手把手教你搭建JAVA分布式爬虫
在工作中,我们经常需要去获取一些数据,但是这些数据可能需要从第三方平台才可以获取到。这个时候,爬虫系统就可以帮助我们来完成这些事情。
提到爬虫系统,很多人都会想到使用python。但实际上,语言只是一种工具,其背后的设计思想和技术原理才是精髓,这篇关于Java分布式爬虫的文章会带着大家一步一步搭建一个适合Java开发者的爬虫系统。
第一部分:搭建一个简单的爬虫系统
现在,我们就来尝试下通过自动化方法来获取https://www.cnblogs.com/的首页内容。在正式开始编写代码之前,我们需要安装两个重要的程序,一个是chromedriver,一个是chrome。
chrome浏览器的下载地址:https://chrome.en.softonic.com/
chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
注意:在安装这两个软件的时候,它们的版本需要对应起来才能正常work。
接下来我要给大家介绍一下Selenium webdriver这个开源组件,Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。Selenium webdriver是编程语言和浏览器之间的通信工具,它的工作流程如下图所示。 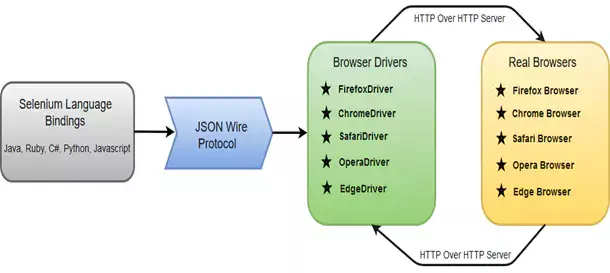
环境搭建好之后,我们就开始进入实际开发环节。首先,我们创建一个WebDriverFactory。
@Service
public class WebDriverFactory {
@Value("${chrome.path}")
private String chromePath;
@Autowired
private ProxyPool proxyPool;
public WebDriver createWebDriver(boolean useProxy) {
System.setProperty(ChromeDriverService.CHROME_DRIVER_EXE_PROPERTY, "/Users/****/Downloads/chromedriver");
ArrayList<String> arguments = Lists.newArrayList("--no-sandbox",
"--disable-dev-shm-usage",
"--disable-web-security",
"--ignore-certificate-errors",
"--allow-running-insecure-content",
"--allow-insecure-localhost",
"--disable-images",
"--disable-gpu",
"--disable-blink-features=AutomationControlled",
"--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.16 Safari/537.36",
"--cache-control=no-cache");
ChromeOptions options = new ChromeOptions();
options.setHeadless(true);
options.addArguments(arguments);
/** 设置使用代理 **/
if (useProxy) {
Proxy proxy = proxyPool.getProxy();
options.setProxy(proxy);
}
Map<String, Object> prefs = Maps.newHashMap();
prefs.put("profile.default_content_settings.popups", 1);
prefs.put("profile.default_content_setting_values.notifications", 1);
options.setExperimentalOption("prefs", prefs);
ChromeDriver webDriver = new ChromeDriver(options);
Map<String, Object> params = Maps.newHashMap();
// params.put("source", "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})");
params.put("source", "() => {" +
" if (navigator.webdriver === false) {" +
" continue" +
" } else if (navigator.webdriver === undefined) {" +
" continue" +
" } else {" +
