redis集群之分片集群的原理和常用代理环境部署
上篇文章刚刚介绍完redis的主从复制集群,但主从复制集群主要是为了解决redis集群的单点故障问题,通过整合哨兵能实现集群的高可用;但是却无法解决数据容量以及单节点的压力问题,所以本文继续介绍redis的分片集群;分片集群即将不同的数据分发到不同的redis实例(或者主从集群),每个redis实例没有关联,这样当数据量过大时就做到了数据的分治,如果某个实例故障也不至于丢失所有的数据;下面我会首先解决分片集群的常用实现方案,然后介绍如何搭建Twitter和predixy两种代理实现的redis集群,正常情况,按照我的步骤做完就能够搭建一套可以的redis集群了;下面开始
一、分片集群的解决方案
这里我们不单一讨论redis,我们从分片集群的根本出发,分片即将数据分发到不同的后端服务上去,那么显然我们可以从客户端和服务端这两个方面下手;
1、客户端实现
(1)、通过业务分类
- 可以根据业务分类,由客户端控制,将不同业务线的数据打到不同的实例
(2)、hash+取模(modula)
- 思路:通过对key进行hash+取模然后根据结果打到不同的实例上;模几取决于redis集群的实例数量;
- 缺点:模数是固定的,如果集群拓展时需要调整,且拓展前的数据就不好取到了;
(3)、通过随机数选择redis实例(random)
- 思路:数据到达时随机往集群中的某个实例扔数据,这样存数据是容易了但是取数据难
- 使用场景:这种情况适用于实现消息队列,往不同的redis里仍相同key的不同数据,客户端消费集群中的每个实例后就能获取到完整数据
(4)、一致性哈希环(ketama)
- 思路:维护一个虚拟的环形结构,该环有N个点组成;将redis集群中的所有实例通过一致性哈希算法计算后映射到该哈希环上,作为环中唯一的物理节点,如果集群有三个实例,那么环中就会有三个物理节点;当数据进来时,对key做哈希运算最终也要落到这个哈希环上,然后找出离自己最近的物理节点,再将数据打到该节点上即可
- 缺点:
- 由于每个实例参与计算的信息不一样,并不总能保证集群的各节点在环上是均匀分布的,所以为了解决数据倾斜的问题,可以将每个实例多映射几份一起参与计算,这样散在环上的节点变多了,也就一定程度上解决了数据倾斜的问题
- 当有新的实例上线时,会丢失一定长度数据;可以通过改变寻找实例的逻辑解决,当key打到环上时,我们不再是找离它最近的一个节点,而是找离他最近的两个节点取数据
2、服务端实现(redis cluster)
(1)、基本概念介绍(概念摘自redis官网)
- Redis集群是一个提供在多个Redis间节点间共享数据的程序集,能够自动分发数据到不同实例;其并没有使用一致性哈希算法,而是引入了哈希槽的概念;Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
(2)、redis的集群搭建
- 这里的搭建很简单,按照中文官网的步骤往下走就行了,这里就不一一介绍了,需要搭建的可以移步http://redis.cn/topics/cluster-tutorial.html
二、通过Twitter的twemproxy代理搭建redis集群
twemproxy是由Twitter开源的一套代理分片服务,可以接受多个客户端的访问然后根据配置的算法将数据分配到不同的redis节点,再按原路返回;不支持redis的watch、multi等命令
1、mkdir twemproxy 在/root目录创建一个twemproxy用来存放twemproxy的源码
2、安装git yum install git
3、克隆twemproxy的代码
- git clone https://github.com/twitter/twemproxy.git
4、进入源码目录,cd twemproxy
5、安装automake和libtool
- yum install automake libtool -y
6、安装configure,执行autoreconf -fvi
7、执行 ./configure
8、执行make编译源码,编译完正常会有可执行程序出现
9、进入源码的/scripts目录,将配置文件拷贝至/etc/init.d/twemproxy目录
- cp nutcracker.init /etc/init.d/twemproxy
10、进入init.d文件, 执行chmod +x twemproxy给twemproxy赋权
11、创建配置文件所在的目录
- mkdir /etc/nutcracker
12、进入源码安装目录的conf目录,将conf目录下的配置文件拷贝到11步创建的文件夹下
- cd ~/soft/twemproxy/twemproxy/conf
- cp ./* /etc/nutcracker/
13、进入源码安装目录的src目录,将编译完的可执行程序复制到/usr/bin目录下,这样在系统任意位置都可以运行nutcracker
- cd ~/soft/twemproxy/twemproxy/src/
- cp nutcracker /usr/bin
14、进入nutcracker目录,修改配置文件
- cd /etc/nutcracker/
- cp nutcracker.yml nutcracker.yml.bak 稳妥起见,先备份
