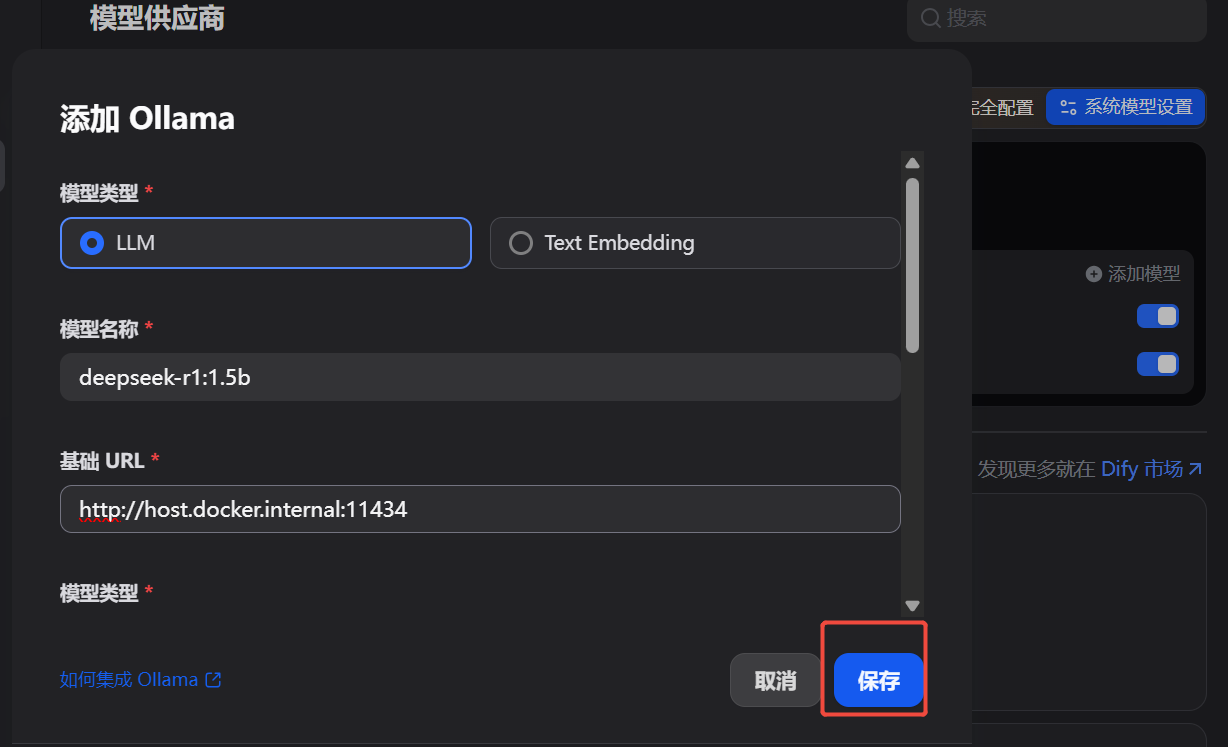
先把Dify镜像停掉:去dify/docker目录下执行
docker-compose down
可以看到关联的镜像状态都是Removed

编辑dify/docker/docker-compose.yaml,在environment部分增加
PYTHON_ENV_INIT_TIMEOUT: 600 # 延长超时时间(默认值较低可能导致安装超时)
PIP_MIRROR_URL: "https://pypi.tuna.tsinghua.edu.cn/simple" # 替换为国内镜像源加速依赖安装
重启dify
docker-compose up -d
先看下Docker的日志,出现了一些相关的信息:

等到Ollama安装完成时,再回到Dify的Ollama添加大模型,发现之前保存的模型都出现,可以继续下一步了,Good Job!
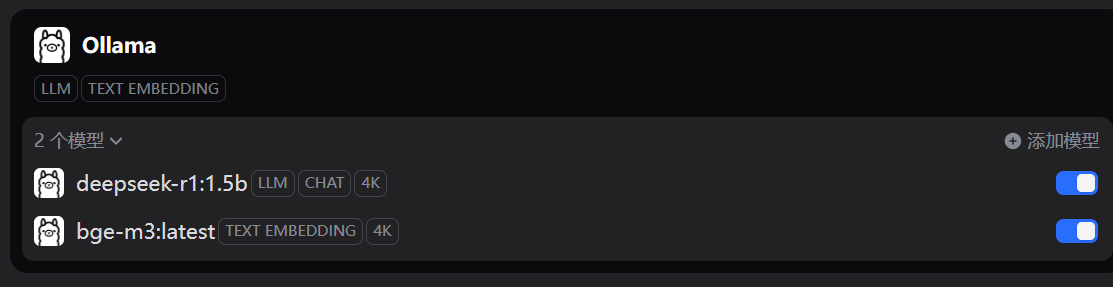
其他的排查手段和配置更改
在排查过程中,我还做了一些其他配置变更,关系应该不大但是还是记录下,便于后续查阅。
如何判断Docker中运行的Dify能访问本地安装的Ollama?