" delete Object.getPrototypeOf(navigator).webdriver" +
" }" +
" }");
webDriver.executeCdpCommand("Page.addScriptToEvaluateOnNewDocument", params);
webDriver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS).pageLoadTimeout(20, TimeUnit.SECONDS)
.setScriptTimeout(10, TimeUnit.SECONDS);
return webDriver;
}
}上面具体到参数和配置,我们后续会进行详细解释,现在我们直接运行相关的代码获取https://www.cnblogs.com/的首页内容。
@Test
public void testGrabPage() {
WebDriver webDriver = null;
try {
String currentPageUrl = "https://xiaozhuanlan.com/";
webDriver = webDriverFactory.createWebDriver(false);
webDriver.get(currentPageUrl);
Thread.sleep(1000);
String html = webDriver.getPageSource();
System.out.println(html);
} catch (Exception e) {
e.printStackTrace();
} finally {
webDriver.quit();
}
}通过上面的代码,我们可以打印出博客园网站首页的全部信息。
第二部分:模拟用户行为
在上一个部分中,我们可以获取到“博客园”首页的完整内容,在这一篇文章中我们将实现在百度网站自动化搜索“博客园“,并且跳转到“博客园”首页。
在实现模拟登录之前,我们需要掌握如何定位到自己关心的元素。Selenium中有8种方法可以定位到元素。具体的定位方法可以查看org.openqa.selenium.By这个类。假设我们现在需要定位到如下一个元素:
<tagName attributeName='attributeValue'></tagName>那么我们可以根据以下的方法进行定位:
- driver.findElement(By.name("attributeName"),根据元素的属性名称进行定位
- driver.findElement(By.tagName("tagName"),根据元素的名称来进行定位
- driver.findElement(By.xpath("tagName[@attributeName='attributeValue']")),根据元素的xpath表达式来进行定位
- driver.findElement(By.cssSelector("tagName[attributeName='attributeValue']")),根据元素的CSS选择器来进行定位
上述介绍的元素定位方法如果发现有多个元素可以匹配的,则会选择该页面中第一个符合条件的元素。
接下来,我们编写模拟用户搜索“博客园”行为的代码,
@Test
public void searchTest() {
FenbiChromeDriver webDriver = null;
try {
webDriver = (FenbiChromeDriver) webDriverFactory.createWebDriver(false);
String currentPageURL = "http://www.baidu.com";
webDriver.get(currentPageURL);
Thread.sleep(2000);
WebElement searchInputElem = webDriver.findElement(By.xpath("//*[@id=\"kw\"]"));
searchInputElem.sendKeys("博客园");
WebElement searchButtonElem = webDriver.findElement(By.xpath("//*[@id=\"su\"]"));
searchButtonElem.click();
Thread.sleep(2000);
WebElement searchResultList = webDriver.findElement(By.xpath("//*[@id=\"content_left\"]"));
WebElement xiaozhuanlanElem = searchResultList.findElement(By.xpath("//*[@id=\"1\"]/div/div[1]/h3/a"));
xiaozhuanlanElem.click();
Thread.sleep(2000);
System.out.println(webDriver.getPageSource());
