Deep Learning Specialization 笔记
1. numpy中的几种矩阵相乘:
# x1: axn, x2:nxb
np.dot(x1, x2): axn * nxb
np.outer(x1, x2): nx1*1xn # 实质为: np.ravel(x1)*np.ravel(x2)
np.multiply(x1, x2): [[x1[0][0]*x2[0][0], x1[0][1]*x2[0][1], ...]
2. Bugs' hometown
Many software bugs in deep learning come from having matrix/vector dimensions that don't fit. If you can keep your matrix/vector dimensions straight you will go a long way toward eliminating many bugs.
3. Common steps for pre-processing a new dataset are:
- Figure out the dimensions and shapes of the problem (m_train, m_test, num_px, ...)
- Reshape the datasets such that each example is now a vector of size (num_px \* num_px \* 3, 1)
- "Standardize" the data
4. Unstructured data:
Unstructured data is a generic label for describing data that is not contained in a database or some other type of data structure . Unstructured data can be textual or non-textual. Textual unstructured data is generated in media like email messages, PowerPoint presentations, Word documents, collaboration software and instant messages. Non-textual unstructured data is generated in media like JPEG images, MP3 audio files and Flash video files
5. Chapter of Activation Function:
Choice of activation function:
- If output is either 0 or 1 -- sigmoid for the output layer and the other units on ReLU.
- Except for the output layer, tanh does better than sigmoid.
- ReLU ---level up--> leaky ReLU.
Why are ReLU and leaky ReLU often superior to sigmoid and tanh?
-- The derivatives of the former ones is much bigger than 0, so the learning would be much faster.
A linear hidden layer is more or less useless, yet the activation function is a exception.
6. Regularization:
Initially, \(J(w, b) = \frac{1}{m} * \sum_{i=1}^{m}{L({\hat{Y}^(i), y^{(i)}}) + \frac{\lambda}{2*m}||w||_2^2}\)
L2 regularization: \(\frac{\lambda}{2*m}\sum_{j=1}^{n_x}||w_j||^2 = \frac{\lambda}{2*m}||w||_2\)
One aspect that tanh is better thatn sigmoid(in terms of regularization) -- When x is very close to 0, the derivative of tanh(x) is almost linear, while that of the sigmoid(x) is alomst 0.
Dropout:
Method: Make certain values of weights be zeros randomly, just like -- W= np.multiply(W, C), where C is a 0-1 array.
Matters need attention: Don't use dropout in test procedure -- Time costly, result randomly.
Work principle:
Intuition: Can't rely on any one feature, so have to spread out weights(shrinking weights).
Besides, you can set different rates of "Dropout", like lower ones on more complex layer, which are called "key prop".
- Data augmentation:
Do some operation on your data images, such as flipping, rotation, zooming, etc, without changing their labels, in order to prevent from over-fitting on some aspects, such as the direction of faces, the size of cats.
- Early stopping.
7. Solution to "gradient vanishing or exploding":
Set WL = np.random.randn(shape) * np.sqrt(\(\frac{2}{n^{[L-1]}}\)) if activation_function == "ReLU"
else: np.random.randn(shape) * np.sqrt(\(\frac{1}{n^{[L-1]}}\)) or np.sqrt(\(\sqrt{\frac{2}{n^{[L-1]}+n^{[L]}}}\))(Xavier initialization)
8. Gradient Checking:
for i in range(len(\(\theta\))):
to check if (d\(\theta_{approx}[i] = \frac{J(\theta_1, \theta_2, ..., \theta_i+\epsilon, ...) - J(\theta_1, \theta_2, ..., \theta_i-\epsilon, ...)}{2\epsilon}\)) ?= \(d\theta[i] = \frac{\partial{J}}{\partial{\theta_i}}\)
<==> \(d\theta_{approx} ?= d\theta\)
<==> \(\frac{||d\theta_{approx} - d\theta||_2}{||d\theta_{approx}||_2+||d\theta||_2}\) in an accent range: \(10^{-7}\) is great, and \(10^{-3}\) is wrong.
Tips:
- Only to debug, instead of training.
- If algorithm fails grad check, look at components(\(db^{[L]}, dw^{[L]}\)) to try to identify bug.
- Remember regularization.
- Doesn't work together with dropout.
- Run at random initialization; perhaps again after some training.
