爬虫学习(二)requests模块的使用
一、requests的概述
requests模块是用于发送网络请求,返回响应数据。底层实现是urllib,而且简单易用,在python2、python3中通用,能够自动帮助我们解压(gzip压缩的等)网页内容。
二、requests的基本使用
1、基本使用:
- 安装requests模块:
pip install requests - 导入模块:
import reqeusts - 发送请求,获取响应:response = requests.get(url)
- 从响应中获取数据
2、方法:
(1)requests.get(url, params=None, **kwargs),发送一个get请求,返回一个Response对象
- url:请求的url
- params:get请求的?后面可选参数字典
方式一:自己拼接一个带有参数的URL,比如"https://www.sogou.com/web?query={}"
方式二:在发送请求时,使用params指定,格式requests.get("url", params={}) - **kwargs:可选参数
headers:请求头参数字典。
# 请求头格式
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
}
requests.get(url, headers=headers)proxies:代理参数字典。
# 代理格式
proxies = {
"http": "http://ip:端口号",
"https": "https://ip:端口号"
}
requests.get(url, proxies=proxies) # 使用需要账号和密码的代理
proxies = {
"http":"http://username:password@ip:端口号",
"https": "https://username:password@ip:端口号"
}
request.get(url, proxies=proxies)cookies:cookies参数字典。
verify:请求SSL证书验证。
timeout:设置超时。能够加快整体的请求速度。
(2)requests.post(url, data=None, json=None, **kwargs),发送一个post请求
- url:
- data:
- json:
- **kwargs:可选参数
headers:请求头参数字典
proxies:代理参数字典。
cookies:cookies参数字典。
(3)requests.util.dict_from_cookiejar(cj):把cookie对象转化为字典
- cj:cookie对象(response.cookies)
(4)requests.util.quote(url):URL编码
(5)requests.util.unquote(url):URL解密
3、对象:
(1)Response对象,是发送请求后的响应对象
常用属性:
- Response.text:str类型的响应数据
- Response.content:二进制类型的响应数据
- Response.status_code:响应状态码
- Response.headers:响应头
- Response.request.headers:请求头
- Response.json() :获取json类型的响应数据,如果返回的数据不是json类型就不能使用
三、代理
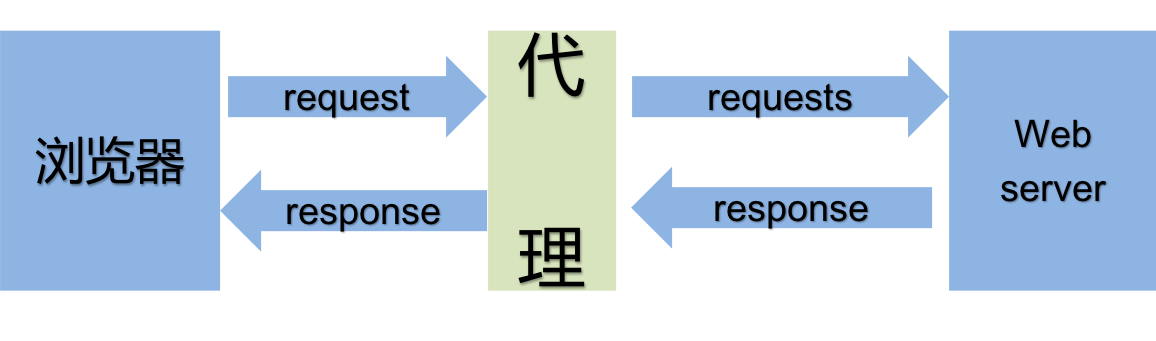
在requests模块中使用代理发送请求的原因是:如果使用一个固定IP不断的发送请求,服务器会认为这样的操作不是人干的,就把你的IP给封了,而且还会根据你的IP快速锁定你。
代理的分类:
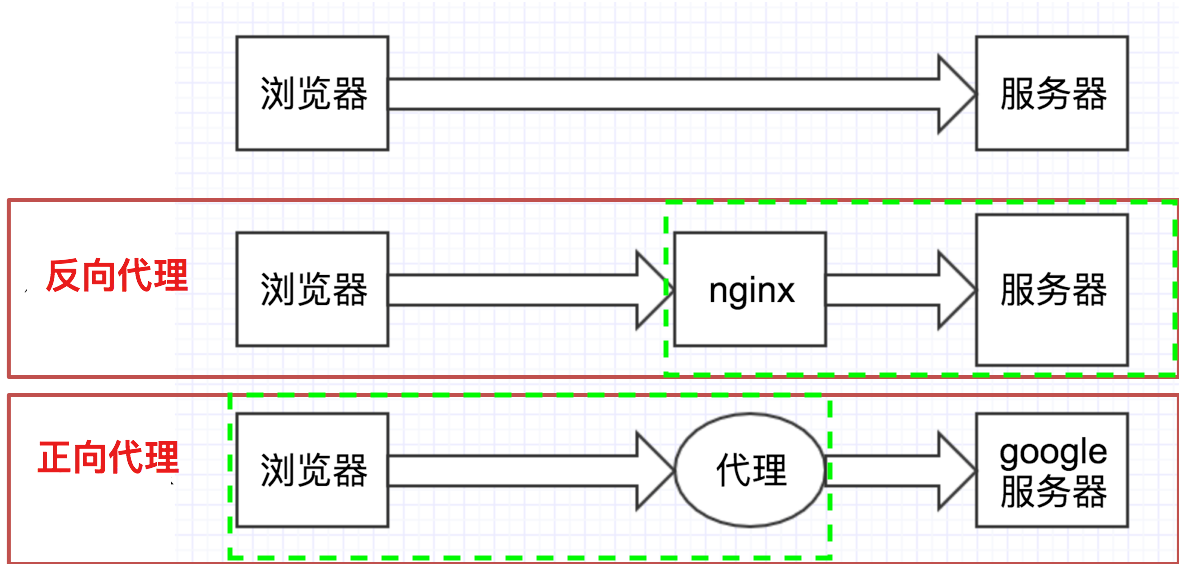
1、正向代理:
- 客户端知道代理的存在,正向代理是为了保护客户端,防止被追踪。
- 服务端不知道真实的客户端。
2、反向代理:
- 服务器端知道代理的存在,反向代理是为了保护服务器或负责负载均衡。
- 客户端不知道代理的存在。

代理IP的分类
1、根据匿名程度:
- 透明代理:透明代理虽然可以直接隐藏你的IP地址,但是还是可以查到你是谁。
- 匿名代理:别人只能知道你用了代理,无法知道你是谁。
- 高匿代理:让别人根本无法发现你是在用代理,所以是最好的选择。
2、根据请求的协议:
- http代理
- https代理
- socket代理
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择。
使用代理IP的注意点:
- 反反爬:使用代理IP时使用随机的方式进行选择使用,不要每次都使用一个代理IP。
