JVM的方法执行引擎-entry point栈帧
接着上一篇去讲,回到JavaCalls::call_helper()中:
address entry_point = method->from_interpreted_entry();
entry_point是从当前要执行的Java方法中获取的,定义如下:
源代码位置:/openjdk/hotspot/src/share/vm/oops/method.hpp
volatile address from_interpreted_entry() const{
return (address)OrderAccess::load_ptr_acquire(&_from_interpreted_entry);
}
那么_from_interpreted_entry是何时赋值的?之前在介绍方法连接时简单介绍过,在method.hpp中有这样一个set方法:
void set_interpreter_entry(address entry) {
_i2i_entry = entry;
_from_interpreted_entry = entry;
}
在连接方法时通过如下的方法调用上面的方法:
// Called when the method_holder is getting linked. Setup entrypoints so the method
// is ready to be called from interpreter, compiler, and vtables.
void Method::link_method(methodHandle h_method, TRAPS) {
// ...
address entry = Interpreter::entry_for_method(h_method);
assert(entry != NULL, "interpreter entry must be non-null");
// Sets both _i2i_entry and _from_interpreted_entry
set_interpreter_entry(entry);
// ...
}
根据注释都可以得知,当方法连接时,会去设置方法的entry_point,entry_point是通过调用Interpreter::entry_for_method()方法得到,这个方法的实现如下:
static address entry_for_method(methodHandle m) {
return entry_for_kind(method_kind(m));
}
首先通过method_kind()拿到方法类型,然后调用entry_for_kind()方法根据方法类型获取方法入口entry point。调用的entry_for_kind()方法如下:
static address entry_for_kind(MethodKind k){
return _entry_table[k];
}
这里直接返回了_entry_table数组中对应方法类型的entry_point地址。给数组中元素赋值专门有个方法:
void AbstractInterpreter::set_entry_for_kind(AbstractInterpreter::MethodKind kind, address entry) {
_entry_table[kind] = entry;
}
那么何时会调用set_entry_for_kind ()呢,答案就在TemplateInterpreterGenerator::generate_all()中,generate_all()会调用generate_method_entry()去生成每种方法的entry_point,所有Java方法的执行,都会通过对应类型的entry_point例程来辅助。下面来详细介绍一下generate_all()方法的实现逻辑。
HotSpot在启动时,会为所有字节码创建在特定目标平台上运行的机器码,并存放在CodeCache中,在解释执行字节码的过程中,就会从CodeCache中取出这些本地机器码并执行。
在启动虚拟机阶段会调用init_globals()方法初始化全局模块,在这个方法中通过调用interpreter_init()方法初始化模板解释器,调用栈如下:
TemplateInterpreter::initialize() templateInterpreter.cpp
interpreter_init() interpreter.cpp
init_globals() init.cpp
Threads::create_vm() thread.cpp
JNI_CreateJavaVM() jni.cpp
InitializeJVM() java.c
JavaMain() java.c
start_thread() pthread_create.c
interpreter_init()方法主要是通过调用TemplateInterpreter::initialize()方法来完成逻辑,initialize()方法的实现如下:
源代码位置:/src/share/vm/interpreter/templateInterpreter.cpp
void TemplateInterpreter::initialize() {
if (_code != NULL)
return;
// 抽象解释器AbstractInterpreter的初始化,AbstractInterpreter是基于汇编模型的解释器的共同基类,
// 定义了解释器和解释器生成器的抽象接口
AbstractInterpreter::initialize();
// 模板表TemplateTable的初始化,模板表TemplateTable保存了各个字节码的模板
TemplateTable::initialize();
// generate interpreter
{
ResourceMark rm;
int code_size = InterpreterCodeSize;
// CodeCache的Stub队列StubQueue的初始化
