面试题目:手写一个LRU算法实现
一、常见的内存淘汰算法
FIFO 先进先出
在这种淘汰算法中,先进⼊缓存的会先被淘汰
命中率很低
LRU
Least recently used,最近最少使⽤get
根据数据的历史访问记录来进⾏淘汰数据,其核⼼思想是“如果数据最近被访问过,那么将来被访问的⼏率也更⾼”
LRU算法原理剖析

LFU
- Least Frequently Used
算法根据数据的历史访问频率来淘汰数据,其核⼼思想是“如果数据过去被访问多次,那么将来被访问的频率也更⾼”
LFU算法原理剖析
新加⼊数据插⼊到队列尾部(因为引⽤计数为1)
队列中的数据被访问后,引⽤计数增加,队列重新排序;
当需要淘汰数据时,将已经排序的列表最后的数据块删除。
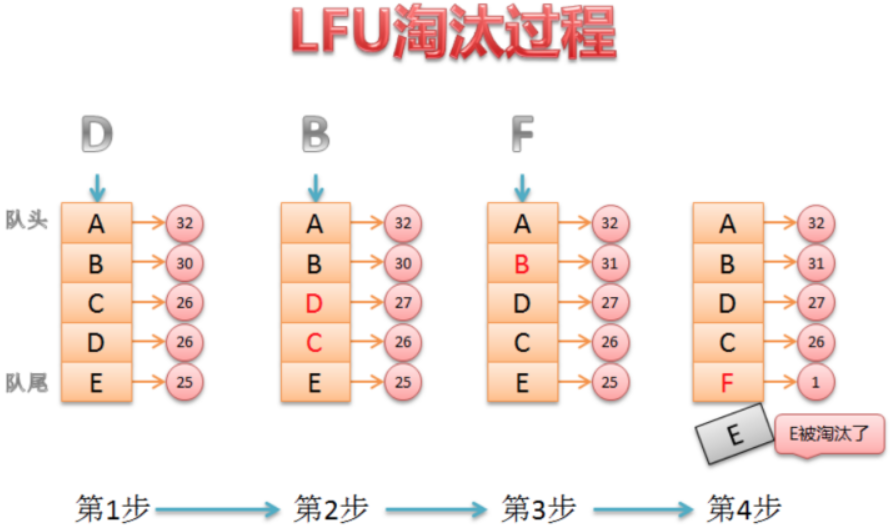
- LFU的缺点
- 复杂度
- 存储成本
- 尾部容易被淘汰
二、手写LRU算法实现
利用了LinkedHashMap双向链表插入可排序
@Slf4j
public class LRUCache<K, V> extends LinkedHashMap<K, V> { private int cacheSize; public LRUCache(int cacheSize) {
super(16, 0.75f, true);
this.cacheSize = cacheSize;
} @Override
public synchronized V get(Object key) {
return super.get(key);
} @Override
public synchronized V put(K key, V value) {
return super.put(key, value);
} @Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
boolean f = size() > cacheSize;
if (f) {
log.info("LRUCache清除第三方密钥缓存Key:[{}]", eldest.getKey());
}
return f;
} public static void main(String[] args) {
LRUCache<String, Object> cache = new LRUCache<>(5);
cache.put("A","A");
cache.put("B","B");
cache.put("C","C");
cache.put("D","D");
cache.put("E","E");
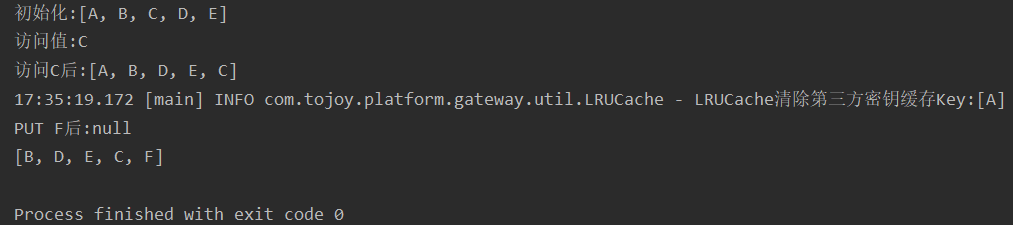
System.out.println("初始化:" + cache.keySet());
System.out.println("访问值:" + cache.get("C"));
System.out.println("访问C后:" + cache.keySet());
System.out.println("PUT F后:" + cache.put("F","F"));
System.out.println(cache.keySet());
} }
main函数执行效果:
三、注意事项
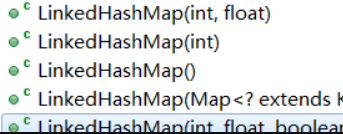
LinkedHashMap有五个构造函数


//使用父类中的构造,初始化容量和加载因子,该初始化容量是指数组大小。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
//一个参数的构造
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
//无参构造
public LinkedHashMap() {
super();
accessOrder = false;
}
//这个不用多说,用来接受map类型的值转换为LinkedHashMap
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
//真正有点特殊的就是这个,多了一个参数accessOrder。存储顺序,LinkedHashMap关键的参数之一就在这个,
//true:指定迭代的顺序是按照访问顺序(近期访问最少到近期访问最多的元素)来迭代的。 false:指定迭代的顺序是按照插入顺序迭代,也就是通过插入元素的顺序来迭代所有元素
//如果你想指定访问顺序,那么就只能使用该构造方法,其他三个构造方法默认使用插入顺序。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
参数accessOrder。存储顺序,LinkedHashMap关键的参数之一就在这个, true:指定迭代的顺序是按照访问顺序(近期访问最少到近期访问最多的元素)来迭代的。 false:指定迭代的顺序是按照插入顺序迭代,也就是通过插入元素的顺序来迭代所有元素。
如果你想指定访问顺序,那么就只能使用该构造方法,其他三个构造方法默认使用插入顺序。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
LinkedHashMap是非线程安全的,需要加互斥锁解决并发问题。
四、思考
需要根据应用场景确定cacheSize大小,如果实际缓存数量过小,会导致缓存中的数据长期得不到刷新,为防止这种或偶发情况的发生,可配合定时任务如起一个newSingleThreadScheduledExecutor,将上面存储的value修改封装为一个对象,里面增加一个时间戳储存,每次访问实时更新,定时扫描该队列将最近30分钟未访问的key删除;还需增加一个初始进入队列的历史时间记录,将超过1小时的数据清除。
面试题目:手写一个LRU算法实现的更多相关文章
- 搞定redis面试--Redis的过期策略?手写一个LRU?
