红黑树规则,TreeSet原理,HashSet特点,什么是哈希值,HashSet底层原理,Map集合特点,Map集合遍历方法
==学习目标==
1、能够了解红黑树
2、能够掌握HashSet集合的特点以及使用(特点以及使用,哈希表数据结构)
3、能够掌握Map集合的特点以及使用(特点,常见方法,Map集合的遍历)
4、能够掌握HashMap集合的特点以及使用
5、能够掌握TreeMap集合的特点以及使用
==知识点==
红黑树
HashSet
Map
HashMap
TreeMap
==知识点梳理==
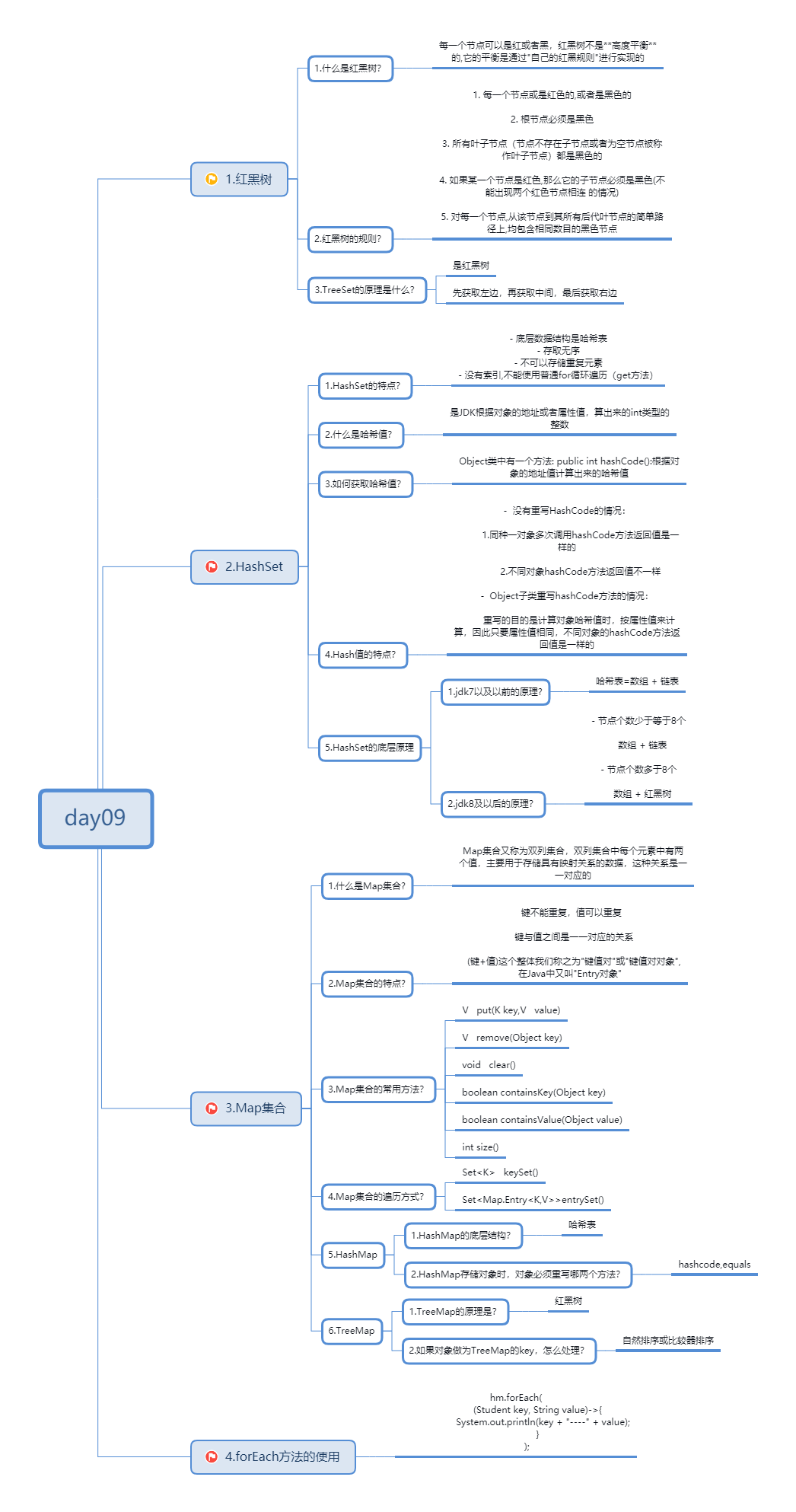
==超详细讲义==
1.红黑树
1.1红黑树-概述【了解】(视频01) (2‘’)
1.什么是红黑树
平衡二叉B树,每一个节点可以是红或者黑,红黑树不是高度平衡的,它的平衡是通过"自己的红黑规则"进行实现的。
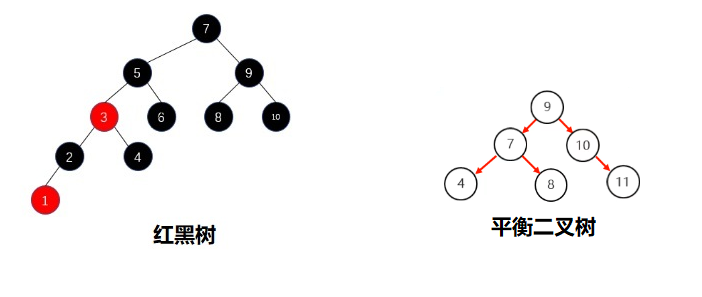
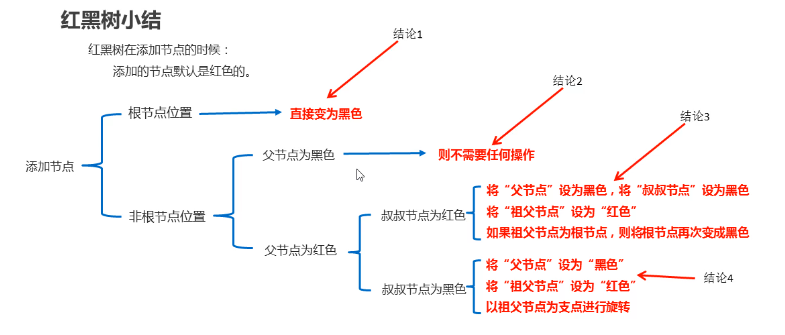
1.2 红黑树-红黑规则 (了解) (视频02)(5‘’)
红黑树的红黑规则有哪些
每一个节点或是红色的,或者是黑色的
根节点必须是黑色
所有叶子节点(空的节点被称作叶子节点)都是黑色的
不能出现两个红色节点相连 的情况
对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
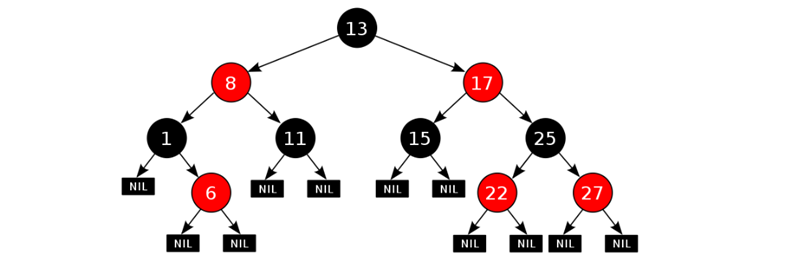
1.3 红黑树-添加节点的默认颜色(了解) (视频03) (4‘’)
添加节点时,默认为红色,效率高
1.4 红黑树-添加节点后,如何保证红黑规则1 【难点】(视频04)(8'')
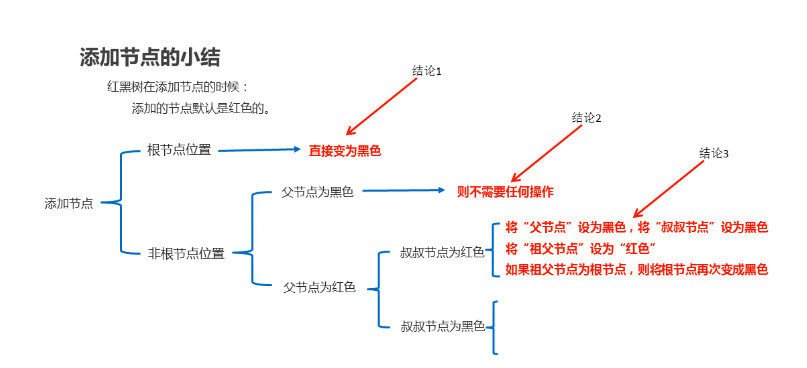

1.5 红黑树-添加节点后,如何保证红黑规则2 【难点】(视频05)(11'')
(旋转之后,根据规则验证是否是红黑树,总结红黑树添加节点的规则)
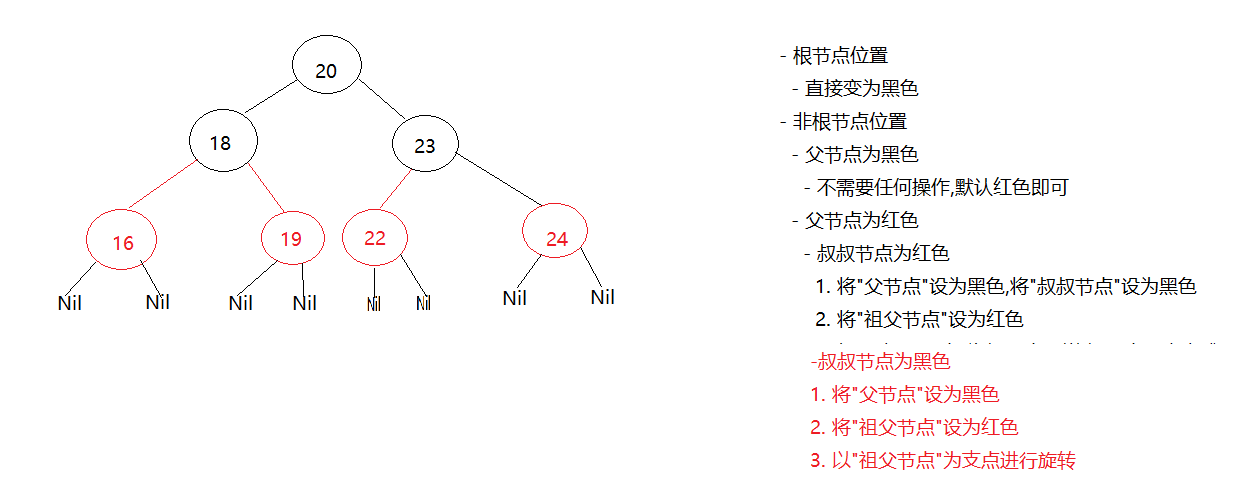
1.6 红黑树练习-成绩排序案例【重点】(视频06)(15'')
(共3点)
1.案例需求
用TreeSet集合存储多个学生信息(姓名,语文成绩,数学成绩,英语成绩),并遍历该集合
要求: 按照总分从低到高排序
代码实现
学生类
public class Student implements Comparable<Student> {
private String name;
private int chinese;
private int math;
private int english;
public Student() {
}
public Student(String name, int chinese, int math, int english) {
this.name = name;
this.chinese = chinese;
this.math = math;
this.english = english;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getChinese() {
return chinese;
}
public void setChinese(int chinese) {
this.chinese = chinese;
}
public int getMath() {
return math;
}
public void setMath(int math) {
this.math = math;
}
public int getEnglish() {
return english;
}
public void setEnglish(int english) {
this.english = english;
}
public int getSum() {
return this.chinese + this.math + this.english;
}
@Override
public int compareTo(Student o) {
// 主要条件: 按照总分进行排序
int result = o.getSum() - this.getSum();
// 次要条件: 如果总分一样,就按照语文成绩排序
result = result == 0 ? o.getChinese() - this.getChinese() : result;
// 如果语文成绩也一样,就按照数学成绩排序
result = result == 0 ? o.getMath() - this.getMath() : result;
// 如果总分一样,各科成绩也都一样,就按照姓名排序
result = result == 0 ? o.getName().compareTo(this.getName()) : result;
return result;
}
}
测试类
public class TreeSetDemo {
public static void main(String[] args) {
//创建TreeSet集合对象,通过比较器排序进行排序
TreeSet<Student> ts = new TreeSet<Student>();
//创建学生对象
Student s1 = new Student("jack", 98, 100, 95);
Student s2 = new Student("rose", 95, 95, 95);
Student s3 = new Student("sam", 100, 93, 98);
//把学生对象添加到集合
ts.add(s1);
ts.add(s2);
ts.add(s3);
//遍历集合
for (Student s : ts) {