Windows/Mac是默认支持的,Linux需要一些配置。进入Dify运行中的镜像,执行curl http://host.docker.internal:11434确认。还可以执行curl http://host.docker.internal:11434/api/tags确认ollama已安装的模型。

Ollama是否要手动启动(执行ollama serve)?
Windows确定它在运行即可,如果在运行就不需要再次执行。
是否要降低Ollama版本到0.15.x?
没必要。Ollama的版本号遵循语义化版本规范,看上去比较跳跃:如1.6.0 → 0.15.8 → 1.4.1,某些博文提到添加模型不成功可以通过降低版本到0.15.x来解决。但我在最新的1.6.0通过上文中的配置也解决了这个问题。
Ollama的环境变量是否是必须的?
也许不是必须的,但是在我之前的尝试里已经添加过了:OLLAMA_HOST:0.0.0.0、OLLAMA_ORIGING:*
配置变更后重启Dify服务的方法
配置变更后一般都要重启一下。这步不是在Docker Desktop,而是在Dify目录下,cmd中分别执行:
docker-compose down
docker-compose up -d
Dify配置页面“系统模型设置”提示“系统模型尚未完全配置”是否有影响?
没有任何影响。实际上当你配置好LLM和TEXT EMBEDDING两种模型后,这个提示就会消失。
附:Docker+DeepSeek+Dify安装全流程简述(Win10版)
为了便于查阅和后续的复用,我简单总结了一下整个流程。完整版可以看基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
- 下载安装docker、WSL,确定Docker Desktop启动时右下角出现
Engine running
1.1 (可选)迁移docker镜像路径:Settings->Resources->Disk image location
1.2 (可选,国内一般必须)配置国内镜像源:Settings-> Docker Engine
1.3 (可选)拉取镜像,cmd中docker pull hello-world - 安装Omalla及DeepSeek等大模型(本地版)
2.1 Ollama官网下载
2.2 安装,(可选,可以通过特殊方法改变安装路径), cmd中ollama -v可以看到版本即表示安装成功
2.3 安装DeepSeek等大模型
2.3.1 在Ollama官网的models中找到对应模型及版本,点击复制按钮获取全名,以deepseek-r1:1.5b为例,cmd输入ollama run deepseek-r1:1.5b开始下载
2.3.2 下载完成即进入对话模式
2.4 (可选)安装ChatBox AI
2.4.1 选择Ollama API即可图形化使用本地的DeepSeek
2.4.2 连接Ollama失败时新增两个环境变量OLLAMA_HOST:0.0.0.0、OLLAMA_ORIGING:*,需重启Ollama - 安装Dify
3.1 去Dify的Github,可以git clone也可以下载最新版的zip包直接解压到目标路径
3.2 .env.example复制并重命名为.env
3.3 在Dify目录拉去依赖docker-compose up -d,完成后在docker中确认镜像都在运行中 - Dify配置
4.1 进入本地Dify:http://127.0.0.1/,创建管理员用户
4.2 右上角头像,设置->模型供应商,添加Ollama插件
4.3 Ollama插件中添加已安装的模型:模型名称为带版本号的全称,URL为http://host.docker.internal:11434。如果添加提示成功但仍然没有模型,参考正文的解决方法。 - 创建应用,开始使用。
解决Dify的Ollama插件添加模型时保存成功但模型为空的问题的更多相关文章
- Keras(六)Autoencoder 自编码 原理及实例 Save&reload 模型的保存和提取
Autoencoder 自编码 压缩与解压 原来有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所 ...
- dedecms添加文章时提示标题为空,编辑文章时编辑器空白的解决办法
dedecms添加文章时提示标题为空,编辑文章时编辑器空白的解决办法 dedecms出现这个问题与代码无关,主要是和PHP的版本有关,用的PHP5.4,更换成PHP5.2之后就不会有这个问题了. 问题 ...
- 解决 VS Code「Code Runner」插件运行 python 时的中文乱码问题
描述 这里整理了两种 VS Code「Code Runner」插件运行 python 时乱码的解决方案.至于设置「Auto Guess Encoding」为 true 的操作这里就不多描述了. 乱码截 ...
- 解决在mysql表中删除自增id数据后,再添加数据时,id不会自增1的问题
https://blog.csdn.net/shaojunbo24/article/details/50036859 问题:mysql表中删除自增id数据后,再添加数据时,id不会紧接.比如:自增id ...