} catch (Exception e) {
e.printStackTrace();
} finally {
webDriver.quit();
}
}结合上一部分中的WebDriverFactory,并运行上面的代码,我们就可以自动跳转到博客园网站的首页了。
第三部分:判断元素是否加载完毕
当我们需要判断我们关注的元素是否加载完毕的时候,在Selenium框架下有隐式等待和显式等待两种方式。
隐式等待是在创建webdriver的时候设置的超时时间,在整个的webdriver生命周期内都是有效的。设置了隐式等待后,Selenium在执行findElement的DriverCommand时候会一直等待,直到获取到对应的元素。设置隐式等待的方法如下:
webDriver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS)
.pageLoadTimeout(20, TimeUnit.SECONDS)
.setScriptTimeout(10, TimeUnit.SECONDS);
webDriver.findElement(By.xpath("//*[@id=\"kwddddd\"]"));接下来,我们跟随Selenium的隐式等待模式来看看Selenium抓取网页的处理流程是什么样的。
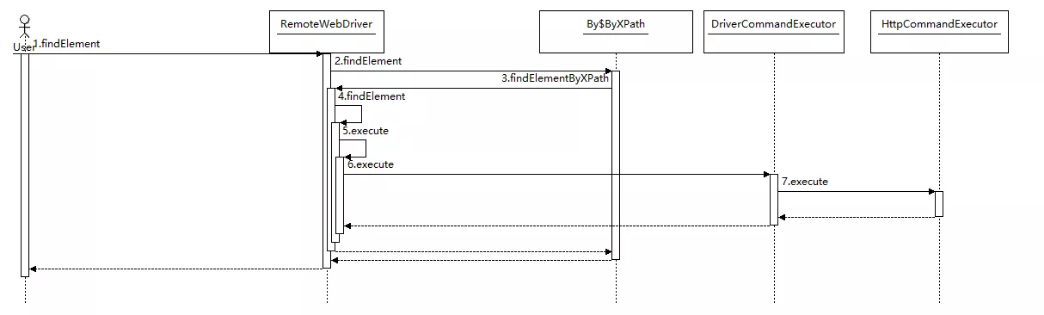
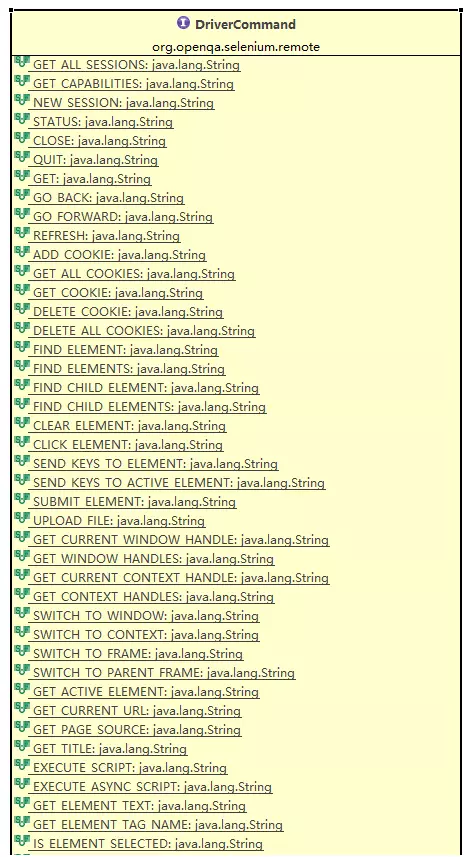
从上面的处理时序图我们可以看出,Selenium与webdriver的交互主要是通过RemoteWebDriver,DriverCommandExecutor和HttpCommandExecutor这三个类来完成的。另外一个比较重要的interface是DriverCommand,这个接口里面列举了webdriver支持的所有命令。
显示等待是使用WebDriverWait通过不断轮询的方式来完成的,示例代码如下所示,
@Test
public void webDriverWaitTest() {
FenbiChromeDriver webDriver = null;
try {
webDriver = (FenbiChromeDriver) webDriverFactory.createWebDriver(false);
new WebDriverWait(webDriver, 20).until((Function<WebDriver, Boolean>) driver -> {
String currentPageURL = "http://www.baidu.com";
driver.get(currentPageURL);
String html = driver.getPageSource();
if(html.contains("hello word")) {
return true;
} else {
return false;
}
});
} catch (Exception e) {
e.printStackTrace();
} finally {
webDriver.quit();
}
}显示等待的处理逻辑主要是在FluentWait类中的until方法中来完成的,默认情况下until方法会每隔500ms去执行Function实现类中的逻辑,检查执行结果是否为True,如果为True,则返回。如果为False,则sleep 500ms,直到结果为True,或者直到超时。

上面until方法的参数比较有意思,它需要是Function接口的实现类,范型接口Function<F, T>是google公司的开源组件Guava中的一个接口。这个接口只有一个内部方法apply,其中的F是apply方法的输入参数,T是apply方法的返回值。通过Function接口,Selenium就为WebDriverWait提供了一个很好的扩展点。我们在日常的开发中也可以借鉴这样的开发方法。
好了,今天就先和大家聊到这里吧,一个完善的爬虫还有很多其他的处理逻辑需要添加和处理。例如:如何应对反爬虫机制,如何实现用户的自动登录,如何对页面进行截图等等。感兴趣的小伙伴儿可以加我们的技术交流群或者加我的微信。


手把手教你搭建JAVA分布式爬虫的更多相关文章
- 手把手教你搭建Pytest+Allure2.X环境详细教程,生成让你一见钟情的测试报告(非常详细,非常实用)
简介 宏哥之前在做接口自动化的时候,用的测试报告是HTMLTestRunner,虽说自定义模板后能满足基本诉求,但是仍显得不够档次,高端,大气,遂想用其他优秀的report框架替换之.一次偶然的机会, ...
- 手把手教你搭建FastDFS集群(上)
手把手教你搭建FastDFS集群(上) 本文链接:https://blog.csdn.net/u012453843/article/details/68957209 FastDFS是一个 ...