System.out.println(s.getName() + "," + s.getChinese() + "," + s.getMath() + "," + s.getEnglish() + "," + s.getSum());
}
}
}
2.TreeSet原理
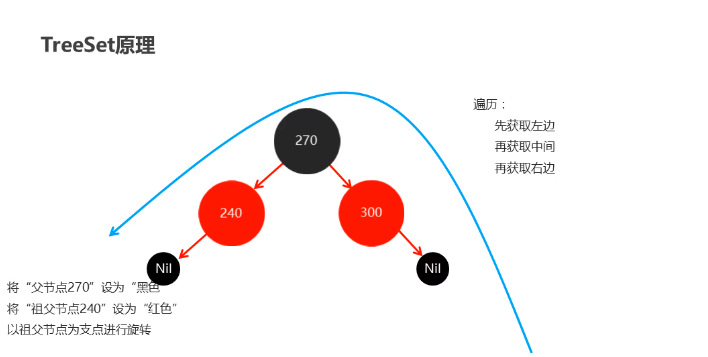

2.HashSet集合
2.1HashSet-基本使用【重点】(视频07)(4‘’)
1.什么是HashSet(HashSet的特点)
底层数据结构是哈希表
存取无序
不可以存储重复元素
没有索引,不能使用普通for循环遍历(get方法)
2.HashSet使用-存储字符串并遍历
package com.itheima.myhashset;
import java.util.HashSet;
import java.util.Iterator;
/**
* 添加字符串并进行遍历
*/
public class HashSetDemo1 {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<>();
hs.add("hello");
hs.add("world");
hs.add("java");
hs.add("java");
hs.add("java");
hs.add("java");
hs.add("java");
hs.add("java");
Iterator<String> it = hs.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
System.out.println("=============================");
for (String s : hs) {
System.out.println(s);
}
}
}
2.2哈希值【了解】(视频08) (8'')
1.什么是哈希值
是JDK根据对象的地址或者属性值,算出来的int类型的整数
2.如何获取对象中的Hash值
Object类中有一个方法: public int hashCode():根据对象的地址值计算出来的哈希值
3.哈希值的特点
没有重写HashCode的情况:
1.同种一对象多次调用hashCode方法返回值是一样的
2.不同对象hashCode方法返回值不一样
Object子类重写hashCode方法的情况:
重写的目的是计算对象哈希值时,按属性值来计算,因此只要属性值相同,不同对象的hashCode方法返回值是一样的
package com.itheima.myhashset;
/**
* 计算哈希值
*/
public class HashSetDemo2 {
public static void main(String[] args) {
Student s1 = new Student("xiaozhi",23);
Student s2 = new Student("xiaomei",22);
//因为在Object类中,是根据对象的地址值计算出来的哈希值。
System.out.println(s1.hashCode());//1060830840
System.out.println(s1.hashCode());//1060830840
System.out.println(s2.hashCode());//2137211482
}
}
Student类
package com.itheima.myhashset;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//我们可以对Object类中的hashCode方法进行重写
//在重写之后,就一般是根据对象的属性值来计算哈希值的。
//此时跟对象的地址值就没有任何关系了。
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
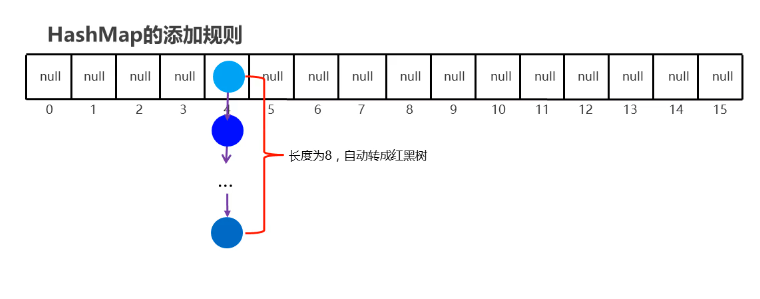
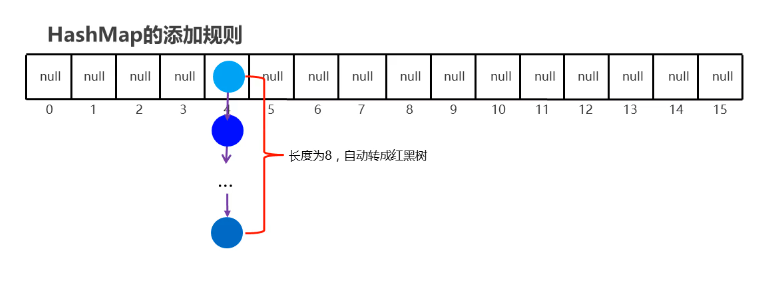
2.4HashSet-JDK7底层原理【难点】(视频09)(6'')
哈希表=数组 + 链表

2.5HashSet-JDK8底层优化【难点】(视频10)(3'')
(共两点)
1.HashSet 在JDK1.8之后的原理
节点个数少于等于8个
数组 + 链表
节点个数多于8个
数组 + 红黑树
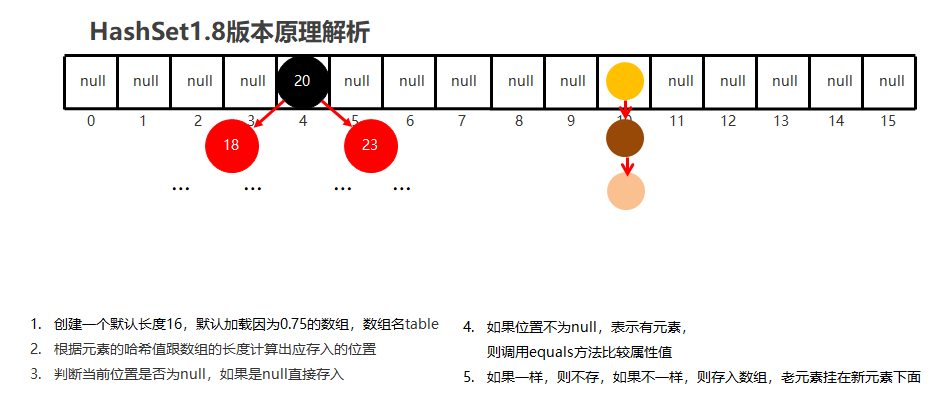
2.HashSet 在JDK1.8版本的存储流程

2.6HashSet集合存储学生对象并遍历【重点】(视频11) (7'')
案例需求
创建一个存储学生对象的集合,存储多个学生对象,使用程序实现在控制台遍历该集合
要求:学生对象的成员变量值相同,我们就认为是同一个对象
代码实现
测试类
public class HashSetDemo2 {
public static void main(String[] args) {
//HashSet集合存储自定义类型元素,要想实现元素的唯一,要求必须重写hashCode方法和equals方法
HashSet<Student> hashSet = new HashSet<>();
Student s1 = new Student("xiaohei",23);
Student s2 = new Student("xiaohei",23);
Student s3 = new Student("xiaomei",22);
hashSet.add(s1);
hashSet.add(s2);
hashSet.add(s3);
for (Student student : hashSet) {
System.out.println(student);
}
}
}学生类
package com.itheima.myhashset;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Student student = (Student) o;