- vi nutcracker.yml 编辑配置文件
15、启动两个redis实例
- redis-server ~/testRedis/6379.conf
- redis-server ~/testRedis/6380.conf
16、启动nutcracker
- service twemproxy start
17、启动redis客户端连接nutcracker对外暴露的端口
- redis-cli -p 22121 连接成功后如图,即可对redis进行操作

我们通过22121端口的代理就可以直接访问redis集群,可以设置数据,但是由于数据分治了,所以例如keys 、watch、multi等这种聚合的命令在代理里是不支持的;至此,通过twemproxy 代理的方式搭建的redis集群就完成了,客户端只需链接22121端口,至于后续的分片操作由代理服务进行转发
- redis-cli -p 22121 连接成功后如图,即可对redis进行操作
三、通过predixy搭建redis集群
predixy也是一款redis的代理服务,其即支持redis sentinel又支持redis cluster,在group只有一个的情况下,其还支持watch、multi等指令
- 1、在~/soft目录创建predixy目录并且进入,用于下载源码;
- mkdir predixy
- cd predixy
- 2、下载源码包
- 3、解压
- tar xf predixy-1.0.5-bin-amd64-linux.tar.gz
- 4、进入conf目录,编辑predixy.conf文件
- vi predixy.conf
- 将bind 127.0.0.1:7617的注释放开
- 将Include try.conf注释,将Include sentinel.conf放开
- 5、编辑sentinel.conf 文件
- vi sentinel.conf
- 将SentinelServerPool配置的注释放开,并按下图进行配置
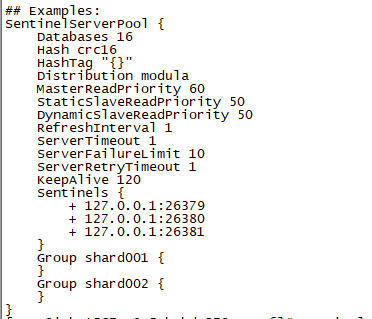
Sentinels{}里填哨兵集群的ip和端口
Group表示redis分组,shard001表示分组名称;上图配置表示一个哨兵集群监控了两套redis的主从集群
注意:Group后面跟的名称需要与哨兵配置文件里的master名称一致
6、根据5中的注意,所以我们现在需要去修改哨兵的配置文件,将其监控的master名称由默认的mymaster改为shard001,又因为我们需要哨兵监控两个主从集群,所以需要再加一个shard002的master配置,命令如下:
vi 26379.conf 、 vi 26380.conf 、 vi 26381.conf
修改完的配置文件如下图

注意:上图只截取了26379的配置,26380和81与79除了port外其余配置均一致
7、启动哨兵集群
- redis-server ./26379.conf --sentinel
- redis-server ./26380.conf --sentinel
- redis-server ./26381.conf --sentinel
8、任意位置创建文件夹test,在里面创建36379、80和46379、80的目录
进入36379目录执行 redis-server --port 36379
进入36380目录执行 redis-server --port 36380 --replicaof 127.0.0.1 36379追随36379
这样一个主从集群就搭建起来了,46379和80与上面一致,只需更改对应端口即可,我这里就不再赘述了
至此,哨兵集群与两套redis主从复制集群已启动完毕
9、进入predixy安装的bin目录启动predixy
- cd soft/predixy/predixy-1.0.5/bin
- ./predixy ../conf/predixy.conf
- 启动成功如下图:

10、用redis客户端测试
虽然上面搭建废了九牛二虎之力,但是对客户端而言只需关注predixy对外暴露的服务连接即可:
- redis-cli -p 7617
连接成功后就可以操作redis了,predixy会自动分发到不同的redis集群中去;设置如图:
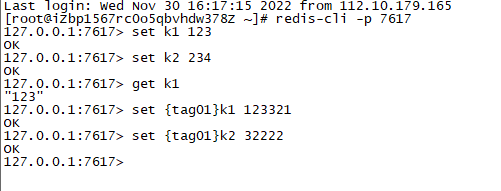
- 然后连接36379可以发现,k1和设置了tag的key都分发到此了,如图:
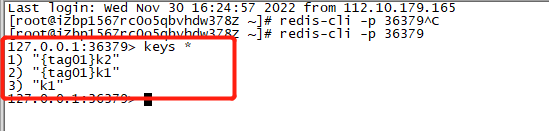
- 再连接46379,发现k2被分发到46379了

predixy只支持单group下的事务、watch等操作,我们这里配置了两个group所以不支持;但是如果只配置一个group的话那么能写的也只有一个master,就失去了分片集群的意义了
redis集群之分片集群的原理和常用代理环境部署的更多相关文章
- redis主从架构,分片集群详解
写在前面:这篇笔记有点长,如果你认真看完,收获会不少,如果你只是忘记了相关命令,请翻到末尾. redis的简单介绍: 一个提供多种数据类类型储存,整个系统都在内存中运行的, 定期通过异步的方式把数据刷 ...
