HOSMEL:一种面向中文的可热插拔模块化实体链接工具包
HOSMEL: A Hot-Swappable Modularized Entity Linking Toolkit for Chinese
ACL 2022
论文地址:https://aclanthology.org/2022.acl-demo.21.pdf
代码地址:https://github.com/THUDM/HOSMEL
动机
我们需要标注一个新数据集,比如将关系作为问题回答的附加特性的数据集,并在新数据集上重新训练EL模型。这种标注和模型重新训练是非常昂贵和低效的,这就提出了一个自然的问题:我们能否开发一种有效的EL工具,可以很容易地适应下游任务?
所提出方法的特性
低耦合的模块。我们将提及过滤、提及检测和实体消歧按实体的每个属性模块化,保证每个模块可以单独训练和自由组合。
增量开发。这种解耦设计将每个步骤的模块变成一个可热插拔模块,可以在不重新训练整个模型的情况下灵活地添加之前没有考虑的新特性。
使用灵活(三种使用模式)。我们开发了相应的中文EL工具包。为了灵活使用,我们发布了三种使用方法。第一个是直接调用API或访问web应用程序的现成版本。第二个版本是部分版本,用于那些希望包含部分版本作为改进模型召回的前步骤的用户。第三个版本是一个易于更改的版本,支持添加额外的特性或使用自定义数据进行训练。
流可视化。解耦设计还提供了一种更易于解释的方式来可视化每个模块的结果,这为用户工程师提供了一种更轻松的体验,以决定用于优化最佳结果的有用功能。
该方法的优势
- 与SOTA模型相比,轻量级的HOSMEL训练时间减少4-5倍。与EntQA相比,存储占用率降低了78%。
- 与EntQA相比,用更少的数据量可以训练出更好的模型。
- 我们另外评估了HOSMEL的热插拔能力,发现当添加新的特征关系时,HOSMEL可以快速更新,并进一步提高3.71-5.02%的准确率。
具体介绍
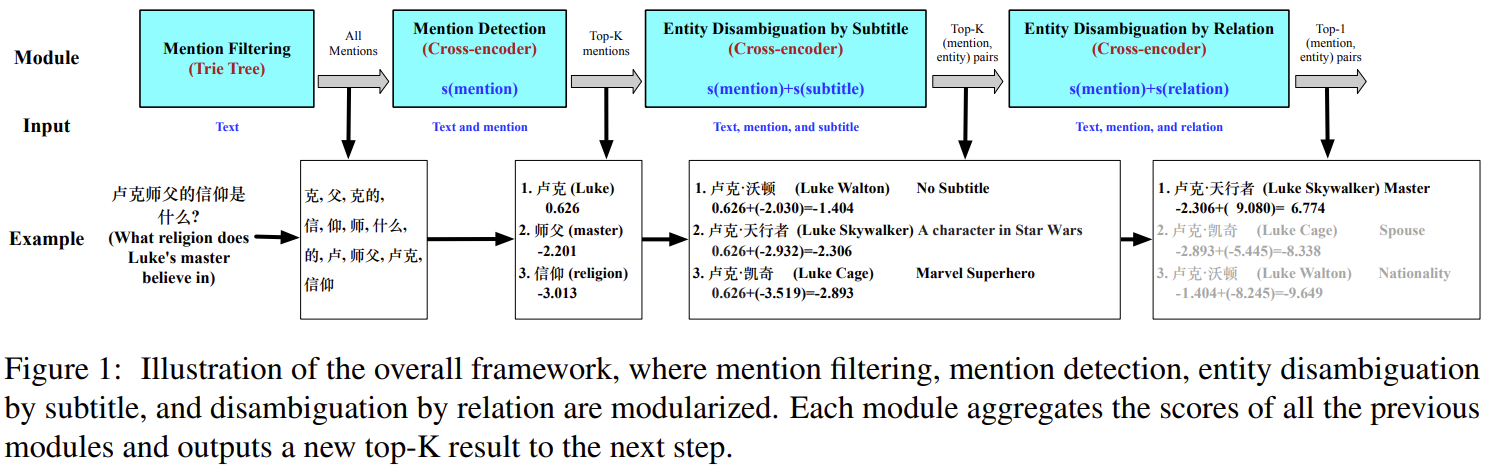
该方法具体可以分为四个部分组成:提及过滤、提及检测、通过小标题实体消岐、通过关系实体消岐。
提及过滤
通过使用字典树来获得所有可能的提及(这些提及是通过使用的标题和别名进行收集)。对于提及内容与实体名称或别名不完全相同的数据集,用户可以将此Trie树更改为其他更合适的方法,如bi-encoder(Zhang et al., 2021c)。
提及检测
提及检测从上一步返回的所有可能提及中确定最重要的提及数。将文本d和分别和每一个提及m进行拼接:\(d;[SEP]m_{i}\),然后输入到MacBert中,然后对模型输出的CLS向量执行MLP(多层感知机)操作,最终使用概率的对数作为实体的分数,并输出top-k个提及及分数传递给下一步。
实体消岐
根据属性进行消岐
实体消除歧义是为检测到的提及从知识库中寻找正确的实体。为了消除实体候选的歧义,我们以相同的方式将输入文本和提及与每种类型的属性独立匹配。例如,对于一个给定的文本d,提及\(m_{i}\),属性类型t,我们首先拼接得到:\(d;[SEP];m_{i};a_{ij}^{t}\)(\(a_{ij}^{t}\)表示类型t的第j个属性),然后将其拼接输入到MacBert中。同样CLS后接一个MLP。最终对于给定的文本d和第i个提及\(m_{i}\),我们可以得到属性\(a_{ij}^{t}\)的概率。我们对概率取对数,并从所有的属性中取最大的分数。这里不好理解,举个例子:
文本:卢克师⽗的信仰是什么?
提及过滤:
输入:卢克师⽗的信仰是什么?
中间层:Trie字典树
输出:克, ⽗, 克的, 信, 仰, 师, 什么, 的, 卢, 师⽗, 卢克, 信仰
提及检测:
输入:(前面都加了一个是)