if (age != student.age) {
return false;
}
return name != null ? name.equals(student.name) : student.name == null;
}
//我们可以对Object类中的hashCode方法进行重写
//在重写之后,就一般是根据对象的属性值来计算哈希值的。
//此时跟对象的地址值就没有任何关系了。
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
3.Map集合
3.1Map-基本使用【重点、难点】(视频13)(6'')
(共3点)
1.什么是Map集合【记忆】
Map集合又称为双列集合,双列集合中元素的内容是成对的
2.Map集合的特点 【记忆】
键不能重复,值可以重复
键与值之间是一一对应的关系
(键+值)这个整体我们称之为"键值对"或"键值对对象",在Java中又叫"Entry对象"
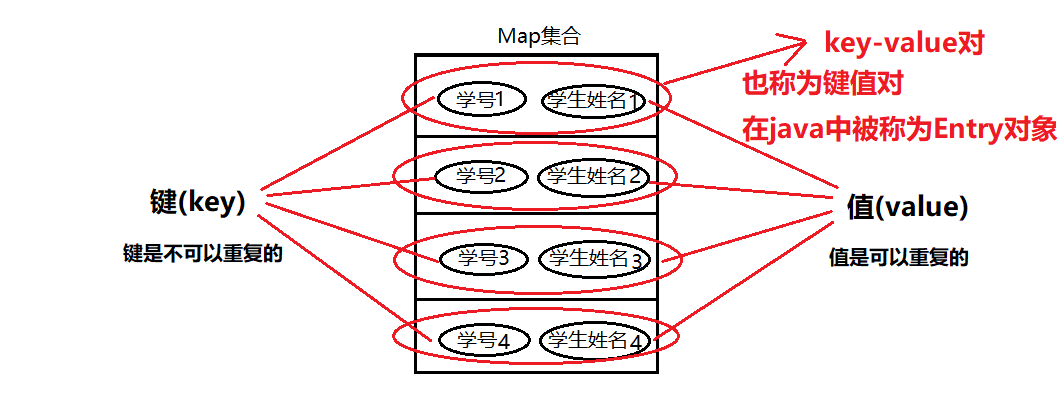
3.如何使用Map集合
1.Map集合格式
interface Map<K,V> K:键的类型;V:值的类型
2.如何创建Map集合对象
Map<String,String> map = new HashMap<String,String>();//使用具体实现类,采用多态形式创建
4.使用Map集合存储学生学号和姓名
package com.itheima.mapdemo1;
import java.util.HashMap;
import java.util.Map;
/**
* Map的基本使用
*/
public class MyMap1 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
//map.add();
map.put("itheima001","小智");
map.put("itheima002","小美");
map.put("itheima003","大胖");
System.out.println(map);
}
}
3.2Map常用方法【重点】(视频14) (11'')
方法介绍
方法名 说明 V put(K key,V value) 添加元素 V remove(Object key) 根据键删除键值对元素 void clear() 移除所有的键值对元素 boolean containsKey(Object key) 判断集合是否包含指定的键 boolean containsValue(Object value) 判断集合是否包含指定的值 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,也就是集合中键值对的个数 示例代码
package com.itheima.mapdemo1;
import java.util.HashMap;
import java.util.Map;
/**
* Map的基本方法
*/
public class MyMap2 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("itheima001","小智");
map.put("itheima002","小美");
map.put("itheima003","大胖");
map.put("itheima004","小黑");
map.put("itheima005","大师");
//method1(map);
//method2(map);
//method3(map);
//method4(map);
//method5(map);
//method6(map);
//method7(map);
}
private static void method7(Map<String, String> map) {
// int size() 集合的长度,也就是集合中键值对的个数
int size = map.size();
System.out.println(size);
}
private static void method6(Map<String, String> map) {
// boolean isEmpty() 判断集合是否为空
boolean empty1 = map.isEmpty();
System.out.println(empty1);//false
map.clear();
boolean empty2 = map.isEmpty();
System.out.println(empty2);//true
}
private static void method5(Map<String, String> map) {
// boolean containsValue(Object value) 判断集合是否包含指定的值
boolean result1 = map.containsValue("aaa");
boolean result2 = map.containsValue("小智");
System.out.println(result1);
System.out.println(result2);
}
private static void method4(Map<String, String> map) {
// boolean containsKey(Object key) 判断集合是否包含指定的键
boolean result1 = map.containsKey("itheima001");
boolean result2 = map.containsKey("itheima006");
System.out.println(result1);
System.out.println(result2);
}
private static void method3(Map<String, String> map) {
// void clear() 移除所有的键值对元素
map.clear();