- Redis 高可用及分片集群,说了你也不懂
Redis 简介 Memcached: 优点:高性能读写.单一数据类型.支持客户端式分布式集群.一致性hash 多核结构.多线程读写性能高. 缺点:无持久化.节点故障可能出现缓存穿透.分布式需要客户端 ...
- mongodb集群配置分片集群
测试环境 操作系统:CentOS 7.2 最小化安装 主服务器IP地址:192.168.197.21 mongo01 从服务器IP地址:192.168.197.22 mongo02 从服务器IP地址: ...
- MongoDB副本集(一主两从)读写分离、故障转移功能环境部署记录
Mongodb是一种非关系数据库(NoSQL),非关系型数据库的产生就是为了解决大数据量.高扩展性.高性能.灵活数据模型.高可用性.MongoDB官方已经不建议使用主从模式了,替代方案是采用副本集的模 ...
- Redis高可用及分片集群
一.主从复制 使用异步复制 一个服务器可以有多个从服务器 从服务器也可以有自己的从服务器 复制功能不会阻塞主服务器 可以通过服务功能来上主服务器免于持久化操作,由从服务器去执行持久化操作即可. 以下是 ...
- mongodb3.6集群搭建:分片集群认证
上篇集群已经创建,现在加入认证. 1. 生成密钥文件每个服务器上创建路径: mkdir -p /var/lib/mongo/auth 生成64字节的密钥文件openssl rand -base64 6 ...
- MongoDB 搭建分片集群
在MongoDB(版本 3.2.9)中,分片是指将collection分散存储到不同的Server中,每个Server只存储collection的一部分,服务分片的所有服务器组成分片集群.分片集群(S ...
- mongoDB研究笔记:分片集群部署
前面几篇文章的分析复制集解决了数据库的备份与自动故障转移,但是围绕数据库的业务中当前还有两个方面的问题变得越来越重要.一是海量数据如何存储?二是如何高效的读写海量数据?尽管复制集也可以实现读写分析,如 ...
- Mongodb集群与分片 1
分片集群 Mongodb中数据分片叫做chunk,它是一个Collection中的一个连续的数据记录,但是它有一个大小限制,不可以超过200M,如果超出产生新的分片. 下面是一个简单的分片集群 ...
- mongodb分片集群安装教程
mongodb 集群包含副本集群,主从集群以及分片集群,分片集群比较复杂,这里测试我采用了三台机器,交差部署 blog地址:http://www.cnblogs.com/caoguo 一 .环境:#m ...
随机推荐
- G&GH01 注册/安装/设置
注意事项与声明 平台: Windows 10 作者: JamesNULLiu 邮箱: jamesnulliu@outlook.com 博客: https://www.cnblogs.com/james ...
- 海康摄像机使用GB28181接入SRS服务器的搭建步骤---源码安装的方式
下载代码 地址:https://github.com/ossrs/srs-gb28181 https://github.com/ossrs/srs-gb28181.git 注意:使用的是含有gb281 ...
- fastapi快速入门
fastapi是高性能的web框架.他的主要特点是: 快速编码 减少人为bug 直观 简易 具有交互式文档 基于API的开放标准(并与之完全兼容):OpenAPI(以前称为Swagger)和JSON ...
- Elasticsearch:正确使用regexp搜索
- 多云容器编排 Karmada-Operator 实践
作者:vivo 互联网服务器团队-Zhang Rong Karmada作为开源的云原生多云容器编排项目,吸引了众多企业共同参与项目开发,并运行于生产环境中.同时多云也逐步成为数据中心建设的基础架构,多 ...
- HDU4734 F(x) (数位DP)
(如此简短的题目给人一种莫名的压迫感......) 题目中定义一个数的权值求解函数:F(x) = An * 2n-1 + An-1 * 2n-2 + ... + A2 * 2 + A1 * 1. 观察 ...
- 利用Java集合实现学生信息的”增删查“
之前学了Java中的集合,打算写一个小程序来消化一下! 那么我们知道,集合相比数组的优点就是可以动态的增加元素,这对比数组来说,十分的便捷: 并且集合为我们封装好一些方法,可以更好的做一些数据操作! ...
- 如何编写 Pipeline 脚本
前言 Pipeline 编写较为麻烦,为此,DataKit 中内置了简单的调试工具,用以辅助大家来编写 Pipeline 脚本. 调试 grok 和 pipeline 指定 pipeline 脚本名称 ...
- Can not set int field xxx to java.lang.Long 错误
Can not set int field xxx to java.lang.Long 错误 这个错误其实是因为Java程序和MySQL表中字段的属性匹配不一致 我的报错是Can not set ja ...
- go-zero docker-compose 搭建课件服务(一):编写服务api和proto
0.转载 go-zero docker-compose 搭建课件服务(一):编写服务api和proto 0.1源码地址 https://github.com/liuyuede123/go-zero-c ...