mapreduce统计单词
源代码:
WordCountMapper.java:
package cn.idcast.mapreduce; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /*
四个泛型解释:
KEYIN:k1的类型
VALUEIN:v1的类型 KEYOUT:k2的类型
VALUEOUT:v2的类型
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> { //map方法就是将K1和v1 转为k2和v2
/*
参数:
key :k1 行偏移量
value :v1 每一行的文本数据
context:表示上下文对象
*/
/*
如何将K1和v1 转为k2和v2
k1 v1
0 hello,world,hadoop
15 hdfs,hive,hello
------------------------- k2 v2
hello 1
world 1
hdfs 1
hadoop 1
hello 1
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
//1:将一行的文本数据进行拆分
String[] split = value.toString().split(","); //2:遍历数组,组装k2和v2
for (String word : split) {
//3:将k2和v2写入上下文中
text.set(word);
longWritable.set(1);
context.write(text,longWritable);
} }
}
WordCountReducer.java:
package cn.idcast.mapreduce; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /*
四个泛型解释:
KEYIN:k2的类型
VALUEIN:v2的类型 KEYOUT:k3的类型
VALUEOUT:v3的类型
*/
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
//reduce方法作用:将新的k2和v2转为 k3和v3,将k3 和v3写入上下文中
/*
参数:
key :新k2
values :集合 新v2
context:表示上下文对象
-----------------------
如何将新的k2和v2转为k3和v3
新 k2 v2
hello <1,1,1>
world <1,1>
hadoop <1>
-------------------------
k3 v3
hello 3
world 2
hadoop 1
*/
@Override
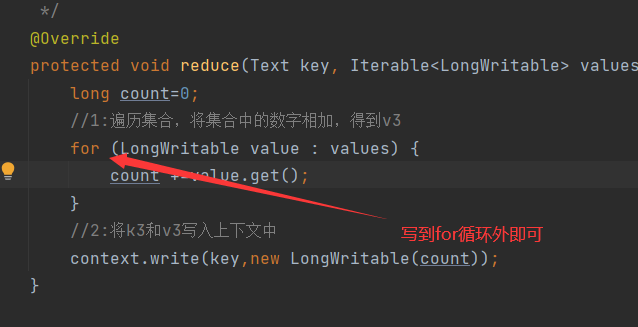
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0;
//1:遍历集合,将集合中的数字相加,得到v3
for (LongWritable value : values) {
count +=value.get();
}
//2:将k3和v3写入上下文中
context.write(key,new LongWritable(count));
}
}
JobMain.java:
package cn.idcast.mapreduce; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.net.URI; public class JobMain extends Configured implements Tool { //该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1:创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "wordcount");
//如果打包运行出错,则需要加该配置
job.setJarByClass(JobMain.class);
//2:配置job任务对象(八个步骤) //第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/wordcount")); //第二部:指定Map阶段的处理方式
job.setMapperClass(WordCountMapper.class);
//设置Map阶段k2的类型
job.setMapOutputKeyClass(Text.class);
//设置Map阶段v2的类型
job.setMapOutputValueClass(LongWritable.class); //第三,四,五,六 采用默认方式,现阶段不做处理 //第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReducer.class);
//设置k3的类型
job.setOutputKeyClass(Text.class);
//设置v3的类型
job.setOutputValueClass(LongWritable.class); //第八步:设置输出类型
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
Path path=new Path("hdfs://node1:8020/wordcount_out");
TextOutputFormat.setOutputPath(job,path); //获取FileSystem
FileSystem fs = FileSystem.get(new URI("hdfs://node1:8020/wordcount_out"),new Configuration());
//判断目录是否存在
if (fs.exists(path)) {
fs.delete(path, true);
System.out.println("存在此输出路径,已删除!!!");
}
//等待任务结束
boolean bl = job.waitForCompletion(true);
return bl ? 0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
记录一个小错误:

发现key重复输出了,原因:reduce步骤中把提交上下文放到循环里去了,导致每加一次就输出一次
mapreduce统计单词的更多相关文章
- 第六章 第一个Linux驱动程序:统计单词个数
现在进入了实战阶段,使用统计单词个数的实例让我们了解开发和测试Linux驱动程序的完整过程.第一个Linux驱动程序是统计单词个数. 这个Linux驱动程序没有访问硬件,而是利用设备文件作为介质与应用 ...