- 手把手教你搭建SSH框架(Eclipse版)
原文来自公众号[C you again],若需下载完整源码,请在公众号后台回复"ssh". 本期文章详细讲解了SSH(Spring+SpringMVC+Hibernate)框架的搭 ...
- 庐山真面目之十一微服务架构手把手教你搭建基于Jenkins的企业级CI/CD环境
庐山真面目之十一微服务架构手把手教你搭建基于Jenkins的企业级CI/CD环境 一.介绍 说起微服务架构来,有一个环节是少不了的,那就是CI/CD持续集成的环境.当然,搭建CI/CD环境的工具很多, ...
- 手把手教你写电商爬虫-第三课 实战尚妆网AJAX请求处理和内容提取
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 看完两篇,相信大家已经从开始的 ...
- 手把手教你写电商爬虫-第四课 淘宝网商品爬虫自动JS渲染
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 手把手教你写电商爬虫-第三课 ...
- 大数据江湖之即席查询与分析(下篇)--手把手教你搭建即席查询与分析Demo
上篇小弟分享了几个“即席查询与分析”的典型案例,引起了不少共鸣,好多小伙伴迫不及待地追问我们:说好的“手把手教你搭建即席查询与分析Demo”啥时候能出?说到就得做到,差啥不能差人品,本篇只分享技术干货 ...
- Java分布式爬虫Nutch教程——导入Nutch工程,执行完整爬取
Java分布式爬虫Nutch教程--导入Nutch工程,执行完整爬取 by briefcopy · Published 2016年4月25日 · Updated 2016年12月11日 在使用本教程之 ...
- 手把手教你搭建FastDFS集群(下)
手把手教你搭建FastDFS集群(下) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u0 ...
随机推荐
- 开发工具-Typora编辑器下载地址
更新记录 2022年6月10日 完善标题. 比较好用的Markdown编辑器了,哈哈. https://typoraio.cn/
- 如何优雅的使用MyBatis?
本文目录 什么是 MyBatis ? 映射器(mappers) typeAliases 类型别名减少类完全限制名的冗余 处理枚举类型 多行插入 重用 SQL 代码段,消除重复 字符串替换#{}和${ ...
- ruoyi接口权限校验
此文章属于ruoyi项目实战系列 ruoyi系统在前端主要通过权限字符包含与否来动态显示目录和按钮.为了防止通过http请求绕过权限限制,后端接口也需要进行相关权限设计. @PreAuthorize使 ...
- 使用dnSpy对无源码EXE或DLL进行反编译并且修改
背景 总有一些特殊情况,我们没有源码,但是某个C#程序集dll或者可执行程序exe影响到我们代码的正常运行,我们希望得到源码,能改掉或者修改某些bug,但是苦于没有源码,这个时候可以用dnspy进行源 ...
- Codeforces Round #780 (Div. 3)
A. Vasya and Coins 题目链接 题目大意 Vasya 有 a 个 1-burle coin,有 b 个 2-burle coin,问他不能通过不找钱支付的价格的最小值. 思路 如果 a ...
- CF141E Clearing Up 题解
思路分析 自认为是一道很好的思维题. 直接看上去的想法是: 跑一个生成树,每一次加的边颜色交替进行,直到拉出生成树. 仔细想想,发现可能无法保证最后是一棵树而不是森林,也是说输出都是 \(-1\) . ...
- 『现学现忘』Git后悔药 — 29、版本回退git reset --mixed命令说明
git reset --mixed commit-id命令:回退到指定版本.(mixed:混合的,即:中等回退.) 该命令不仅修改了分支中HEAD指针的位置,还将暂存区中数据也回退到了指定版本. 但是 ...
- WannaRen来袭:螣龙安科带你盘点那些年的勒索病毒
2020年4月7日,360CERT监测发现网络上出现一款新型勒索病毒wannaRen,该勒索病毒会加密windows系统中几乎所有的文件,并且以.WannaRen作为后缀.360CERT该事件评定:危 ...
- java自定义注解实现执行所有要测试的接口
/* * 注解类 * */ @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface Demo ...
- Linux 无法启动vmmon的问题[主要出现于Arch系]
Vmmon module not loaded 使用如下命令加载模块 # modprobe -a vmw_vmci vmmon 可能会出现modprobe: WARNING: Module vmmon ...