[CLS]卢克师⽗的信仰是什么?[SEP]是卢克[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]是卢[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]是克的[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]是的[SEP]
标签:0
中间层:MacBert-取出CLS-MLP-获得概率对数
输出:卢克
属性实体消岐:
输入:
[CLS]卢克师⽗的信仰是什么?[SEP]卢克是A character in Star Wars[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]卢克是Marvel Superhero[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]卢克是xxx[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]卢克是xxxx[SEP]
标签:0
中间层:MacBert-取出CLS-MLP-获得概率对数
输出:卢克.天行者
我们返回top-K排名(提到,实体)对到下一步。(注意到训练策略中描述的是实例需要包括输入文本和四个候选提及,其中一个被标记为ground truth)
根据关系进行消岐
这里论文应该漏了这一部分。和属性实体消岐其实差不多。举个例子:
关系实体消岐:
输入:
[CLS]卢克师⽗的信仰是什么?[SEP]卢克的是师父[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]卢克的是x[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]卢克的是xx[SEP]
[CLS]卢克师⽗的信仰是什么?[SEP]卢克的是xxx[SEP]
标签:0
中间层:MacBert-取出CLS-MLP-获得概率对数
输出:卢克.天行者
需要注意,分数是累加的。
这里看下数据处理代码:
# coding=utf-8
from pprint import pprint
#
example = {
"sentence": "《白蛇》中的女性舞蹈家孙丽坤因编演舞剧《白蛇传》倾倒众生,也因其出色的才貌与风流人生在“文化大革命”中获罪,由“天上人间”自由来去的“白娘子”沦落为连上厕所都被严格看守的阶下囚,成为众人唾弃的“反革命美女蛇”,落难后的孙丽坤与一个从小就迷恋她的“假小子”舞迷徐群珊在窗内与窗外的偶遇,引发了一段特殊历史时期爱恨纠葛的传奇故事",
"mention": "", "target0": "一个", "target1": "遇", "target2": "恋她", "target3": "白蛇",
"Label": 3}
# example = {"sentence":"《angel kiss》是一款ios系统手机游戏,操作简单,卡牌丰富","mention":"angel","target0":"Leona Lewis的歌曲","target1":"著名企业企宣","target2":"Sarah McLachlan歌曲","target3":"天使之吻—— IOS游戏","Label":3}
# exmaple = {"sentence": "冯慧专业是什么方向?", "Label": 0, "mention": "冯慧的", "target0": "专业方向", "target1": "出生日期", "target2": "职称", "target3": "中文名"}
first_sentences = [example["sentence"]]*4
question_header = example["mention"]+"是"