System.out.println(map);
}
private static void method2(Map<String, String> map) {
// V remove(Object key) 根据键删除键值对元素
String s = map.remove("itheima001");
System.out.println(s);
System.out.println(map);
}
private static void method1(Map<String, String> map) {
// V put(K key,V value) 添加元素
//如果要添加的键不存在,那么会把键值对都添加到集合中
//如果要添加的键是存在的,那么会覆盖原先的值,把原先值当做返回值进行返回。
String s = map.put("itheima001", "aaa");
System.out.println(s);
System.out.println(map);
}
}
3.3Map-第一种遍历方式【重点】(视频15) (11'')
方法介绍
| 方法名 | 说明 |
|---|---|
| Set<K> keySet() | 获取所有键的集合 |
| V get(Object key) | 根据键获取值 |

示例代码
package com.itheima.mapdemo1;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Map的第一种遍历方式
*/
public class MyMap3 {
public static void main(String[] args) {
//创建集合并添加元素
Map<String,String> map = new HashMap<>();
map.put("1号丈夫","1号妻子");
map.put("2号丈夫","2号妻子");
map.put("3号丈夫","3号妻子");
map.put("4号丈夫","4号妻子");
map.put("5号丈夫","5号妻子");
//获取到所有的键
Set<String> keys = map.keySet();
//遍历Set集合得到每一个键
for (String key : keys) {
//通过每一个键key,来获取到对应的值
String value = map.get(key);
System.out.println(key + "---" + value);
}
}
}
3.4Map-第二种遍历方式【重点】(视频16) (8‘’)
方法介绍
| 方法名 | 说明 |
|---|---|
| Set<Map.Entry<K,V>>entrySet() | 获取所有键值对对象集合 |
| K getKey() | 获得键值 |
| V getValue() | 获得值 |

示例代码
package com.itheima.mapdemo1;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Map的第二种遍历方式
*/
public class MyMap4 {
public static void main(String[] args) {
//创建集合并添加元素
Map<String,String> map = new HashMap<>();
map.put("1号丈夫","1号妻子");
map.put("2号丈夫","2号妻子");
map.put("3号丈夫","3号妻子");
map.put("4号丈夫","4号妻子");
map.put("5号丈夫","5号妻子");
//首先要获取到所有的键值对对象。
//Set集合中装的是键值对对象(Entry对象)
//而Entry里面装的是键和值
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
//得到每一个键值对对象
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "---" + value);
}
}
}
4.HashMap集合
4.1HashMap-原理解析【难点】(视频17) (4'')
1.HashMap小结
HashMap底层是哈希表结构
依赖hashCode方法和equals方法保证键的唯一
如果键要存储自定义对象,需要重写hashCode和equals方法
4.2 HashMap集合-练习【重点】(视频18)(12‘’)
(共4点,第4点是对forEache的解析)
1.案例需求
创建一个HashMap集合,键是学生对象(Student),值是籍贯 (String)。存储三个元素,并遍历。
要求保证键的唯一性:如果学生对象的成员变量值相同,我们就认为是同一个对象
2.实现思路
定义学生类
创建HashMap集合对象
添加学生对象
为了保证key的一致性,重写学生类的hashCode和equals方法
3.代码实现
学生类
package com.itheima.mapdemo1;
public class Student{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
测试类
package com.itheima.mapdemo1;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Map的练习
*/
public class MyMap5 {
public static void main(String[] args) {
HashMap<Student,String> hm = new HashMap<>();
Student s1 = new Student("xiaohei",23);
Student s2 = new Student("dapang",22);
Student s3 = new Student("xiaomei",22);
hm.put(s1,"江苏");