- 给jquery-validation插件添加控件的验证回调方法
jquery-validation.js在前端验证中使用起来非常方便,提供的功能基本上能满足大部分验证需求,例如:1.内置了很多常用的验证方法:2.可以自定义错误显示信息:3.可以自定义错误显示位置: ...
- 解决eclipse中svn插件总是提示输入密码的问题
一.背景 最近在eclipse中使用svn插件进行远程仓库代码管理时,老是出现提示让输入密码,特别烦人,经过努力,终于解决该问题,拿来和大家分享~ 二.svn插件密码机制以及出现问题的原因分析 当我们 ...
- 使用mx:Repeater在删除和添加item时列表闪烁
使用mx:Repeater在删除和添加item时列表闪烁 不可能在用户界面上闪闪的吧,recycleChildren属性可帮助我们 recycleChildren属性==缓存,设为true就可以了 本 ...
- phpcmsv9如何实现添加栏目时不在首页内容区显示只在导航栏显示
之前王晟璟一直使用PHPCMSV9系统建过自己的个人门户网站,同时也建立了一个其他类型的网站,感觉非常不错,我不得不说PHPCMSV9的功能非常齐全,非常强大. 但有一点时常让王晟璟感到很烦脑,那就是 ...
- 警惕rapidxml的陷阱:添加节点时,请保证变量的生命周期
http://www.cnblogs.com/chutianyao/p/3246592.html 项目中要使用xml打包.解析协议,HQ指定了使用rapidxml--号称是最快的xml解析器. 功能很 ...
- 如何解决FormView中实现DropDownList连动选择时出现 "Eval()、XPath() 和 Bind() 这类数据绑定方法只能在数据绑定控件的上下文中使用" 的错误
原文:如何解决FormView中实现DropDownList连动选择时出现 "Eval().XPath() 和 Bind() 这类数据绑定方法只能在数据绑定控件的上下文中使用" 的 ...
随机推荐
- 聊聊智商税:AI知识库
提供AI咨询+AI项目陪跑服务,有需要回复1 DeepSeek一体机是一种神奇的存在,很多公司跟风购买后发现一个尴尬的事情:用不起来,于是一体机厂家或者中间商便需要在其中叠加AI场景,这里最常见的场景 ...
- zk源码—6.Leader选举的实现原理
大纲 1.zk是如何实现数据一致性的 (1)数据一致性分析 (2)实现数据一致性的广播模式 (3)实现数据一致性的恢复模式 2.zk是如何进行Leader选举的 (1)服务器启动时的Leader选举 ...
- 🎀Java-Exception与RuntimeException
简介 Exception Exception 类是所有非致命性异常的基类.这些异常通常是由于编程逻辑问题或外部因素(如文件不存在.网络连接失败等)导致的,可以通过适当的编程手段来恢复或处理.Excep ...
- 多模态模型 Grounding DINO 初识
简介 Grounding DINO 是一种先进的零样本目标检测模型,由 IDEA Research 开发.它通过将基于 Transformer 的检测器 DINO 与Grounded Pre-Trai ...
- MySQL 中的回表是什么?
MySQL 中的回表 回表是 MySQL 查询优化中的一个概念,指的是在使用非聚簇索引查询时,无法直接从索引中获取所需的所有数据,需要通过非聚簇索引查找到主键值,然后再去聚簇索引中根据主键值获取完整数 ...
- kali网卡消失解决
问题:kali网卡消失解决如图 解决: 1.查看配置文件 └─# cat /etc/network/interfaces # This file describes the network inter ...
- Java Factory工厂模式
/** * 工厂类:用于连接接口和子类,尽量减少客户端的复杂性 * 2017-08-25 * @author Junwei Zhu * */ interface Fruit { public void ...
- 稀疏贝叶斯谱估计及EM算法求解
稀疏贝叶斯 稀疏贝叶斯学习(sparse bayes learning,SBL)最早被提出是作为一种机器学习算法[1].但是在这里我们主要用它来做谱估计,作为求解稀疏重构问题的方法[2].稀疏重构还有 ...
- SharpIco:用纯C#打造零依赖的.ico图标生成器,支持.NET9与AOT编译
前言 最近一直在完善我今年的两款桌面软件:视频剪辑工具 Clipify 和 AI 文章创作工具 StarBlogPublisher 虽然界面是基本完善了,但图标还是默认的,显得很不专业 于是我打算给这 ...
- 基于Streamlit的BS直聘数据爬取可视化平台(爬虫)
一.项目介绍 本项目是一个基于Streamlit和Selenium的BOSS直聘职位数据爬虫系统,提供了友好的Web界面,支持自定义搜索条件.扫码登录.数据爬取和导出等功能. 1.1 功能特点 支持多 ...