_code = new StubQueue(new InterpreterCodeletInterface, code_size, NULL,"Interpreter");
// 实例化模板解释器生成器对象TemplateInterpreterGenerator
InterpreterGenerator g(_code);
}
// initialize dispatch table
_active_table = _normal_table;
}
模板解释器的初始化包括如下几个方面:
(1)抽象解释器AbstractInterpreter的初始化,AbstractInterpreter是基于汇编模型的解释器的共同基类,定义了解释器和解释器生成器的抽象接口。
(2)模板表TemplateTable的初始化,模板表TemplateTable保存了各个字节码的模板(目标代码生成函数和参数);
(3)CodeCache的Stub队列StubQueue的初始化;
(4)解释器生成器InterpreterGenerator的初始化。
在执行InterpreterGenerator g(_code)代码时,调用InterpreterGenerator的构造函数,如下:
InterpreterGenerator::InterpreterGenerator(StubQueue* code) : TemplateInterpreterGenerator(code) {
generate_all(); // down here so it can be "virtual"
}
调用的generate_all()方法将生成一系列HotSpot运行过程中所执行的一些公共代码的入口和所有字节码的InterpreterCodelet。这些入口包括:
- error exits:出错退出处理入口
- 字节码追踪入口(配置了-XX:+TraceBytecodes)
- 函数返回入口
- JVMTI的EarlyReturn入口
- 逆优化调用返回入口
- native调用返回值处理handlers入口
- continuation入口
- safepoint入口
- 异常处理入口
- 抛出异常入口
- 方法入口(native方法和非native方法)
- 字节码入口
部分重要的入口实现逻辑会在后面详细介绍,这里只看为非native方法入口(也就是普通的、没有native关键字修饰的Java方法)生成入口的逻辑。generate_all()方法中有如下调用语句:
#define method_entry(kind) \
{ \
CodeletMark cm(_masm, "method entry point (kind = " #kind ")"); \
Interpreter::_entry_table[Interpreter::kind] = generate_method_entry(Interpreter::kind); \
} method_entry(zerolocals)
其中method_entry是宏,扩展后如上的调用语句变为如下的形式:
Interpreter::_entry_table[Interpreter::zerolocals] = generate_method_entry(Interpreter::zerolocals);
_entry_table变量定义在AbstractInterpreter类中,如下:
// method entry points
static address _entry_table[number_of_method_entries]; // entry points for a given method
number_of_method_entries表示方法类型的总数,使用方法类型做为数组下标就可以获取对应的方法入口。调用generate_method_entry()方法为各个类型的方法生成对应的方法入口,实现如下:
address AbstractInterpreterGenerator::generate_method_entry(AbstractInterpreter::MethodKind kind) {
// determine code generation flags
bool synchronized = false;
address entry_point = NULL;
InterpreterGenerator* ig_this = (InterpreterGenerator*)this;
switch (kind) { // 根据方法类型kind生成不同的入口
case Interpreter::zerolocals : // zerolocals表示普通方法类型
break;
case Interpreter::zerolocals_synchronized: // zerolocals表示普通的、同步方法类型
synchronized = true;
break;
// ...
}
if (entry_point) {
return entry_point;
}
return ig_this->generate_normal_entry(synchronized);
}
zerolocals表示正常的Java方法调用(包括Java程序的主函数),对于zerolocals来说,会调用ig_this->generate_normal_entry()方法生成入口。generate_normal_entry()方法会为执行的方法生成堆栈,而堆栈由局部变量表(用来存储传入的参数和被调用函数的局部变量)、帧数据和操作数栈这三大部分组成,所以方法会创建这3部分来辅助Java方法的执行。
之前在介绍CallStub栈帧时讲到过,如果要执行entry_point,那么栈帧的状态就如下图所示。
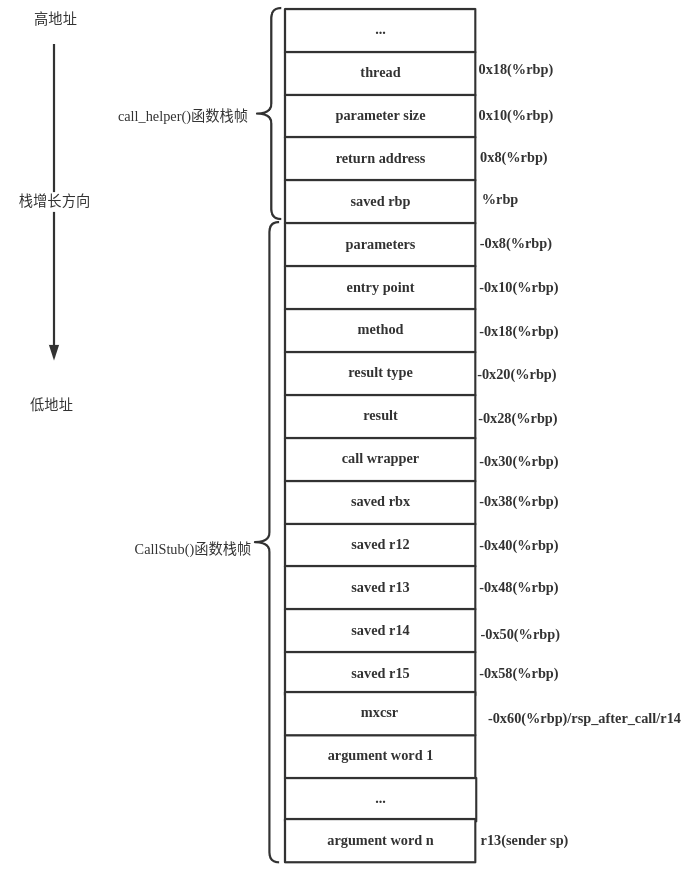
/src/cpu/x86/vm/templateInterpreter_x86_64.cpp文件中generate_normal_entry()方法在通过CallStub调用时,各个寄存器的状态如下:
rbx -> Method*
r13 -> sender sp
rsi -> entry point
generate_normal_entry()方法的实现如下:
// Generic interpreted method entry to (asm) interpreter
address InterpreterGenerator::generate_normal_entry(bool synchronized) {
// determine code generation flags
bool inc_counter = UseCompiler || CountCompiledCalls; // 执行如下方法前的寄存器中保存的值如下:
// ebx: Method*
// r13: sender sp
address entry_point = __ pc(); // entry_point函数的代码入口地址 // 当前rbx中存储的是指向Method的指针,通过Method*找到ConstMethod*
const Address constMethod(rbx, Method::const_offset());
// 通过Method*找到AccessFlags
const Address access_flags(rbx, Method::access_flags_offset());
// 通过ConstMethod*得到parameter的大小
const Address size_of_parameters(rdx,ConstMethod::size_of_parameters_offset());
// 通过ConstMethod*得到local变量的大小
const Address size_of_locals(rdx, ConstMethod::size_of_locals_offset()); // 上面已经说明了获取各种方法元数据的计算方式,但并没有执行计算,下面会生成对应的汇编来执行计算
// get parameter size (always needed)
__ movptr(rdx, constMethod); // 计算ConstMethod*,保存在rdx里面
__ load_unsigned_short(rcx, size_of_parameters); // 计算parameter大小,保存在rcx里面
//rbx:保存基址;rcx:保存循环变量;rdx:保存目标地址;rax:保存返回地址(下面用到) // 此时的各个寄存器中的值如下:
// rbx: Method*
// rcx: size of parameters
// r13: sender_sp (could differ from sp+wordSize if we were called via c2i ) 即调用者的栈顶地址
// 计算local变量的大小,保存到rdx
__ load_unsigned_short(rdx, size_of_locals);
// 由于局部变量表用来存储传入的参数和被调用函数的局部变量,所以rdx减去rcx后就是被调用函数的局部变量可使用的大小
__ subl(rdx, rcx); // see if we've got enough room on the stack for locals plus overhead.
generate_stack_overflow_check(); //返回地址是在call_stub中保存的,如果不弹出堆栈到rax,那么局部变量区就如下面的样子:
// [parameter 1]
// [parameter 2]
// ......
// [parameter n]
// [return address]
// [local 1]
// [local 2]
// ...
// [local n]
// 显然中间有个return address使的局部变量表不是连续的,这会导致其中的局部变量计算方式不一致,所以暂时将返回地址存储到rax中
// get return address
__ pop(rax); // compute beginning of parameters (r14)
// 计算第1个参数的地址:当前栈顶地址 + 变量大小 * 8 - 一个字大小。
// 这儿注意,因为地址保存在低地址上,而堆栈是向低地址扩展的,所以只需加n-1个变量大小就可以得到第1个参数的地址。
__ lea(r14, Address(rsp, rcx, Address::times_8, -wordSize)); // 把函数的局部变量全置为0,也就是做初始化,防止之前遗留下的值影响
// rdx:被调用函数的局部变量可使用的大小
// allocate space for locals
// explicitly initialize locals
{
Label exit, loop;
__ testl(rdx, rdx);
__ jcc(Assembler::lessEqual, exit); // do nothing if rdx <= 0
__ bind(loop);
__ push((int) NULL_WORD); // initialize local variables
__ decrementl(rdx); // until everything initialized
__ jcc(Assembler::greater, loop);
__ bind(exit);
} // 生成固定桢
// initialize fixed part of activation frame
generate_fixed_frame(false); // 省略统计及栈溢出等逻辑,后面会详细介绍 // check for synchronized methods
// Must happen AFTER invocation_counter check and stack overflow check,
// so method is not locked if overflows.