hm.put(s2,"北京");
hm.put(s3,"天津");
//第一种:先获取到所有的键,再通过每一个键来找对应的值
Set<Student> keys = hm.keySet();
for (Student key : keys) {
String value = hm.get(key);
System.out.println(key + "----" + value);
}
System.out.println("===================================");
//第二种:先获取到所有的键值对对象。再获取到里面的每一个键和每一个值
Set<Map.Entry<Student, String>> entries = hm.entrySet();
for (Map.Entry<Student, String> entry : entries) {
Student key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "----" + value);
}
System.out.println("===================================");
//第三种:
hm.forEach(
(Student key, String value)->{
System.out.println(key + "----" + value);
}
);
}
}
4.forEach方法解析

5.TreeMap集合
5.1TreeMap-原理解析【了解】(视频19) (4'')
1.TreeMap-小结
TreeMap底层是红黑树结构
依赖自然排序或者比较器排序,对键进行排序
如果键存储的是自定义对象,需要实现Comparable接口或者在创建TreeMap对象时候给出比较器排序规则
5.2TreeMap集合应用案例【重点】(9‘’)
案例需求
创建一个TreeMap集合,键是学生对象(Student),值是籍贯(String),学生属性姓名和年龄,按照年龄进行排序并遍历
要求按照学生的年龄进行排序,如果年龄相同则按照姓名进行排序
实现思路
1.创建学生类
2.创建TreeMap集合对象
3.创建学生对象
4.添加学生对象
5.遍历输出
代码实现
学生类
package com.itheima.maptest;
public class Student/* implements Comparable<Student>*/{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
/* @Override
public int compareTo(Student o) {
//按照年龄进行排序
int result = o.getAge() - this.getAge();
//次要条件,按照姓名排序。
result = result == 0 ? o.getName().compareTo(this.getName()) : result;
return result;
}*/
}测试类
package com.itheima.maptest; import java.util.Comparator;
import java.util.TreeMap; /**
* 需求:创建一个TreeMap集合,键是学生对象(Student),值是籍贯(String)。
* 学生属性姓名和年龄,按照年龄进行排序并遍历。
*/
public class Test1 {
public static void main(String[] args) {
TreeMap<Student,String> tm = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int result = o1.getAge() - o2.getAge();
result = result== 0 ? o1.getName().compareTo(o2.getName()) : result;
return result;
}
}); Student s1 = new Student("xiaohei",23);
Student s2 = new Student("dapang",22);
Student s3 = new Student("xiaomei",22); tm.put(s1,"江苏");
tm.put(s2,"北京");
tm.put(s3,"天津"); tm.forEach(
(Student key, String value)->{
System.out.println(key + "---" + value);
}
);
}
}
==扩展练习==
题目1
假如你有3个室友,请使用HashSet集合保存3个室友的信息;
信息如下:
赵丽颖,18
范冰冰,20
杨幂,19
要求:
1:室友以对象形式存在,包含姓名和年龄两个属性;
2:使用代码保证集合中同名同年龄的对象只有一份;(相同姓名和年龄的对象认为是同一个对象)
效果:

参考答案:
测试类:
class Demo {
public static void main(String[] args) {
Student s1=new Student("赵丽颖",18);
Student s2=new Student("范冰冰",18);
Student s3=new Student("杨幂",19);
HashSet<Student> hs=new HashSet<>() ;
hs.add(s1);
hs.add(s2);
hs.add(s3);
System.out.println(hs);
}
}
类文件:
package day9.No_1;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
题目2
请使用HashMap集合保存街道两旁的店铺名称;使用门牌号作为键,店铺名作为值,然后使用三种方式遍历输出;
信息如下:
101,阿三面馆
102,阿四粥馆
103,阿五米馆
104,阿六快递
要求:
1:键是整数,值是字符串;
2:输出的信息使用"--"链接
效果:

参考答案:
package day9.No_2;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo {
public static void main(String[] args) {
HashMap<Integer,String>hs=new HashMap<>() ;
hs.put(101,"阿三面馆");
hs.put(102,"阿四粥馆");
hs.put(103,"阿五米馆");
hs.put(104,"阿六快递");
System.out.println("方式一遍历\t键值查找");
System.out.println("=================");
Set<Integer> keys = hs.keySet();
for (Integer key : keys) {
String value = hs.get(key);
System.out.println(key+"--"+value);
}
System.out.println("方式二遍历\t键值对对象");
System.out.println("=================");
Set<Map.Entry<Integer, String>> entries = hs.entrySet();
for (Map.Entry<Integer, String> entry : entries) {
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"--"+value);
}
System.out.println("方式三遍历\t使用接口");
System.out.println("=================");
hs.forEach(( i, s)->
System.out.println(i+"--"+s)
);//lambda简写格式
}
}
题目3(综合题,有难度)
请使用TreeMap集合保存劳模信息,要求以劳模对象为键,家庭住址为值,并按照劳模的年龄从大到小排序后输出;
信息如下:
18岁的张三,北京
20岁的李四,上海
35岁的王五,天津
21岁的赵六,北京
19岁的田七,上海
要求:
1:劳模类中有姓名和年龄两个属性;
2:添加上述信息后,使用代码删除张三的信息
3:添加上述信息后,使用代码修改李四的家庭住址为郑州
4:使用至少两种方式遍历集合中的信息并输出;
效果:

参考答案:
此方式只能集合从大到小的规则才可以使用
package day9.No_3;
import java.util.*;
public class Demo {
public static void main(String[] args) {
Student s2 = new Student("李四", 24);
Student s1 = new Student("张三", 23);
Student s3 = new Student("王五", 25);
Student s4 = new Student("赵六", 26);
TreeMap<Student, String> ts = new TreeMap<>();
ts.put(s1, "北京");
ts.put(s2, "上海");
ts.put(s3, "广东");
ts.put(s4, "深圳");
Set<Student> keySet = ts.keySet();
try {
for (Student key : keySet) {
//使用代码删除张三的信息
// 此时我们并没有使用迭代器删除方式,直接调用TreeMap集合方法进行了删除
//但是只能删除从大到小排序规则的集合,不可以删除从小到大规则排序的集合
if (key.getName().equals("张三")) {
ts.remove(key);
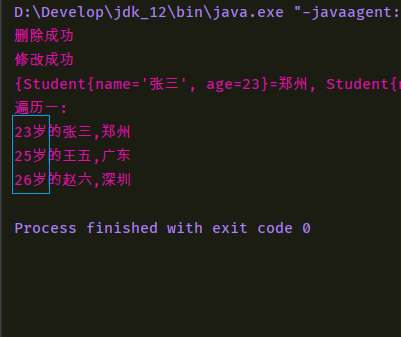
System.out.println("删除成功!");
}
}
} catch (Exception e) {
System.out.println("删除失败!违背了迭代器原理!可以试试集合倒着写");
}
for (Student key : keySet) {
//使用代码修改李四的家庭住址为郑州
if (key.getName().equals("李四")) {
//增强for方法底层是迭代器遍历方式,不能修改set集合元素,
// 而我们修改的是treeMap,所以并没有违背迭代器不能修改的原则
ts.put(key, "郑州");
System.out.println("修改成功");
}
}
System.out.println(ts);
System.out.println("遍历一:");
for (Student key : keySet) {
String value = ts.get(key);
System.out.println(key.getAge() + "岁的" + key.getName() + "," + value);
}
}
public static void Bianli(TreeMap<Student, String> ts) {
System.out.println("遍历二:");
ts.forEach((Student key,String value)->{
System.out.println(key.getAge()+"岁的"+key.getName()+","+value);
});
System.out.println("遍历三:");
Set<Map.Entry<Student, String>> entries = ts.entrySet();
for (Map.Entry<Student, String> entry : entries) {