ending_names = ["target0","target1","target2","target3"]
second_sentences = [question_header+example[end] for end in ending_names]
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('xxx', use_fast=True)
tokenized = tokenizer(first_sentences,second_sentences,truncation=True,max_length=128)
tokenized['label'] = example['label']
pprint(tokenized)
训练策略
训练数据按照多项选择题答案的设定进行组织。
- 用于训练提及检测模型的数据实例需要包括输入文本和四个候选提及,其中一个被标记为ground truth。
- 而通过副标题等属性训练实体消歧模型时,需要包括输入文本、要链接的内容以及四个带有ground truth标签的候选副标题。
- 针对于关系的实体消岐呢?论文里没有介绍,估计和属性的实体消岐构建方法类似。
使用方法
- 随时可用的版本:是适用于需要将输入文本链接至一般中文开放域知识库的用户

- 在线演示:对于这个准备使用的版本,我们还提供了一个实时演示来观察管道中每个步骤的输出,包括提及过滤、提及检测、通过副标题消除实体歧义,以及通过关系消除歧义。此外,它还提供了可点击的链接,以进一步观察实体XLore。这对于喜欢可视化前端网页的用户来说是很有用的。

- 部分版本:部分版本是为那些有兴趣在他们的下游模型中完成EL流程的用户准备的,或者使用我们的部分版本来从XLore中检索实体候选版本,而不是整个版本。在这个场景中,我们公开了每个管道步骤,供用户根据他们的需要确定在哪里停止。例如,如果用户只想使用提及过滤、提及检测和通过字幕消除歧义,他们可以使用以下脚本:

- 容易改变版本:正如我们在图2中所说明的那样,使用实体关系等特定特性可能有利于下游任务的EL。我们为有这种需求的用户提供了一个训练脚本和一个示例模型使用实现。为了添加新的特征,HOSMEL要求用户:(1)将他们的训练数据格式化为我们的格式,(2)复制样本关系用法,并在其中重写generatePair方法来检索所需的特征。如果用户喜欢将XLore更改为其他KBs,他们只需要重建Trie树。更多的使用细节请查看开源的代码和README文档。
实验结果
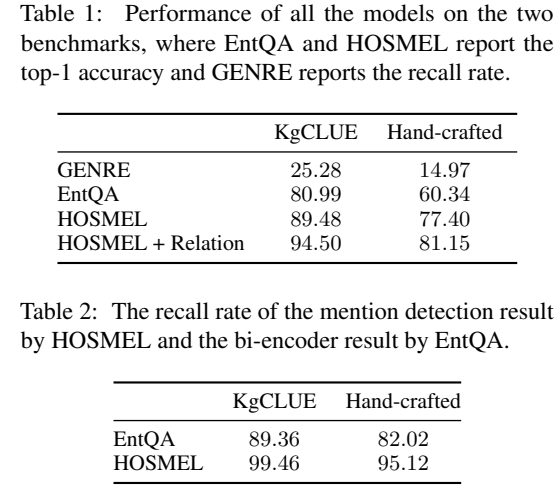
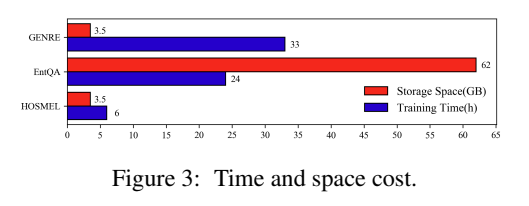
可能有部分理解有错误,具体细节还是去看看源代码。

HOSMEL:一种面向中文的可热插拔模块化实体链接工具包的更多相关文章
- 一种面向云服务的UCON多义务访问控制方法及系统
)设置每一云服务的义务项:建立每一云服务所包含的义务图:2)根据用户所请求的云服务查找该云服务的所有强制义务图和可选义务图,并提取该用户对该云服务的历史完成情况:3)对每一强制义务图,监控其每一义务项 ...
- 常见的装包的三种宝,包 bao-devel bao-utils bao-agent ,包 开发包 工具包 客户端
常见的装包的三种宝,包 bao-devel bao-utils bao-agent ,包 开发包 工具包 客户端
- 基于CBOW网络手动实现面向中文语料的word2vec
最近在工作之余学习NLP相关的知识,对word2vec的原理进行了研究.在本篇文章中,尝试使用TensorFlow自行构建.训练出一个word2vec模型,以强化学习效果,加深理解. 一.背景知识: ...