if (synchronized) {
// Allocate monitor and lock method
lock_method();
} else {
// no synchronization necessary
} // 省略统计相关逻辑,后面会详细介绍 return entry_point;
}
要对偏移的计算进行研究,如下:
// 当前rbx中存储的是指向Method的指针,通过Method*找到ConstMethod*
const Address constMethod(rbx, Method::const_offset());
// 通过Method*找到AccessFlags
const Address access_flags(rbx, Method::access_flags_offset());
// 通过ConstMethod*得到parameter的大小
const Address size_of_parameters(rdx,ConstMethod::size_of_parameters_offset());
// 通过ConstMethod*得到local变量的大小
const Address size_of_locals(rdx, ConstMethod::size_of_locals_offset());
如果要打印这个方法生成的汇编代码,可以在方法的return语句之前添加如下2句打印代码:
address end = __ pc();
Disassembler::decode(entry_point, end);
这样,在执行Disassembler::decode()方法时,会将此方法生成的机器码转换为汇编打印到控制台上。
调用generate_fixed_frame()方法之前生成的汇编代码如下:
Loaded disassembler from /home/mazhi/workspace/openjdk/build/linux-x86_64-normal-server-slowdebug/jdk/lib/amd64/server/hsdis-amd64.so
[Disassembling for mach='i386:x86-64']
0x00007fffe101e2e0: mov 0x10(%rbx),%rdx // 通过%rbx中保存的Method*找到ConstMethod并保存到%rdx
0x00007fffe101e2e4: movzwl 0x2a(%rdx),%ecx // 通过ConstMethod*找到入参数量保存在%ecx
0x00007fffe101e2e8: movzwl 0x28(%rdx),%edx // 通过ConstMethod*找到本地变量表大小保存在%edx
0x00007fffe101e2ec: sub %ecx,%edx // 计算方法局部变量可使用的本地变量空间的大小并保存在%edx // ... 省略调用generate_stack_overflow_check()方法生成的汇编 0x00007fffe101e43d: pop %rax // 弹出返回地址
0x00007fffe101e43e: lea -0x8(%rsp,%rcx,8),%r14 // 计算第一个参数的地址
// 为局部变量slot(不包括方法入参)分配堆栈空间并初始化为0
// 循环进行本地变量表空间的开辟
// -- loop --
0x00007fffe101e443: test %edx,%edx
0x00007fffe101e445: jle 0x00007fffe101e454 // 由于%edx的大小等于0,所以不需要额外分配,直接跳转到exit
0x00007fffe101e44b: pushq $0x0
0x00007fffe101e450: dec %edx
0x00007fffe101e452: jg 0x00007fffe101e44b // 如果%edx的大小不等于0,跳转到loop
现在栈的状态如下图所示。