Student key = entry.getKey();
String value = entry.getValue();
System.out.println(key.getAge()+"岁的"+key.getName()+","+value);
}
}
}
迭代器进行删除修改:
package day9.No_3;
import java.util.*;
public class Demo1 {
public static void main(String[] args) {
Student s1 = new Student("张三", 23);
Student s2 = new Student("李四", 24);
Student s3 = new Student("王五", 25);
Student s4 = new Student("赵六", 26);
TreeMap<Student, String> ts = new TreeMap<>();
ts.put(s1, "北京");
ts.put(s2, "上海");
ts.put(s3, "广东");
ts.put(s4, "深圳");
Set<Student> keySet = ts.keySet();
Iterator<Student> iterator1 = keySet.iterator();
while (iterator1.hasNext()) {
Student key = iterator1.next();
if (key.getName().equals("李四")) {
iterator1.remove();
System.out.println("删除成功");
}
}
/*//bug代码:
Iterator<Student> iterator = keySet.iterator();
while (iterator.hasNext()) {
if (iterator.next().getName().equals("张三")) {
ts.put(iterator.next(), "郑州");
}//此逻辑不会编译报错,运行也不报错,但是逻辑不通,,但是会修改到下一个key的值,迭代器的默认指向下一个原理
}*/
/* for (Student key : keySet) {
if (key.getName().equals("张三")){
ts.put(key,"郑州");//该方法也可以对值进行修改
}
}*/
Iterator<Student> iterator = keySet.iterator();
while (iterator.hasNext()) {
Student key = iterator.next();
if (key.getName().equals("张三")) {
ts.put(key, "郑州");
System.out.println("修改成功");
}
}
System.out.println(ts);
System.out.println("遍历一:");
for (Student key : keySet) {
String value = ts.get(key);
System.out.println(key.getAge() + "岁的" + key.getName() + "," + value);
}
}
public static void Bianli(TreeMap<Student, String> ts) {
System.out.println("遍历二:");
ts.forEach((Student key, String value) -> {
System.out.println(key.getAge() + "岁的" + key.getName() + "," + value);
});
System.out.println("遍历三:");
Set<Map.Entry<Student, String>> entries = ts.entrySet();
for (Map.Entry<Student, String> entry : entries) {
Student key = entry.getKey();
String value = entry.getValue();
System.out.println(key.getAge() + "岁的" + key.getName() + "," + value);
}
}
}
类文件:
package day9.No_3;
import java.text.Collator;
import java.util.Locale;
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student o) {
int i = this.age - o.age;
Collator instance = Collator.getInstance(Locale.CHINESE);
i=i==0?instance.compare(this.name,o.name):i;
return -i;//因为要从大到小,而默认规则是从小到大,排序根据返回的正负数排的,所以直接加负可以直接改变大小原则
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
运行效果:
红黑树规则,TreeSet原理,HashSet特点,什么是哈希值,HashSet底层原理,Map集合特点,Map集合遍历方法的更多相关文章
- 红黑树之 原理和算法详细介绍(阿里面试-treemap使用了红黑树) 红黑树的时间复杂度是O(lgn) 高度<=2log(n+1)1、X节点左旋-将X右边的子节点变成 父节点 2、X节点右旋-将X左边的子节点变成父节点
红黑树插入删除 具体参考:红黑树原理以及插入.删除算法 附图例说明 (阿里的高德一直追着问) 或者插入的情况参考:红黑树原理以及插入.删除算法 附图例说明 红黑树与AVL树 红黑树 的时间复杂度 ...