1 面试题 Redis的过期策略都有哪些?内存淘汰机制都有哪些?手写一下LRU代码实现? 2 考点分析 1)我往redis里写的数据怎么没了? 我们生产环境的redis怎么经常会丢掉一些数据?写进去了 ...
- 【redis前传】自己手写一个LRU策略 | redis淘汰策略
title: 自己手写一个LRU策略 date: 2021-06-18 12:00:30 tags: - [redis] - [lru] categories: - [redis] permalink ...
- 手写一个LRU工具类
LRU概述 LRU算法,即最近最少使用算法.其使用场景非常广泛,像我们日常用的手机的后台应用展示,软件的复制粘贴板等. 本文将基于算法思想手写一个具有LRU算法功能的Java工具类. 结构设计 在插入 ...
- 写一个LRU算法的记录
今天简单记录一下,利用Scala解答的一道LRU题目,原题为LeetCode的第146题,是一道设计LRU的题目. 题目详情 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机 ...
- 4.redis 的过期策略都有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?
作者:中华石杉 面试题 redis 的过期策略都有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现? 面试官心理分析 如果你连这个问题都不知道,上来就懵了,回答不出来,那线上你写代码的时候,想当 ...
- 『练手』手写一个独立Json算法 JsonHelper
背景: > 一直使用 Newtonsoft.Json.dll 也算挺稳定的. > 但这个框架也挺闹心的: > 1.影响编译失败:https://www.cnblogs.com/zih ...
- 手写一个虚拟DOM库,彻底让你理解diff算法
所谓虚拟DOM就是用js对象来描述真实DOM,它相对于原生DOM更加轻量,因为真正的DOM对象附带有非常多的属性,另外配合虚拟DOM的diff算法,能以最少的操作来更新DOM,除此之外,也能让Vue和 ...
- java面试:手写代码
二分查找法. /** * 二分查找法:给定一组有序的数组,每次都从一半中查找.直到找到要求的数据. * 主要是得找到下标的表示方法. */ public class BinaryFind { /** ...
- 放弃antd table,基于React手写一个虚拟滚动的表格
缘起 标题有点夸张,并不是完全放弃antd-table,毕竟在react的生态圈里,对国人来说,比较好用的PC端组件库,也就antd了.即便经历了2018年圣诞彩蛋事件,antd的使用者也不仅不减,反 ...
随机推荐
- 【C#表达式树 开篇】 Expression Tree - 动态语言
.NET 3.5中新增的表达式树(Expression Tree)特性,第一次在.NET平台中引入了"逻辑即数据"的概念.也就是说,我们可以在代码里使用高级语言的形式编写一段逻辑, ...
- 【C# 基础概念】表达式(expression)、语句(statement)、块(block),指令(using)
官方链接:https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/statements-expressions-operato ...
- Weblogic 打补丁冲突检测慢---解决方法
转至:https://www.cnblogs.com/vzhangxk/p/13365457.html 1.Smart Update 智能升级工具版本: [root@pxc1 bsu]# ./bsu. ...
- gradle , maven , ant , ivy , grant之间的区别
java项目构建工具 gradle Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化构建开源工具. 它抛弃了基于XML的各种繁琐配置.它使用一种基于Groovy的特 ...
- Pycharm:如果想验证一个文件中的函数
在该文件的函数后写上两句 def test(): pass if __name__='__main__': test() 这样就可以执行该函数 如果只是在其他文件中导入了该函数,则不会执行最后两段话, ...
- c# 窗体相关操作(最大化/最小化/关闭/标题栏)
/// <summary> /// 窗体跟随鼠标移动的标记 /// </summary> private bool normalmoving = false; /// < ...
- 05-LoadBalancer负载均衡
1.介绍 目前主流的负载方案分为以下两种: 集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的(比如 F5),也有软件的(比如 Nginx). 客户端根据自己的请求情况做负载 ...
- [手写系列] 带你实现一个简单的Promise
简介 学习之前 需要先对Promise有个基本了解哦,这里都默认大家都是比较熟悉Promise的 本次将带小伙伴们实现Promise的基本功能 Promise的基本骨架 Promise的then Pr ...
- ws请求定时
heartChechInit() { const _this = this; // 设置统筹管理 let heartCheck = { timer: ...
- ln -s 软链接知识总结
ln -s 软链接知识总结 1.软连建立:ln -s 源文件 软链接文件 2.误区:软链接是创建的,就意味着软链接文件不可以在创建之前存在 3.类比:win快捷方式 4.删除:rm就可以,但源文件 ...