现在r14指向局部变量开始的位置,而argument和local variable都存储在了局部变量表,rbp指向了局部变量表结束位置。现在各个寄存器的状态如下:
rax: return address // %rax寄存器中存储的是返回地址return address
rbx: Method*
r14: pointer to locals
r13: sender sp
在InterpreterGenerator::generate_normal_entry()函数中,接下来会以这样的状态调用generate_fixed_frame()函数来创建Java方法运行时所需要的栈帧。generate_fixed_frame()函数会在下一篇详细介绍。
调用后栈帧变为如下的状态:
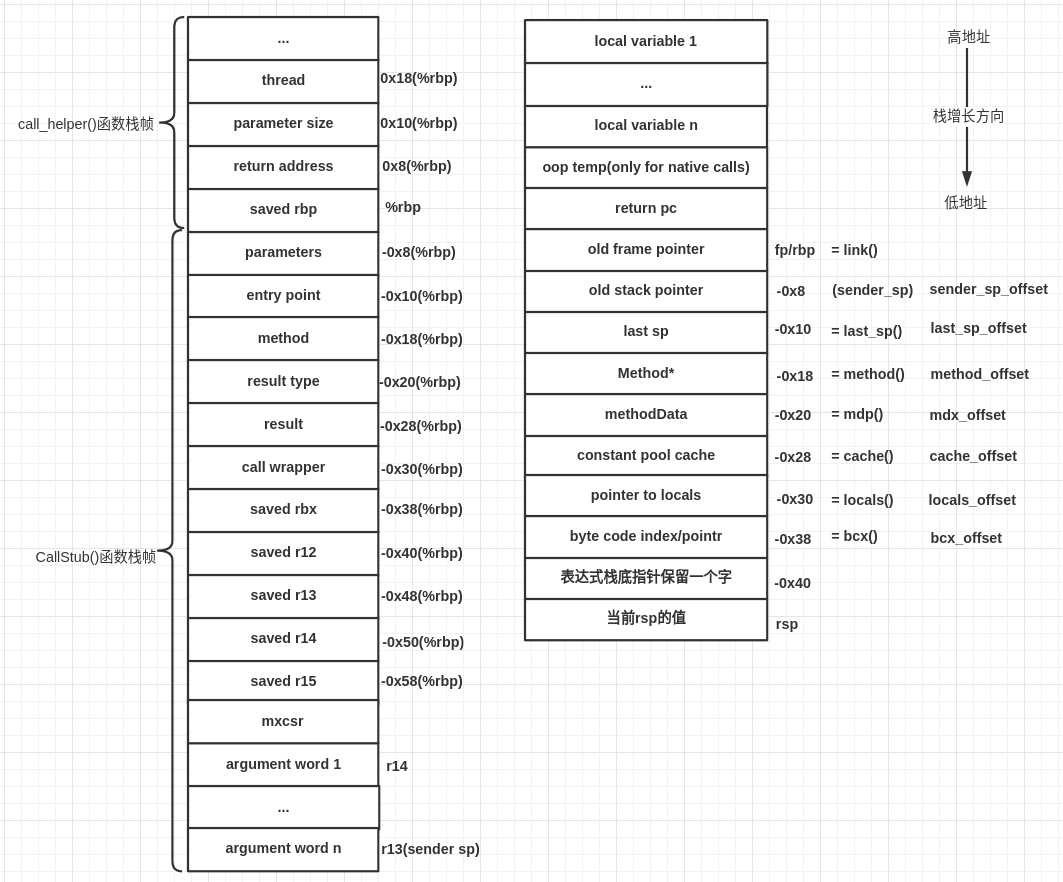
上图右边的栈状态随着具体方法的不同会显示不同的状态,不过大概的状态就是上图所示的样子。
调用完generate_fixed_frame()方法后一些寄存器中保存的值如下:
rbx:Method*
ecx:invocation counter
r13:bcp(byte code pointer)
rdx:ConstantPool* 常量池的地址
r14:本地变量表第1个参数的地址
执行完generate_fixed_frame()方法后会继续执行InterpreterGenerator::generate_normal_entry()函数,如果是为同步方法生成机器码,那么还需要调用lock_method()方法,这个方法会改变当前栈的状态,添加同步所需要的一些信息,在后面介绍锁的实现时会详细介绍。
InterpreterGenerator::generate_normal_entry()函数最终会返回生成机器码的入口执行地址,然后通过变量_entry_table数组来保存,这样就可以使用方法类型做为数组下标获取对应的方法入口了。
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
13、类加载器
14、类的双亲委派机制
15、核心类的预装载
16、Java主类的装载
17、触发类的装载
18、类文件介绍
19、文件流
20、解析Class文件
21、常量池解析(1)
22、常量池解析(2)
23、字段解析(1)
24、字段解析之伪共享(2)
25、字段解析(3)
28、方法解析
29、klassVtable与klassItable类的介绍
30、计算vtable的大小
31、计算itable的大小
32、解析Class文件之创建InstanceKlass对象
33、字段解析之字段注入
34、类的连接
35、类的连接之验证
36、类的连接之重写(1)
37、类的连接之重写(2)
38、方法的连接
39、初始化vtable
40、初始化itable
41、类的初始化
42、对象的创建
43、Java引用类型
作者持续维护的个人博客 classloading.com。
关注公众号,有HotSpot源码剖析系列文章!

JVM的方法执行引擎-entry point栈帧的更多相关文章
- JVM的方法执行引擎-模板表
Java的模板解析执行需要模板表与转发表的支持,而这2个表中的数据在HotSpot虚拟机启动时就会初始化.这一篇首先介绍模板表. 在启动虚拟机阶段会调用init_globals()方法初始化全局模块, ...
- JVM总结(五):JVM字节码执行引擎
JVM字节码执行引擎 运行时栈帧结构 局部变量表 操作数栈 动态连接 方法返回地址 附加信息 方法调用 解析 分派 –“重载”和“重写”的实现 静态分派 动态分派 单分派和多分派 JVM动态分派的实现 ...
- 一夜搞懂 | JVM 字节码执行引擎
前言 本文已经收录到我的 Github 个人博客,欢迎大佬们光临寒舍: 我的 GIthub 博客 学习导图 一.为什么要学习字节码执行引擎? 代码编译的结果从本地机器码转变为字节码,是存储格式发展的一 ...