9. Exponentially weighted averages:
Definition: let \(V_{t} = {\beta}V_{t-1} + (1 - \beta)\theta_t\) (_V_s are the averages, and the _\(\theta\)_s are the initial discrete data).
and \(V_{t} = \frac{V_{t}}{1 - {\beta}^t}\) (To correct initial bias).
Usage: when it comes to this situation: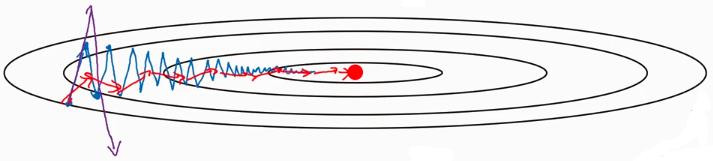
Since the average of the distance vertical movement is almost zeros, you can use EWA to average it, prevent it from divergence.
On iteration t:
Compute dW on the current mini-batch
\(v_{dW} = {\beta}v_{dW} + (1 - \beta)dW\)
\(v_{db} = {\beta}v_{db} + (1 - \beta)db\)
\(W = W - {\alpha}v_{dW}, b = b - {\alpha}v_{db}\)
Hyperparameters: \(\alpha\), \({\beta}(=0.9)\)
Deep Learning Specialization 笔记的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- 【deep learning学习笔记】注释yusugomori的DA代码 --- dA.h
DA就是“Denoising Autoencoders”的缩写.继续给yusugomori做注释,边注释边学习.看了一些DA的材料,基本上都在前面“转载”了.学习中间总有个疑问:DA和RBM到底啥区别 ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记
Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记 2018年12月03日 00: ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
https://blog.csdn.net/zouxy09/article/details/9993371 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一 ...
- [置顶]
Deep Learning 学习笔记
一.文章来由 好久没写原创博客了,一直处于学习新知识的阶段.来新加坡也有一个星期,搞定签证.入学等杂事之后,今天上午与导师确定了接下来的研究任务,我平时基本也是把博客当作联机版的云笔记~~如果有写的不 ...
随机推荐
- 干货!上古神器 sed 教程详解,小白也能看的懂
目录: 介绍工作原理正则表达式基本语法数字定址和正则定址基本子命令实战练习 介绍 熟悉 Linux 的同学一定知道大名鼎鼎的 Linux 三剑客,它们是 grep.awk.sed,我们今天要聊的主角就 ...
- 01. struts2介绍
struts2优点 与Servlet API 耦合性低.无侵入式设计 提供了拦截器,利用拦截器可以进行AOP编程,实现如权限拦截等功能 支持多种表现层技术,如:JSP.freeMarker.veloc ...
- mysql(连接查询和数据库设计)
--创建学生表 create table students ( id int unsigned not null auto_increment primary key, name varchar(20 ...
- jQuery 实现复制功能
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Trie 前缀树或字典树 确定有限状态自动机
https://zh.wikipedia.org/wiki/Trie 应用 trie树常用于搜索提示.如当输入一个网址,可以自动搜索出可能的选择.当没有完全匹配的搜索结果,可以返回前缀最相似的可能.[ ...
- 【实战】ZooKeeper 实战
1. 前言 这篇文章简单给演示一下 ZooKeeper 常见命令的使用以及 ZooKeeper Java客户端 Curator 的基本使用.介绍到的内容都是最基本的操作,能满足日常工作的基本需要. 如 ...
- 20201104gryz模拟赛解题报告
写在前面 \(Luckyblock\) 良心出题人, 题面好评 T1还是蛮简单的,用一个栈来维护就能过(某天听说 \(Luckyblock\) 出了套题,T1是个考栈的,看来就是这道了 注:栈的清空只 ...
- loj10173
炮兵阵地 司令部的将军们打算在 N×M 的网格地图上部署他们的炮兵部队.一个 N×M的地图由 N 行 M 列组成,地图的每一格可能是山地(用 H 表示),也可能是平原(用 P表示),如下图.在每一格平 ...
- kubenetes 相关命令(转载)
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/xingwangc2014/article/details/51204224好久没写博客了,前段时间公 ...
- MVC框架,SpringMVC
文章目录 使用Controller URL映射到方法 @RequestMapping URL路径匹配 HTTP method匹配 consumes和produces params和header匹配 方 ...