- 更新代理IP池:购买的代理IP很多时候大部分可能无法使用了,需要通过程序去检验哪些可用,把不能用的删除掉。
import random
import requests
# 1. 准备代理列表
proxies = [
{'http': '121.8.98.198:80'},
{'http': '39.108.234.144:80'},
{'http': '125.120.201.68:808'},
{'http': '120.24.216.39:60443'},
{'http': '121.8.98.198:80'},
{'http': '121.8.98.198:80'}
] # 2. 随机选出一个代理
for i in range(0, 10):
proxy = random.choice(proxies)
print(proxy)
try:
response = requests.get("http://www.baidu.com", proxies=proxy, timeout=3)
print(response.status_code)
except Exception as ex:
print("代理有问题: %s" % proxy)
四、获取服务器端登录后的资源
三种方式:
- 发送请求的时候,在headers中指定cookie字符串。
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
# "Cookie": cookie_str
} - 发送请求的时候,通过cookies参数指定,是一个字典。
response = requests.get(url, headers= headers, cookies=cookie_dic)
- 使用session进行登录,登录后使用session访问登录后资源,这时session会自动携带cookie信息。
import requests # 1. 获取session对象
session = requests.session() headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
} # 2. 使用session对象,进行登录,登录后seesion对象会记录用户相关的cookie信息
login_url = "http://www.renren.com/PLogin.do"
data = {
"email":"15565280933",
"password":"a123456"
} response = session.post(login_url, data=data, headers=headers)
print(response.status_code)
print(response.content.decode())
# 3. 再使用记录cookie信息对象session访问个人主页
profile_url = "http://www.renren.com/965194180/profile"
response = session.get(profile_url)
五、retrying模块的使用
如果访问速度很慢,可以选择刷新页面,在代码中使用retrying模块刷新请求,通过装饰器的方式,让被装饰的函数反复执行。
@retry(stop_max_attempt_number=3),让函数报错后继续重新执行,达到最大执行次数的上限,如果每次都报错,整个函数报错,如果中间有一个成功,程序继续往后执行
- stop_max_attempt_number:最大重试次数。
import requests
from retrying import retry headers = {} #最大重试3次,3次全部报错,才会报错
@retry(stop_max_attempt_number=3)
def _parse_url(url)
#超时的时候会报错并重试
response = requests.get(url, headers=headers, timeout=3)
#状态码不是200,也会报错并重试
assert response.status_code == 200
return response def parse_url(url)
try: #进行异常捕获
response = _parse_url(url)
except Exception as e:
print(e)
#报错返回None
response = None
return response
爬虫学习(二)requests模块的使用的更多相关文章
- python网络爬虫之二requests模块
requests http请求库 requests是基于python内置的urllib3来编写的,它比urllib更加方便,特别是在添加headers, post请求,以及cookies的设置上,处理 ...
- Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档. Requests具有完备的中英文文档, 能完全满 ...
- 爬虫简介与requests模块
爬虫简介与requests模块 一 爬虫简介 概述 网络爬虫是一种按照一定规则,通过网页的链接地址来寻找网页的,从网站某一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这 ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- 爬虫二 requests模块的使用
一.requests模块的介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:reques ...
- 爬虫入门之Requests模块学习(四)
1 Requests模块解析 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用 Requests 继承了urllib2的所有特性.Requests支持HTTP连接保 ...
- 爬虫开发5.requests模块的cookie和代理操作
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- 爬虫开发3.requests模块
requests模块 - 基于如下5点展开requests模块的学习 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能 ...
- 爬虫中之Requests 模块的进阶
requests进阶内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个 ...
- 爬虫简介和requests模块
目录 爬虫介绍 requests模块 requests模块 1.requests模块的基本使用 2.get 请求携带参数,调用params参数,其本质上还是调用urlencode 3.携带header ...
随机推荐
- 我是如何用go-zero 实现一个中台系统的
最近发现golang社区里出了一个新星的微服务框架,来自好未来,光看这个名字,就很有奔头,之前,也只是玩过go-micro,其实真正的还没有在项目中运用过,只是觉得 微服务,grpc 这些很高大尚,还 ...
- virtualbox sharefolder mount fail
ubuntu 14.04.1 LTS 64bit 安装完GuestAdditions后,在终端输入 sudo mount -t vboxsf sharename /mnt/share 提示错误:mou ...
- yii2 设置的缓存无效,返回false,不存在
为了那些因为标题点进来的小伙伴,我直接把问题解决方案写在开头: 问题描述, $cache->add($key,'value',1800);这样设置了值后,后面无论怎么取这个$key,取出来的结果 ...
- 图数据库 Nebula Graph 在 Boss 直聘的应用
本文首发于 Nebula Graph 官方博客:https://nebula-graph.com.cn/posts/nebula-graph-risk-control-boss-zhipin/ 摘要: ...
- Python 写了一个批量生成文件夹和批量重命名的工具
Python 写了一个批量生成文件夹和批量重命名的工具 目录 Python 写了一个批量生成文件夹和批量重命名的工具 演示 功能 1. 可以读取excel内容,使用excel单元格内容进行新建文件夹, ...
- C#中使用NPOI提示(找到的程序集清单定义与程序集引用不匹配)
问题 找到的程序集清单定义与程序集引用不匹配. (异常来自 HRESULT:0x80131040) 描述 使用NPOI导出word文档,需要C#的解压缩类,所以引用了ICSharpCode.Sharp ...
- 写一个nginx.conf方便用于下载某个网页的所有资源
写一个nginx.conf方便用于下载某个网页的所有资源 worker_processes 1; events { worker_connections 1024; } http { include ...
- python初学者-使用for循环用四位数组成不同的数
digits = (1,2,3,4) for i in digits: for j in digits: if j==i: continuefor k in digits: if k==i or k= ...
- 2.mysql explain命令详解
EXPLAIN详解 SQL编写和解析 编写过程 select-distinct-from-join-on-where-group by-having-order by-limit- 解析过程 from ...
- [每日一题]ES6中为什么要使用Symbol?
关注「松宝写代码」,精选好文,每日面试题 加入我们一起学习,day day up 作者:saucxs | songEagle 来源:原创 一.前言 2020.12.23日刚立的flag,每日一题,题目 ...