- 【JVM】JVM系列之执行引擎(五)
一.前言 在了解了类加载的相关信息后,有必要进行更深入的学习,了解执行引擎的细节,如字节码是如何被虚拟机执行从而完成指定功能的呢.下面,我们将进行深入的分析. 二.栈帧 我们知道,在虚拟机中与执行方法 ...
- JVM字节码执行引擎
一.概述 在不同的虚拟机实现里面,执行引擎在执行Java代码的时候可能会有解释执行(通过解释器执行)和编译器执行(通过即时编译器产生本地代码执行)两种选择,所有的Java虚拟机的执行引擎都是一致的:输 ...
- 图解JVM字节码执行引擎之栈帧结构
一.执行引擎 “虚拟机”的概念是相对于“物理机”而言的,这两种“机器”都有执行代码的能力.物理机的执行引擎是直接建立在硬件处理器.物理寄存器.指令集和操作系统层面的:而“虚拟机”的执行引擎是 ...
- 深入理解JVM—字节码执行引擎
原文地址:http://yhjhappy234.blog.163.com/blog/static/3163283220122204355694/ 前面我们不止一次的提到,Java是一种跨平台的语言,为 ...
- JVM字节码执行引擎和动态绑定原理
1.执行引擎 所有Java虚拟机的执行引擎都是一致的: 输入的是字节码文件,处理过程就是解析过程,最后输出执行结果. 在整个过程不同的数据在不同的结构中进行处理. 2.栈帧 jvm进行方法调用和方法执 ...
- 【死磕JVM】一道面试题引发的“栈帧”!!!
前言 最近小农的朋友--小勇在找工作,开年来金三银四,都想跳一跳,找个踏(gao)实(xin)点的工作,这不小勇也去面试了,不得不说,现在面试,各种底层各种原理,层出不穷,小勇就遇上了这么一道面试题, ...
随机推荐
- python3 url编码与解码
在通过浏览器修改数据库时,要对url内容进行编码 quote()编码; unquote()解码; 直接上代码:
- Spring boot 基础整理(一)
环境准备 (1)JDK 环境必须是 1.8 及以上(2)后面要使用到 Maven 管理工具 3.2.5 及以上版本,所以会先介绍 Maven 的安装与配置(3)开发工具建议使用 IDEA,也可以 My ...
- CF724C Ray Tracing 扩展欧几里得 平面展开
LINK:Ray Tracing 虚这道题很久了 模拟赛考了一个加强版的 瞬间就想到了这道简化版的. 考虑做法 暴力模拟可能可以 官方正解好像就是这个. 不过遇到这种平面问题可以考虑把平面给无限的展开 ...
- 4.23 子集 分数规划 二分 贪心 set 单峰函数 三分
思维题. 显然考虑爆搜.然后考虑n^2能做不能. 容易想到枚举中间的数字mid 然后往mid两边加数字 使其整个集合权值最大. 这里有一个比较显然的贪心就不再赘述了. 可以发现这样做对于集合是奇数的时 ...
- luogu P4095 [HEOI2013]Eden 的新背包问题 多重背包 背包的合并
LINK:Eden 的新背包问题 就是一个多重背包 每次去掉一个物品 询问钱数为w所能买到的最大值. 可以对于每次Q暴力dp 利用单调队列优化多重背包 这样复杂度是Qnm的. 发现过不了n==10的点 ...
- AutoMapper 9.0的改造(续)
上一篇有一个读者,有疑问,如何自动化注册Dto 我开篇,做了一个自动化注册的 public sealed class AutoInjectAttribute : Attribute { public ...
- xml schema杂谈
有一些场景,我们需要写xml,又需要对内容进行约束,比如智能输入某个值范围,只能写入固定值 这个时候我们就需要xml schema 这个,百度解释为 XML Schema 的作用是定义 XML 文档的 ...
- 【USACO02FEB】Rebuilding Roads 重建道路 题解(树形DP)
题目链接 题目大意:问使含有$p$个节点的子树分离至少需要去掉几条边. ------------------ 设$f[i][j]$表示以$i$为根的子树保留$j$个节点所去掉的最少边数. 初始化$f[ ...
- fastjson JSON.toJavaObject() 实体类首字母大写属性无法解析问题
fastjson JSON.toJavaObject() 实体类首字母大写属性无法解析问题
- eureka注册中心的使用
1.父pom.xml中引入springcloud依赖 <dependencyManagement> <dependencies> <dependency> < ...