- 关于红黑树(R-B tree)原理,看这篇如何
学过数据数据结构都知道二叉树的概念,而又有多种比较常见的二叉树类型,比如完全二叉树.满二叉树.二叉搜索树.均衡二叉树.完美二叉树等:今天我们要说的红黑树就是就是一颗非严格均衡的二叉树,均衡二叉树又是在 ...
- Java - TreeMap源码解析 + 红黑树
Java提高篇(二七)-----TreeMap TreeMap的实现是红黑树算法的实现,所以要了解TreeMap就必须对红黑树有一定的了解,其实这篇博文的名字叫做:根据红黑树的算法来分析TreeMap ...
- 红黑树(R-B Tree)
R-B Tree简介 R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树.红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black). ...
- JAVA数据结构之红-黑树
本篇博客我会重点介绍对红-黑树的理解,重点介绍红-黑树的查找,这里我们将要讨论的算法称为自顶向下插入,也就是把沿着树向下查找插入点 Ⅰ.平衡树和非平衡树 平衡树和非平衡树:当插入一组数据关键字是按照升 ...
- Java 1.8 红黑树
红黑树 R-B Tree R-B Tree,全称 Red-Black Tree 又称为 红黑树,它是一种特殊的二叉查找树,红黑树的每个节点都有存储位表示节点的颜色,可以是红Red 或者 黑Black ...
- 算法设计和数据结构学习_5(BST&AVL&红黑树简单介绍)
前言: 节主要是给出BST,AVL和红黑树的C++代码,方便自己以后的查阅,其代码依旧是data structures and algorithm analysis in c++ (second ed ...
- BST&AVL&红黑树简单介绍
(BST&AVL&红黑树简单介绍) 前言: 节主要是给出BST,AVL和红黑树的C++代码,方便自己以后的查阅,其代码依旧是data structures and algorithm ...
- 死磕 java集合之TreeMap源码分析(三)- 内含红黑树分析全过程
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 删除元素 删除元素本身比较简单,就是采用二叉树的删除规则. (1)如果删除的位置有两个叶子节点 ...
随机推荐
- dubbo起停之服务暴露
由上一节可知带上dubbo@Service注解的对象,在注册成为bean之后会进一步注册一个ServiceBean,服务暴露便是在这里 public void afterPropertiesSet() ...
- 跟随杠精的视角一起来了解Redis的主从复制
不想弹好吉他的撸铁狗,都不是好的程序猿 虽然说单机的Redis性能很好,也有完备的持久化机制,那如果你的业务体量真的很大,超过了单机能够承载的上限了怎么办?不做任何处理的话Redis挂了怎么办?带着这 ...
- volatile禁止重排使用场景与单例模式的Double Check Lock
普通单例模式Demo public class Demo{ private static Demo INSTANCE; private Demo(){} public static Demo getI ...
- 音视频入门-18-手动生成一张GIF图片
* 音视频入门文章目录 * GIF 编码知识 GIF 包含的数据块: 文件头(Header) 逻辑屏幕标识符(Logical Screen Descriptor) 全局颜色表(Global Color ...
- fist-第七天冲刺随笔
这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE1 这个作业要求在哪里 https://edu.cnblogs.com/campus/fz ...
- 【五校联考1day2】JZOJ2020年8月12日提高组T1 对你的爱深不见底
[五校联考1day2]JZOJ2020年8月12日提高组T1 对你的爱深不见底 题目 Description 出乎意料的是,幸运E 的小R 居然赢了那个游戏.现在欣喜万分的小R 想要写一张明信片给小Y ...
- 部署完的Django项目升级为HTTPS
1.阿里云上申请免费ssl证书--->提交各种资料--->等待审核--->下载证书. 2.远程连接阿里云服务器,将下载下来的证书内容复制到Nginx安装目录下的cert目录(需要新建 ...
- 第10.3节 Python导入模块能否取消导入?
模块导入后,是否可以取消导入?实际上当模块导入后,是无法逆向还原到导入前的状态的,但是可以利用"del 模块名"进行导入模块的删除,此时的删除只是删除了导入模块对应的模块变量名,删 ...
- 【Vue】 axios同步执行多个请求
问题 项目中遇到一个需求,在填写商品的时候,选择商品分类后,加载出商品分类的扩展属性. 这个扩展属性有可能是自定义的数据字典里的单选/多远. 要用第一个axios查询扩展属性,第二个axios 从第一 ...
- C#清除HTML标签方法
删除字符串中HTML标签代码 public static string ClearHTMLTags1(string HTML) { string[] Regexs ={ @"<scri ...