- 第六章第一个linux个程序:统计单词个数
第六章第一个linux个程序:统计单词个数 从本章就开始激动人心的时刻——实战,去慢慢揭开linux神秘的面纱.本章的实例是统计一片文章或者一段文字中的单词个数. 第 1 步:建立 Linu x 驱 ...
- NOIP200107统计单词个数
NOIP200107统计单词个数 难度级别: A: 编程语言:不限:运行时间限制:1000ms: 运行空间限制:51200KB: 代码长度限制:2000000B 试题描述 给出一个长度不超过200的由 ...
- python 统计单词个数
根据一篇英文文章统计其中单词出现最多的10个单词. # -*- coding: utf-8 -*-import urllib2import refrom collections import Coun ...
- NOIP2001 统计单词个数
题三 统计单词个数(30分) 问题描述 给出一个长度不超过200的由小写英文字母组成的字母串(约定;该字串以每行20个字母的方式输入,且保证每行一定为20个).要求将此字母串分成k份(1<k&l ...
- Codevs_1040_[NOIP2001]_统计单词个数_(划分型动态规划)
描述 http://codevs.cn/problem/1040/ 与Codevs_1017_乘积最大很像,都是划分型dp. 给出一个字符串和几个单词,要求将字符串划分成k段,在每一段中求共有多少单词 ...
- 电子科大POJ "统计单词"
统计单词 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) C-sources: ...
- 统计单词频率--map
问题描述: 输入一个单词列表,每行一个单词,统计单词出现的频率 思路: 主要是使用c++中的map容器.map实质上是一个二叉查找树,可以做到插入.删除.查询,平均查询时间在O(logn).n为map ...
- 洛谷 P1308 统计单词数【字符串+模拟】
P1308 统计单词数 题目描述 一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数. 现在,请你编程实现这一功能,具体要求是:给定 ...
随机推荐
- 『现学现忘』Docker基础 — 14、Docker的卸载
目录 1.查询Docker安装过的包 2.卸载Docker软件包 3.删除残留目录 4.验证是否卸载 5.20版本Docker卸载(官方文档) 1.查询Docker安装过的包 执行yum list i ...
- XSS攻击防范
前端安全系列之XSS攻击防范 1.使用textContent 2.使用HTML转义 把JS中的标签转成字符 3.对于链接跳转 禁止含有'javascript:'开头的字符 4.标签属性中含有恶意执行代 ...
- BSOJ7526口胡
直觉告诉我一般情况下,询问古怪的题都是分块,但是这一类题不太一样. 思考一个奇怪的暴力,每次询问的时候询问 \(f(1,k),f(2,k+1),f(3,k+2),...f(n-k+1,n)\),然后加 ...
- SourceTree代码变更和FoxMail邮件管理(效率小计俩)
代码变更溯源 工作时,我们经常会想要查看一个类文件的变更历史,最常见的场景是:"卧槽,谁改了我的代码" 新版本的Xcode溯源自我感觉相当难用,所以这里我们介绍一个工具 Sourc ...
- Net中事件的用法之二
1.委托与事件的区别 事件对权限做了控制 1.委托可以直接调用 事件不可以直接调用 2.委托允许外面直接赋值 事件不允许外面直接赋值 2.事件与委托的实例比较 using System; using ...
- mysql之常用函数(核心总结)
为了简化操作,mysql提供了大量的函数给程序员使用(比如你想输入当前时间,可以调用now()函数) 函数可以出现的位置:插入语句的values()中,更新语句中,删除语句中,查询语句及其子句中. 聚 ...
- linux的一些sao东西
1.sys命令的目录 /usr/include/asm-generic
- 浅谈systemd原理和应用
多不说,直接上代码(可谓配置): [Unit] Description=demo app After=network-is-online.target [Service] Type=Simple Ex ...
- 羽夏笔记——Hook攻防基础
写在前面 本笔记是由本人独自整理出来的,图片来源于网络.本人非计算机专业,可能对本教程涉及的事物没有了解的足够深入,如有错误,欢迎批评指正. 如有好的建议,欢迎反馈.码字不易,如果本篇文章有帮助你 ...
- java打入jar包
首先在项目下创建一个文件夹,保存我们的jar包. 在项目名上右击,依次点击[New]-->[Floder],打开新建文件夹窗口 输入文件夹名称[lib],点击[ok].我们通常在lib文件夹中存 ...