- javascript是一种面向对象语言吗?如果是,您在javascript中是如何实现继承的呢
·oop(面向对象程序设计)中最常用到的概念有 1.对象,属性,方法 1>(对象:具体事物或抽象事物,名词) 2>(属性:对象的特征,特点,形容词) 3>(方法:对象的动作,动词) ...
- 解决java种mysql中文乱码问题
乱码问题原因有多种,其中有一种是由于MySQL默认使用 ISO-8859-1 ( 即Latin1 ) 字符集,而JAVA内部使用Unicode编码,因此在JAVA中向MYSQL数据库插入数据时,或者读 ...
- 读取数据库配置信息的两种方式(以后开发项目用java链接数据库)-------java基础知识
第一步:先建立jdbc.properties user=root password url/yanlong driver=com.mysql.jdbc.Driver 第一种方式:直接文件读取 pack ...
- Java 几种调度任务的Timer、ScheduledExecutor、 开源工具包 Quartz、开源工具包 JCronTab
关于Java中的调度问题,是比较常见的问题,一直没有系统的梳理,现在梳理一下 注意:Quartz的例子 需要在特定的版本上执行,不同的版本使用方法不同,但是总的来说方法大同小异.本例子的版本是1.8 ...
- 四种方案解决ScrollView嵌套ListView问题 [复制链接]
以下文章转自@安卓泡面 在工作中,曾多次碰到ScrollView嵌套ListView的问题,网上的解决方法有很多种,但是杂而不全.我试过很多种方法,它们各有利弊. 在这里我将会从使用ScrollVie ...
- Bootstrap-datepicker3官方文档中文翻译---I18N/国际化(原文链接 http://bootstrap-datepicker.readthedocs.io/en/latest/index.html)
I18N/国际化 这个插件支持月份和星期名以及weekStart选项的国际化.默认是英语(“en”); 其他有效的译本语言在 js/locales/ 目录中, 只需在插件后包含您想要的地区. 想要添加 ...
随机推荐
- Python-安装pycocotools错误记录
安装 pycocotools 时出现错误 fatal error: Python.h: No such file or directory 解决方式 apt-get install python3.8 ...
- MySQL根据表前缀批量修改、删除表
注意:请先调试好,以及做好备份,再执行操作. 批量修改表 批量给前缀为 xushanxiang_content_ 的表增加一个 username 的字段: SELECT CONCAT('ALTER T ...
- RPA工单查询和下载流程机器人
1.登录业务系统,输入用户名和密码 2.进入下载模块 3.输入下载查询条件 4.进入文件明细单 5.下载文件 视频地址:https://www.bilibili.com/video/BV1964y1D ...
- zabbix实时监控mysql业务数据
1. 安装zabbix agent 下载zabbix:过往的软件包都有:https://sourceforge.mirrorservice.org/z/za/zabbix/ZABBIX%20Lates ...
- C++ 练气期之二维数组与矩阵运算
1. 前言 C++中的一维数组可以存储线性结构的数据,二维数组可以存储平面结构的数据.如班上所有学生的各科目成绩就有二个维度,学生姓名维度和科目成绩维度. 这样的表格数据可以使用二维数组进行存储. 当 ...
- Elasticsearch深度应用(上)
索引文档写入和近实时搜索原理 基本概念 Segments in Lucene 众所周知,Elasticsearch存储的基本单元是shard,ES种一个index可能分为多个shard,事实上每个sh ...
- 智能指针思想实践(std::unique_ptr, std::shared_ptr)
1 smart pointer 思想 个人认为smart pointer实际上就是一个对原始指针类型的一个封装类,并对外提供了-> 和 * 两种操作,使得其能够表现出原始指针的操作行为. ...
- html和css的常用语法代码详解
前端html html 超文本标记语言.文本,图片,视频,音频. 网页基本信息 一个基础的网页具有的一些信息. <!-- 这是注释--> <!--!DOCTYPE网页约束规范--&g ...
- 教你PC端网易云音乐自定义代理,VIP免费听歌!
今天分享一份福利吧,使用网易云音乐自定义代理实现免费听和下载VIP.极高音质.付费的歌曲,这里主要针对PC端电脑版的,需要自己写脚本运行. 01 安装node.js Node.js是一个让 JavaS ...
- 三万字盘点Spring/Boot的那些常用扩展点
大家好,我是三友. Spring对于每个Java后端程序员来说肯定不陌生,日常开发和面试必备的.本文就来盘点Spring/SpringBoot常见的扩展点,同时也来看看常见的开源框架是如何基于这些扩展 ...